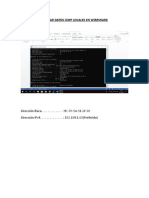
También podría gustarte
- Ley 2088 de 2021Documento5 páginasLey 2088 de 2021andresAún no hay calificaciones
- AA3. Evidencia de Conocimiento: Evidencia 1: Estudio de Caso AA3.Documento3 páginasAA3. Evidencia de Conocimiento: Evidencia 1: Estudio de Caso AA3.Luis Ibarguen MosqueraAún no hay calificaciones
- Evidencia 2: Estudio de Caso AA4Documento2 páginasEvidencia 2: Estudio de Caso AA4Luis Ibarguen MosqueraAún no hay calificaciones
- Hallazgos de AuditoriaDocumento1 páginaHallazgos de AuditoriaLuis Ibarguen MosqueraAún no hay calificaciones
- Induccion y EntrenamientoDocumento3 páginasInduccion y EntrenamientoLuis Ibarguen MosqueraAún no hay calificaciones
- El Clima Una Herramienta para La GestionDocumento12 páginasEl Clima Una Herramienta para La GestionLuis Ibarguen MosqueraAún no hay calificaciones
- CV PDFDocumento1 páginaCV PDFLuis Ibarguen MosqueraAún no hay calificaciones
- Resumen Organizaciones SaludablesDocumento3 páginasResumen Organizaciones SaludablesLuis Ibarguen MosqueraAún no hay calificaciones
- g06 PDC-firewalllDocumento17 páginasg06 PDC-firewalllLuis Ibarguen MosqueraAún no hay calificaciones
- Factor Humano EmpresaDocumento11 páginasFactor Humano EmpresaLuis Ibarguen MosqueraAún no hay calificaciones
- 62WZ1 Tallern 1 Docx Tex PDFDocumento19 páginas62WZ1 Tallern 1 Docx Tex PDFLuis Ibarguen MosqueraAún no hay calificaciones
- Riesgos NosotrosDocumento3 páginasRiesgos NosotrosLuis Ibarguen MosqueraAún no hay calificaciones
- FORO3Documento1 páginaFORO3hassanjarabaAún no hay calificaciones
- Tabla Unificadas Base GravableDocumento1514 páginasTabla Unificadas Base GravableLuis Ibarguen MosqueraAún no hay calificaciones
- METODOSDocumento10 páginasMETODOSLuis Ibarguen MosqueraAún no hay calificaciones
- Informe Procedimiento para El Recibo y Despacho de ObjetosDocumento12 páginasInforme Procedimiento para El Recibo y Despacho de ObjetosLuis Ibarguen MosqueraAún no hay calificaciones
- Auditoría FinancieraDocumento18 páginasAuditoría FinancieraLuis Ibarguen MosqueraAún no hay calificaciones
- Estructura de Desglose de TrabajoDocumento5 páginasEstructura de Desglose de TrabajoLuis Ibarguen MosqueraAún no hay calificaciones
- Numeros PseudoaleatoriosDocumento3 páginasNumeros PseudoaleatoriosHilary JacksonAún no hay calificaciones
- 11 2 Modelo ContratasDocumento24 páginas11 2 Modelo ContratasMiguel NoboaAún no hay calificaciones
- Diagrama de PertDocumento20 páginasDiagrama de PertLuis Ibarguen MosqueraAún no hay calificaciones
- Tercer Taller 2019 - IDocumento1 páginaTercer Taller 2019 - ILuis Ibarguen MosqueraAún no hay calificaciones
- Ar - Pr.administracion de RequerimientosDocumento16 páginasAr - Pr.administracion de RequerimientosLuis Ibarguen MosqueraAún no hay calificaciones
- Capturar y Analizar Datos Icmp Locales en WiresharkDocumento7 páginasCapturar y Analizar Datos Icmp Locales en WiresharkLuis Ibarguen MosqueraAún no hay calificaciones
- AnalisisvariabilidadtempprecDocumento1 páginaAnalisisvariabilidadtempprecLuis Ibarguen MosqueraAún no hay calificaciones
- Modelo EvolutivoDocumento5 páginasModelo EvolutivoLuis Ibarguen MosqueraAún no hay calificaciones
- Documento FinalDocumento2 páginasDocumento FinalLuis Ibarguen MosqueraAún no hay calificaciones
- Texto argumentativo-IPS SALUDDocumento3 páginasTexto argumentativo-IPS SALUDLuis Ibarguen MosqueraAún no hay calificaciones
- Estándar IsoDocumento2 páginasEstándar IsoLuis Ibarguen MosqueraAún no hay calificaciones
- Actividad OdooDocumento1 páginaActividad OdooLuis Ibarguen MosqueraAún no hay calificaciones
- Análisis de Fourier Usando MatlabDocumento35 páginasAnálisis de Fourier Usando MatlabAndres GaleanoAún no hay calificaciones
- Tipos de Estrategias en Relación Con El MantenimeintoDocumento24 páginasTipos de Estrategias en Relación Con El MantenimeintoJorge Alejandro Sandoval Vega67% (3)
- Clase de Pert y CPMDocumento39 páginasClase de Pert y CPMAldemar Barrera BolañoAún no hay calificaciones
- Capitulo 2Documento22 páginasCapitulo 2Anonymous J5T1RpfAún no hay calificaciones
- Diseño de Estructuras MetalicasDocumento2 páginasDiseño de Estructuras MetalicasJuan LuevanoAún no hay calificaciones
- Moodle Vs DokeosDocumento8 páginasMoodle Vs DokeosNatix RobertsAún no hay calificaciones
- Lenguajes de ProgramacionDocumento8 páginasLenguajes de ProgramacionSubaru medinaAún no hay calificaciones
- CV IlanDocumento5 páginasCV IlanIlán Antoni Horna GomezAún no hay calificaciones
- 1.instrucciones de Solicitud de Convalidaciones 2015-16Documento9 páginas1.instrucciones de Solicitud de Convalidaciones 2015-16AfoldoAún no hay calificaciones
- Codigos Cruz Roja Ecuatoriana PDFDocumento9 páginasCodigos Cruz Roja Ecuatoriana PDFEduardo Sebastián Nacimba80% (5)
- 5 AutentificacionDocumento2 páginas5 AutentificacionHugo Mixer B SAún no hay calificaciones
- Citar Un Diccionario en Formato APADocumento13 páginasCitar Un Diccionario en Formato APASneyder Alcántara100% (1)
- Perfil de Proyecto AnalisisDocumento34 páginasPerfil de Proyecto AnalisisOscar Emir VelardeAún no hay calificaciones
- Diseno CLDocumento20 páginasDiseno CLLuis Castro Aguilar100% (1)
- 10 reglas para presentaciones PowerPoint exitosasDocumento3 páginas10 reglas para presentaciones PowerPoint exitosasJCarlos Santiago100% (1)
- 10 V Tarea AccessDocumento4 páginas10 V Tarea AccessBeth BMAún no hay calificaciones
- Actividad de Semana 1Documento3 páginasActividad de Semana 1MaylethReyesAún no hay calificaciones
- Tema2 Desarrollo de La MetodologiaDocumento6 páginasTema2 Desarrollo de La MetodologiaAlex SorequeAún no hay calificaciones
- Método ReaDocumento5 páginasMétodo ReaRenato Ambuludi Hualpa100% (1)
- 995 IRA Colectiva 2019Documento2 páginas995 IRA Colectiva 2019Wilton Coy50% (2)
- EstadísticaDocumento6 páginasEstadísticarichard cuelloAún no hay calificaciones
- Placa H61Documento4 páginasPlaca H61Андрей ДругAún no hay calificaciones
- Guía de Instalación Fedora 11Documento294 páginasGuía de Instalación Fedora 11Layoto CentinelaAún no hay calificaciones
- Material Rap 2Documento19 páginasMaterial Rap 2kevinn2010Aún no hay calificaciones
- Análisis estructural con el método de la viga conjugadaDocumento22 páginasAnálisis estructural con el método de la viga conjugadaangeldazapAún no hay calificaciones
- Formula Polinomica Tesis PDFDocumento104 páginasFormula Polinomica Tesis PDFwilfredocondorimamanAún no hay calificaciones
- Blogger y Google Drive Hojas de CálculoDocumento6 páginasBlogger y Google Drive Hojas de Cálculojean marcoAún no hay calificaciones
- Modelo Conceptual de Una OrganizaciónDocumento5 páginasModelo Conceptual de Una OrganizaciónMassiel Cardenas Bustamante100% (2)
- Configuración de Quagga en LinuxDocumento3 páginasConfiguración de Quagga en Linuxjhperez.itAún no hay calificaciones
- Cuál Es La Diferencia Entre Un Help Desk y Un Service DeskDocumento2 páginasCuál Es La Diferencia Entre Un Help Desk y Un Service DeskElver Vilchez EliasAún no hay calificaciones