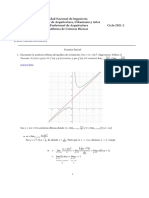
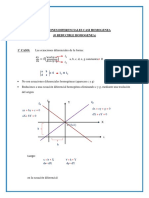
También podría gustarte
- Taller Teórico Práctico Individual 4Documento7 páginasTaller Teórico Práctico Individual 4Jose anderson Giraldo vargasAún no hay calificaciones
- Aporte - 1 - Tarea 2 - Brayan - AlvarezDocumento7 páginasAporte - 1 - Tarea 2 - Brayan - AlvarezSandraAún no hay calificaciones
- Estimación Con VI y MC2EDocumento12 páginasEstimación Con VI y MC2ECristian VélezAún no hay calificaciones
- C Alculo 1: Hoja 1: FundamentosDocumento2 páginasC Alculo 1: Hoja 1: FundamentosIresolka 25Aún no hay calificaciones
- Grupos 1Documento35 páginasGrupos 1oscarhvsAún no hay calificaciones
- Regresión SimpleDocumento10 páginasRegresión Simplepamelema17Aún no hay calificaciones
- Clase 12 Multicolinealidad - UNIDocumento7 páginasClase 12 Multicolinealidad - UNICARDAún no hay calificaciones
- Tarea 1 - Oscar Aya - Con EnlaceDocumento18 páginasTarea 1 - Oscar Aya - Con EnlaceOscar Eduardo Aya MartínezAún no hay calificaciones
- Extra Calc1Documento11 páginasExtra Calc1Monserrat DamianAún no hay calificaciones
- ExamenDocumento8 páginasExamenssabugalbAún no hay calificaciones
- HeterocedasticidadDocumento21 páginasHeterocedasticidadGina RossiAún no hay calificaciones
- PC1 2020 - 2 Ed (Solucionario)Documento5 páginasPC1 2020 - 2 Ed (Solucionario)Andre BarrantesAún no hay calificaciones
- Pauta Prueba ALGEBRA 2017Documento4 páginasPauta Prueba ALGEBRA 2017medinavasquez200033Aún no hay calificaciones
- Econometría Básica (Matrices y Estimadores) Bien Explicado CompiladoDocumento49 páginasEconometría Básica (Matrices y Estimadores) Bien Explicado CompiladoBrian Philippe Tampier TapiaAún no hay calificaciones
- Capitulo 2Documento30 páginasCapitulo 2Ty JackAún no hay calificaciones
- DesigualdadesDocumento13 páginasDesigualdadesMAVIC02100% (1)
- Tarea 2Documento4 páginasTarea 2Tomas Camilo Herrera SalazarAún no hay calificaciones
- MATEMÁTICAS II - Clase 1Documento26 páginasMATEMÁTICAS II - Clase 1Sully MatomaAún no hay calificaciones
- Ficha de Actividad Sesión 27Documento4 páginasFicha de Actividad Sesión 27YHEMILIS YHASMIN BURGOS ROMEROAún no hay calificaciones
- A6 DesAvDocumento7 páginasA6 DesAvmarioAún no hay calificaciones
- Tema 2Documento43 páginasTema 2apcarmen11Aún no hay calificaciones
- Normas, Bolas y MetricasDocumento31 páginasNormas, Bolas y MetricasSalvadorAún no hay calificaciones
- Semana 15Documento36 páginasSemana 15David Contreras EspejoAún no hay calificaciones
- EcuacionesDocumento5 páginasEcuacionesAngela DeaquizAún no hay calificaciones
- Soluciones PA2Documento4 páginasSoluciones PA2Anteia B.Aún no hay calificaciones
- Ejercicio Ecuaciones Diferenciales Hallando Factor IntegranteDocumento3 páginasEjercicio Ecuaciones Diferenciales Hallando Factor IntegrantePaula Catalina Robayo TorresAún no hay calificaciones
- Programacion DUALDocumento27 páginasProgramacion DUALIris Florencia MAMANIAún no hay calificaciones
- Solucion de Ecuaciones DiferencialesDocumento20 páginasSolucion de Ecuaciones DiferencialesrafaelAún no hay calificaciones
- Face 1 Ecuaciones DiferencialesDocumento20 páginasFace 1 Ecuaciones DiferencialesDiela RuedaAún no hay calificaciones
- Examen Parcial Solucionario C Lculo Diferencial 2021 2Documento5 páginasExamen Parcial Solucionario C Lculo Diferencial 2021 2Gehanire Azcona CardenasAún no hay calificaciones
- Ejercicios de Sistemas de Ecuaciones para Quinto de SecundariaDocumento5 páginasEjercicios de Sistemas de Ecuaciones para Quinto de SecundariaCafe LecheAún no hay calificaciones
- Pauta Semana 1 PDFDocumento4 páginasPauta Semana 1 PDFangelicaAún no hay calificaciones
- Soluciones ApunteDocumento87 páginasSoluciones ApunteBruno AzolasAún no hay calificaciones
- Ejerciciosresueltoscalculoi2016 01Documento25 páginasEjerciciosresueltoscalculoi2016 01Alvaro EspinozaAún no hay calificaciones
- Regresion Lineal MultipleDocumento29 páginasRegresion Lineal MultipleMiguel PalaciosAún no hay calificaciones
- Clase 15 Ecuaciones Diferenciales Casi HomogeneasDocumento5 páginasClase 15 Ecuaciones Diferenciales Casi HomogeneasSolemns SotsAún no hay calificaciones
- Calculo Igrupo 9Documento10 páginasCalculo Igrupo 9Isaias Vargas FloresAún no hay calificaciones
- Des Igual Dad EsDocumento8 páginasDes Igual Dad EsDylan GaleasAún no hay calificaciones
- Calculo40 Ejemplos Unidad 2Documento2 páginasCalculo40 Ejemplos Unidad 2microAún no hay calificaciones
- 101 GeneratDocumento40 páginas101 GeneratLALAAún no hay calificaciones
- Algebra Tema 14 Sistema de Ecuaciones Master Peru 2022Documento4 páginasAlgebra Tema 14 Sistema de Ecuaciones Master Peru 2022jhony issac ortiz corahuaAún no hay calificaciones
- METODODEJACOBIDocumento5 páginasMETODODEJACOBIALVARO DIEGO MACHACA CONDORIAún no hay calificaciones
- Ecuaciones Lineales y Cuadráticas ExplicacionDocumento13 páginasEcuaciones Lineales y Cuadráticas Explicaciono.muriel24Aún no hay calificaciones
- Ejercicios Examenes Resueltos Tema3 1Documento4 páginasEjercicios Examenes Resueltos Tema3 1jorge.abiAún no hay calificaciones
- Polinomios de Bernoulli y Numeros de BerDocumento40 páginasPolinomios de Bernoulli y Numeros de Beralvarezdiaz_11921176Aún no hay calificaciones
- 01 - Desigualdades y Valor AbsolutoDocumento8 páginas01 - Desigualdades y Valor Absolutokakaroto19Aún no hay calificaciones
- Contenido 3Documento9 páginasContenido 3Raul RoaAún no hay calificaciones
- Ecuaciones - Con Factor ComúnDocumento4 páginasEcuaciones - Con Factor ComúnCarlos GonzalezAún no hay calificaciones
- Frisch-Waugh-LovellDocumento16 páginasFrisch-Waugh-LovellGina RossiAún no hay calificaciones
- Ecuaciones DiferencialesDocumento11 páginasEcuaciones DiferencialesEneida GutierrezAún no hay calificaciones
- Función RacionalDocumento9 páginasFunción RacionalFabián CarguaAún no hay calificaciones
- Ecuacionesdiferencialesordinarias 161023144307Documento20 páginasEcuacionesdiferencialesordinarias 161023144307EduardoAún no hay calificaciones
- Taller S2 GRUPO 1Documento7 páginasTaller S2 GRUPO 1Alejandro Camayteri CahuasaAún no hay calificaciones
- VDocumento3 páginasVgeyson sneyder uribeAún no hay calificaciones
- Hoja Guía Práctica N 1 - IntegralDocumento6 páginasHoja Guía Práctica N 1 - IntegralNaidelin Paola Calle MorochoAún no hay calificaciones
- Teoremas de Análisis MatemáticoDocumento10 páginasTeoremas de Análisis MatemáticoCésar ResinoAún no hay calificaciones
- Yvsolerp - 9 Clase (24 Ago)Documento15 páginasYvsolerp - 9 Clase (24 Ago)Omar DiazAún no hay calificaciones
- Clase Sist EcnolinealDocumento28 páginasClase Sist EcnolinealRandy ReyesAún no hay calificaciones
- Aportes LetracDocumento6 páginasAportes LetracRosman DearmasAún no hay calificaciones
- Ecuaciones Diferenciales y SeriesDocumento27 páginasEcuaciones Diferenciales y SeriesAlejandro VivarAún no hay calificaciones
- Introducción A StataDocumento16 páginasIntroducción A StataGina RossiAún no hay calificaciones
- Regresion SimpleDocumento65 páginasRegresion SimpleGina RossiAún no hay calificaciones
- Teoría Asintótica para MCODocumento18 páginasTeoría Asintótica para MCOGina RossiAún no hay calificaciones
- Problemas 23 y 24 de La Práctica 1: Teorema Central Del LímiteDocumento3 páginasProblemas 23 y 24 de La Práctica 1: Teorema Central Del LímiteGina RossiAún no hay calificaciones
- 4) Demostraciones TP1Documento6 páginas4) Demostraciones TP1Gina RossiAún no hay calificaciones
- PROGRAMADocumento12 páginasPROGRAMAGina RossiAún no hay calificaciones
- 1) Teórico ÁlgebraDocumento63 páginas1) Teórico ÁlgebraGina RossiAún no hay calificaciones
- Teoria AlgebraDocumento243 páginasTeoria AlgebraGina RossiAún no hay calificaciones
- Identidades TrigonométricasDocumento1 páginaIdentidades TrigonométricasGina RossiAún no hay calificaciones
- Fe de ErratasDocumento6 páginasFe de ErratasGina RossiAún no hay calificaciones
- 5) Demostraciones TP1 (2da Parte)Documento7 páginas5) Demostraciones TP1 (2da Parte)Gina RossiAún no hay calificaciones
- 3) Teórico-Transformaciones Lineales-Diagonalización (2da Parte)Documento25 páginas3) Teórico-Transformaciones Lineales-Diagonalización (2da Parte)Gina RossiAún no hay calificaciones
- 2) Teórico-Transformaciones Lineales (1er Parte)Documento35 páginas2) Teórico-Transformaciones Lineales (1er Parte)Gina RossiAún no hay calificaciones
- Matematica Financiera. Cissel, Cissel, Flaspohler.Documento306 páginasMatematica Financiera. Cissel, Cissel, Flaspohler.Gina RossiAún no hay calificaciones
- Tablas ActuarialesDocumento3 páginasTablas ActuarialesGina RossiAún no hay calificaciones
- Kennedy - La Evolución de La Riqueza SocialDocumento21 páginasKennedy - La Evolución de La Riqueza SocialGina RossiAún no hay calificaciones
- Williamson - Revisión Del Consenso de WashingtonDocumento15 páginasWilliamson - Revisión Del Consenso de Washingtonsantt66Aún no hay calificaciones
- NBER WORKING PAPER SERIES - En.esDocumento19 páginasNBER WORKING PAPER SERIES - En.esLucianaAún no hay calificaciones
- Diferencia Salarial Hombres-MujeresDocumento26 páginasDiferencia Salarial Hombres-MujeresRene Olivares LopezAún no hay calificaciones
- ECONOMETRICSDocumento24 páginasECONOMETRICSItziar Núñez VedoAún no hay calificaciones
- Cuestionario 1Documento18 páginasCuestionario 1Hebert Suarez CahuanaAún no hay calificaciones
- SILABO-470-ECONOMETRIA 1 (Año 2022-Ciclo A)Documento7 páginasSILABO-470-ECONOMETRIA 1 (Año 2022-Ciclo A)suarezperuAún no hay calificaciones
- Econometria 3 ParcialDocumento40 páginasEconometria 3 ParcialPatrick CAún no hay calificaciones
- Laura Atuesta Taller-De-StataDocumento22 páginasLaura Atuesta Taller-De-StataCarlos Enrique Pomalique HuancaAún no hay calificaciones
- Tema12 EconometríaDocumento10 páginasTema12 EconometríaUlisesAún no hay calificaciones
- Metodo de Inferencia Causal para La Evaluacion de Impacto 3Documento11 páginasMetodo de Inferencia Causal para La Evaluacion de Impacto 3brayan coriAún no hay calificaciones
- Learning Microeconometrics With R 0367255383 9780367255381 - Compress 3.en - EsDocumento50 páginasLearning Microeconometrics With R 0367255383 9780367255381 - Compress 3.en - EsmanuelAún no hay calificaciones
- Beck - T - Econometrics of Finance and Growth - WPS4608.en - EsDocumento45 páginasBeck - T - Econometrics of Finance and Growth - WPS4608.en - EsWilly Huarachi MendozaAún no hay calificaciones
- Modelos DinamicosDocumento18 páginasModelos Dinamicosjbm1966Aún no hay calificaciones
- EstimacionMCO MCIDocumento15 páginasEstimacionMCO MCIHenri Jose Torres GimenezAún no hay calificaciones
- El Modelo de Koyck (16V) (8) (21B) (DDC) (8) (22A)Documento37 páginasEl Modelo de Koyck (16V) (8) (21B) (DDC) (8) (22A)CASAS CASTAÑEDA MIGUEL ALBERTOAún no hay calificaciones
- 06 Modelos ARDL PDFDocumento22 páginas06 Modelos ARDL PDFGlenny Quintana Argandoña100% (1)
- Los Principales Determinantes de La Demanda de Transporte PúblicoDocumento28 páginasLos Principales Determinantes de La Demanda de Transporte PúblicoBelem CruzAún no hay calificaciones
- 2.3 Alvarado AxelDocumento2 páginas2.3 Alvarado Axelaxel alvaradoAún no hay calificaciones
- Clase10 181030022717Documento38 páginasClase10 181030022717SERGIO REQUENAAún no hay calificaciones
- Practica Carlos Alayo - 2da Unidad-Mi ParteDocumento5 páginasPractica Carlos Alayo - 2da Unidad-Mi ParteCarlos JsfAún no hay calificaciones
- Ejercicios ME PDFDocumento18 páginasEjercicios ME PDFCésar ÁngelesAún no hay calificaciones
- Solucion EmiDocumento8 páginasSolucion EmiRossyAún no hay calificaciones
- Regresores EndógenosDocumento14 páginasRegresores EndógenosPierre Chavez AlcoserAún no hay calificaciones
- Resumen 15Documento3 páginasResumen 15ElizabethAún no hay calificaciones
- Econometria PreguntasDocumento16 páginasEconometria PreguntasHéctor D. Torres AponteAún no hay calificaciones
- Evaluación4 EconometríaIDocumento3 páginasEvaluación4 EconometríaIvicente.poblete1Aún no hay calificaciones
- La Importancia de Las Prácticas PreprofesionalesDocumento3 páginasLa Importancia de Las Prácticas PreprofesionalesAnonymous ynyQqtWnfLAún no hay calificaciones
- Ramirez Et Al (2019) .En - EsDocumento27 páginasRamirez Et Al (2019) .En - EsCamilo DomínguezAún no hay calificaciones
- SamanamudDocumento16 páginasSamanamudDouglas Gabriel Palacios GarciaAún no hay calificaciones