También podría gustarte
- Java 2. Curso de Programación. 4ª EdiciónDe EverandJava 2. Curso de Programación. 4ª EdiciónAún no hay calificaciones
- Visual Basic.NET Curso de Programación: Diseño de juegos de PC/ordenadorDe EverandVisual Basic.NET Curso de Programación: Diseño de juegos de PC/ordenadorCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Enciclopedia de Microsoft Visual C#.De EverandEnciclopedia de Microsoft Visual C#.Calificación: 5 de 5 estrellas5/5 (1)
- Oracle 12c Forms y Reports: Curso práctico de formaciónDe EverandOracle 12c Forms y Reports: Curso práctico de formaciónAún no hay calificaciones
- ACTIVIDAD 3 Sistemas Gestores de Bases de DatosDocumento23 páginasACTIVIDAD 3 Sistemas Gestores de Bases de Datoscamilo andres gaitan escobarAún no hay calificaciones
- DBARTISAN y SQLMANAGERDocumento10 páginasDBARTISAN y SQLMANAGERNik BuAún no hay calificaciones
- Aa 2 Roles Permisos y PerfilesDocumento28 páginasAa 2 Roles Permisos y PerfilesAlexander Morales100% (1)
- Auditoria de Base de Datos - ConceptosDocumento11 páginasAuditoria de Base de Datos - ConceptosErick Rodriguez Chiscul100% (1)
- Actividad 1 Sistemas InformaticosDocumento28 páginasActividad 1 Sistemas InformaticosJose Valentin Alvarez GarciaAún no hay calificaciones
- SCB1001-ABD Unidad 2Documento39 páginasSCB1001-ABD Unidad 2carlos lopezAún no hay calificaciones
- ApuntesDocumento227 páginasApuntesRoemer CrankyMero PompaAún no hay calificaciones
- Unidad 3 SO GestionInstalacionSeguridadDocumento43 páginasUnidad 3 SO GestionInstalacionSeguridadOmc89Aún no hay calificaciones
- Manual DatabosqueDocumento64 páginasManual DatabosqueRenzo Samuel0% (1)
- Postgres ProgrammerDocumento495 páginasPostgres Programmerprueba_2089100% (2)
- Administracion de Recursos de DatosDocumento31 páginasAdministracion de Recursos de Datosmoteo85100% (1)
- BBDDDocumento107 páginasBBDDTomás García GómezAún no hay calificaciones
- Admon. de BBDD - Uni4 Act1 - Navarro Romero Erika YamilethDocumento10 páginasAdmon. de BBDD - Uni4 Act1 - Navarro Romero Erika YamilethErika Navarro RomeroAún no hay calificaciones
- Ejercicio 1 Lab Syslog ServerDocumento44 páginasEjercicio 1 Lab Syslog ServerjorgeAún no hay calificaciones
- O.fac - Manual - SpanishDocumento41 páginasO.fac - Manual - SpanishAngel Antonio OrtizAún no hay calificaciones
- Capas de Las Entidades WebDocumento7 páginasCapas de Las Entidades WebM.C.l RICARDOAún no hay calificaciones
- MC AA1 Bases de DatosDocumento227 páginasMC AA1 Bases de DatosJazmari Niz EsguerraAún no hay calificaciones
- Módulo 1 - Visión Global Hardware y Software v1Documento43 páginasMódulo 1 - Visión Global Hardware y Software v1Álex Pérez GiménezAún no hay calificaciones
- Administración Avanzada Del Sistema Operativo GNU - Linux - Módulo3 - Administración de DatosDocumento60 páginasAdministración Avanzada Del Sistema Operativo GNU - Linux - Módulo3 - Administración de DatosPepe1949Aún no hay calificaciones
- Manual SQLDocumento101 páginasManual SQLvzramiroAún no hay calificaciones
- Análisis SITRADIG WEB v2!01!14Documento14 páginasAnálisis SITRADIG WEB v2!01!14Jc RodriguezAún no hay calificaciones
- Amazon DynamoDB 2.0Documento25 páginasAmazon DynamoDB 2.0ErikJhefersonCaquiSilvaAún no hay calificaciones
- Antologia-Final TBD PDFDocumento84 páginasAntologia-Final TBD PDFCarlos Del Angel HernandezAún no hay calificaciones
- BBDD LibroDocumento272 páginasBBDD LibroSydalv Nyhsyvokay0% (1)
- Fundamentos SQL OracleDocumento102 páginasFundamentos SQL OracleCarlos Alberto Cabrera EscamillaAún no hay calificaciones
- Asistente de Importacion de ArchivosDocumento60 páginasAsistente de Importacion de ArchivostvpapasrocasAún no hay calificaciones
- Implementación de Un Módulo de Logística en Un Sistema ERP para Una PymeDocumento39 páginasImplementación de Un Módulo de Logística en Un Sistema ERP para Una PymeEdinson AsuncionAún no hay calificaciones
- ANALISIS Y DISEÑO DE CONTENIDOS (Autoguardado)Documento168 páginasANALISIS Y DISEÑO DE CONTENIDOS (Autoguardado)Hudson AchataAún no hay calificaciones
- Manual Databosque 10-03-18Documento62 páginasManual Databosque 10-03-18villacorta_frank100% (4)
- Servidor Base de DatosDocumento32 páginasServidor Base de DatosDevaluado MikeAún no hay calificaciones
- Lineamientos BD Buenas PracticasDocumento37 páginasLineamientos BD Buenas PracticasRaframgoAún no hay calificaciones
- TDD-BRP RotaxDocumento22 páginasTDD-BRP RotaxAbril SánchezAún no hay calificaciones
- Administración de Sistemas 06 07Documento151 páginasAdministración de Sistemas 06 07Levinor100% (1)
- Creacion de DisparadoresDocumento6 páginasCreacion de DisparadoresDONDE MARIAún no hay calificaciones
- Manual Stata BasicoDocumento79 páginasManual Stata BasicoDean TommyAún no hay calificaciones
- Manual para Presentar Reportes PDFDocumento31 páginasManual para Presentar Reportes PDFLiam RodríguezAún no hay calificaciones
- Informe Del Sistema SercomunicaDocumento22 páginasInforme Del Sistema SercomunicaMaria Del Valle CañizalezAún no hay calificaciones
- Buenas Practicas de ProgramacionDocumento14 páginasBuenas Practicas de Programacionalex2000316Aún no hay calificaciones
- 2022 05 08 09 37 50Documento74 páginas2022 05 08 09 37 50Gerardo GoyzuetaAún no hay calificaciones
- Resumen de Arquitectura de DIA ECommerce - v1Documento21 páginasResumen de Arquitectura de DIA ECommerce - v1Jose AntonioAún no hay calificaciones
- Curso-SQL-PL-SQL y Administracion Basica de OracleDocumento268 páginasCurso-SQL-PL-SQL y Administracion Basica de OracleEdward Jonatan Quispe GomezAún no hay calificaciones
- Hilos (Threads)Documento41 páginasHilos (Threads)Jeisson Celestino DominguezAún no hay calificaciones
- AA2 AdminGBDDocumento17 páginasAA2 AdminGBDEdwin ChaparroAún no hay calificaciones
- Manual de Administracion de Oracle 11g Mijahuanca Espinoza BenitoDocumento59 páginasManual de Administracion de Oracle 11g Mijahuanca Espinoza BenitoAgustin Porras EspinalAún no hay calificaciones
- Analisis Libro UnidadDocumento23 páginasAnalisis Libro UnidadDanna RoseroAún no hay calificaciones
- Integración de Datos Entre Sistemas: XML - SQLDocumento220 páginasIntegración de Datos Entre Sistemas: XML - SQLJhuniors Ramos OrtizAún no hay calificaciones
- Administración de Sistemas Gestores de Bases de Datos (2ª Edición)De EverandAdministración de Sistemas Gestores de Bases de Datos (2ª Edición)Aún no hay calificaciones
- Microsoft Visual Basic .NET. Curso de programaciónDe EverandMicrosoft Visual Basic .NET. Curso de programaciónAún no hay calificaciones
- Gestión auxiliar de archivo en soporte convencional o informático. ADGG0508De EverandGestión auxiliar de archivo en soporte convencional o informático. ADGG0508Aún no hay calificaciones
- Unidad 2 CruzCetina PaolaCristinaDocumento15 páginasUnidad 2 CruzCetina PaolaCristinaDarksoul 2703Aún no hay calificaciones
- Unidad 1 CruzCetina PaolaCristinaDocumento9 páginasUnidad 1 CruzCetina PaolaCristinaDarksoul 2703Aún no hay calificaciones
- PaolaCristina CruzCetina Unidad 5 6 6SADocumento20 páginasPaolaCristina CruzCetina Unidad 5 6 6SADarksoul 2703Aún no hay calificaciones
- PaolaCristina CruzCetina Unidad 5 6Documento19 páginasPaolaCristina CruzCetina Unidad 5 6Darksoul 2703Aún no hay calificaciones
- Ejercicios extra-clase-U4-JAFETH-GAMBOA-BAASDocumento8 páginasEjercicios extra-clase-U4-JAFETH-GAMBOA-BAASDarksoul 2703Aún no hay calificaciones
- Reporte de La Unidad 4 Jafeth Daniel Gamboa BaasDocumento4 páginasReporte de La Unidad 4 Jafeth Daniel Gamboa BaasDarksoul 2703Aún no hay calificaciones
- Reporte de La Unidad 4 Jafeth Daniel Gamboa BaasDocumento4 páginasReporte de La Unidad 4 Jafeth Daniel Gamboa BaasDarksoul 2703Aún no hay calificaciones
- Ejercicios extra-clase-U4-JAFETH-GAMBOA-BAASDocumento8 páginasEjercicios extra-clase-U4-JAFETH-GAMBOA-BAASDarksoul 2703Aún no hay calificaciones
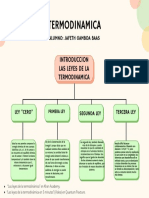
- Cuadro Sinóptico-Mapa Conceptual Unidad 4 Jafeth Gamboa BaasDocumento1 páginaCuadro Sinóptico-Mapa Conceptual Unidad 4 Jafeth Gamboa BaasDarksoul 2703Aún no hay calificaciones
- Administración de Base de Datos PostgreSQL IIDocumento13 páginasAdministración de Base de Datos PostgreSQL IImariaAún no hay calificaciones
- Tecnologías y Herramientas Utilizadas para Los Procesos de EtlDocumento6 páginasTecnologías y Herramientas Utilizadas para Los Procesos de EtlIvan Perez GAún no hay calificaciones
- Reportes Con BD SNAPSHOT SQL Server 2008Documento25 páginasReportes Con BD SNAPSHOT SQL Server 2008brykyma44100% (1)
- Sistemas de Información Geográfica y Modelado Territorial: Smart Cities Expert PerúDocumento4 páginasSistemas de Información Geográfica y Modelado Territorial: Smart Cities Expert PerúPod AD0% (1)
- Actividad Entregable Base y Estructura Datos IIDocumento6 páginasActividad Entregable Base y Estructura Datos IIPiero ManuelAún no hay calificaciones
- Servicios de Transformación de DatosDocumento16 páginasServicios de Transformación de DatosMartha GuerraAún no hay calificaciones
- Oracle (Manejo Tuning)Documento8 páginasOracle (Manejo Tuning)Stone Morales LazaroAún no hay calificaciones
- Base DatosDocumento6 páginasBase DatosNicolas SanchezAún no hay calificaciones
- Listas Enlazadas y OperacionesDocumento18 páginasListas Enlazadas y Operacioneskeljan jhonAún no hay calificaciones
- Formato Solicitud de RestauracionDocumento2 páginasFormato Solicitud de RestauracionJorge Alberto Osorio Vargas100% (1)
- Documentacion (Teoria)Documento48 páginasDocumentacion (Teoria)maximiliano espinozaAún no hay calificaciones
- Arrays Vba en Excel - Descarga de Ejemplos MacrosDocumento2 páginasArrays Vba en Excel - Descarga de Ejemplos MacrosDavid AparicioAún no hay calificaciones
- Informe Contadores Ascendentes y DescendentesDocumento15 páginasInforme Contadores Ascendentes y Descendentesempresa empresaAún no hay calificaciones
- AyED - Semestre 2-2021 - Tema 1 - Parte 3Documento20 páginasAyED - Semestre 2-2021 - Tema 1 - Parte 3Rolando GarciaAún no hay calificaciones
- Señalizacion en TelefoníaDocumento35 páginasSeñalizacion en TelefoníaHector Luis Molina VilcaAún no hay calificaciones
- Kensy HoyDocumento17 páginasKensy HoyKensy MoralesAún no hay calificaciones
- QR Balanzas WebDocumento4 páginasQR Balanzas WebKharlaSotoAún no hay calificaciones
- Silabo Georreferenciacion AplicadaDocumento6 páginasSilabo Georreferenciacion AplicadaErick Mamani VillegasAún no hay calificaciones
- Guia SQLDocumento6 páginasGuia SQLEdwin DiazAún no hay calificaciones
- Unidad 6Documento94 páginasUnidad 6Kaliid CortoiisAún no hay calificaciones
- Codigo ASCII y BinarioDocumento2 páginasCodigo ASCII y BinarioRodrigo GarciaAún no hay calificaciones
- Gestión de Archivos e Implementación de Sitemas de ArchivosDocumento16 páginasGestión de Archivos e Implementación de Sitemas de ArchivosAdrian BetancourtAún no hay calificaciones
- Sistema TeradataDocumento55 páginasSistema Teradatauniversitarioitsz100% (1)
- Solucion Laboratorio SQLDocumento16 páginasSolucion Laboratorio SQLJuan Diego LozanoAún no hay calificaciones
- Informe GeodesicoDocumento12 páginasInforme GeodesicoYashira Cortez CisnerosAún no hay calificaciones
- Guía Básica de Comandos SQLDocumento5 páginasGuía Básica de Comandos SQLMathiusTenorioAún no hay calificaciones
- Expo Beatriz LisbyDocumento3 páginasExpo Beatriz LisbybeatrizAún no hay calificaciones
- Formatear Disco DuroDocumento11 páginasFormatear Disco DuroSandra GalindoAún no hay calificaciones
- Propuesta Servicio Azure Data FactoryDocumento13 páginasPropuesta Servicio Azure Data FactoryJavier Alejandro Garzón EscalanteAún no hay calificaciones