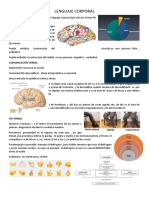
También podría gustarte
- Archivo Accidentes MaritimosDocumento70 páginasArchivo Accidentes MaritimosSilviaCuevaAún no hay calificaciones
- Bases Biológicas de La MemoriaDocumento6 páginasBases Biológicas de La MemoriaAnael Colmenares100% (2)
- Galatas Cap. 4Documento6 páginasGalatas Cap. 4Luis QuispeAún no hay calificaciones
- Historia de La OrtobiologíaDocumento11 páginasHistoria de La OrtobiologíaEVELYN YUQUILEMA100% (1)
- Machine LearnigDocumento23 páginasMachine LearnigBRYAN IVAN RODRIGUEZ REYESAún no hay calificaciones
- BryanRodriguez DependenciaFuncionalDocumento2 páginasBryanRodriguez DependenciaFuncionalBRYAN IVAN RODRIGUEZ REYESAún no hay calificaciones
- Practica IA2 Regresiones MultiplesDocumento1 páginaPractica IA2 Regresiones MultiplesBRYAN IVAN RODRIGUEZ REYESAún no hay calificaciones
- Grupo#3 - Taller PMI y PMBOKDocumento16 páginasGrupo#3 - Taller PMI y PMBOKBRYAN IVAN RODRIGUEZ REYESAún no hay calificaciones
- Letras de CancionesDocumento5 páginasLetras de CancionesBRYAN IVAN RODRIGUEZ REYESAún no hay calificaciones
- Tarea 6y 7 Psicologia EducativaDocumento10 páginasTarea 6y 7 Psicologia Educativayokasta payanoAún no hay calificaciones
- 3era Fase Clase 1Documento9 páginas3era Fase Clase 1GabrielaAún no hay calificaciones
- Critica de La Razon Pura. TeoriaDocumento2 páginasCritica de La Razon Pura. TeoriaRomulo ManriqueAún no hay calificaciones
- Los Refugiados Del BosqueDocumento3 páginasLos Refugiados Del BosqueMery OroscoAún no hay calificaciones
- Yaez FelixALEnfermedadFibroqusticadelamamaDocumento2 páginasYaez FelixALEnfermedadFibroqusticadelamamaAngelaAún no hay calificaciones
- 06 CUA FyQ 1BCH 1Documento3 páginas06 CUA FyQ 1BCH 1ANDRÉS TEMESAún no hay calificaciones
- Mapa MentalDocumento2 páginasMapa MentalJorge Turbi LachapelAún no hay calificaciones
- P4-HMyT FI UNAMDocumento7 páginasP4-HMyT FI UNAMCarlos RincónAún no hay calificaciones
- Actividad No.1. Derecho Laboral IIDocumento4 páginasActividad No.1. Derecho Laboral IIIndhira Acosta100% (1)
- Catalogo de Cuentas HotelDocumento4 páginasCatalogo de Cuentas HotelJuan OreaAún no hay calificaciones
- Resolucion 70-2020 Prorroga Vigencia Documentos Papel 31-12-2020Documento2 páginasResolucion 70-2020 Prorroga Vigencia Documentos Papel 31-12-2020Roberto Andrés Flores CastroAún no hay calificaciones
- MedicinaDocumento3 páginasMedicinaJuan PabloAún no hay calificaciones
- Tarea 4 - 40004 - 101Documento7 páginasTarea 4 - 40004 - 101Rosa MillanAún no hay calificaciones
- Subsidio - Solemnidad Del Sagrado Corazón de JesúsDocumento20 páginasSubsidio - Solemnidad Del Sagrado Corazón de JesúsjesusbladAún no hay calificaciones
- Sabado Santo en FamiliaDocumento9 páginasSabado Santo en FamiliaManuela Marín castañoAún no hay calificaciones
- Unidad 3 VejezDocumento6 páginasUnidad 3 Vejezjose colinaAún no hay calificaciones
- ROTALIGN Ultra Is El Sistema de Alineación InteligenteDocumento9 páginasROTALIGN Ultra Is El Sistema de Alineación InteligenteJose VivancoAún no hay calificaciones
- Unidad3 Actividad3.2 Campos Mata Pablo AlfonsoDocumento7 páginasUnidad3 Actividad3.2 Campos Mata Pablo AlfonsoPABLO ALFONSO CAMPOS MATAAún no hay calificaciones
- Redes de Computadoras - Natalia OliferDocumento3 páginasRedes de Computadoras - Natalia OliferchatopradaAún no hay calificaciones
- Vasiliadis - El Origen de La Lengua HelénicaDocumento6 páginasVasiliadis - El Origen de La Lengua HelénicaManu MartinAún no hay calificaciones
- Cuadro Comparativo ModelosDocumento8 páginasCuadro Comparativo ModelosSALMA NAOMI SANTIAGO ZACARIASAún no hay calificaciones
- Operaciones Con Números RealesDocumento6 páginasOperaciones Con Números RealesYuri AlejandroAún no hay calificaciones
- Caries Dental Esi 2Documento6 páginasCaries Dental Esi 2cesarjulius001Aún no hay calificaciones
- Terreno Pumpac 1Documento8 páginasTerreno Pumpac 1Yoselin Liriòn ObregònAún no hay calificaciones
- Osneidy LeónDocumento119 páginasOsneidy Leóntoqui123Aún no hay calificaciones
- Plan de InvestigaciónDocumento30 páginasPlan de InvestigaciónLuis Emilio Vasquez DionicioAún no hay calificaciones