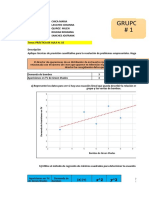
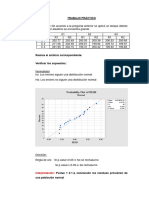
También podría gustarte
- Ejercicios ExcelDocumento20 páginasEjercicios ExcelAaron CorreaAún no hay calificaciones
- Métodos Matriciales para ingenieros con MATLABDe EverandMétodos Matriciales para ingenieros con MATLABCalificación: 5 de 5 estrellas5/5 (1)
- Resolución de Problemas de La Lectura N°1Documento25 páginasResolución de Problemas de La Lectura N°1Alvaro Valdivia100% (3)
- EVALUACION POTENCIAS 8voDocumento3 páginasEVALUACION POTENCIAS 8voLuis Amilcar GomezAún no hay calificaciones
- Auditoria CTPAT 3Documento26 páginasAuditoria CTPAT 3Adrian AlvaradoAún no hay calificaciones
- It Evaluacion Caja DireccionDocumento2 páginasIt Evaluacion Caja DireccionJose BravoAún no hay calificaciones
- Diseño Pav. Adoquines - AASHTO 93Documento16 páginasDiseño Pav. Adoquines - AASHTO 93Roner Javier Aleman TorresAún no hay calificaciones
- Informe N°1 - Disparo de Un TiristorDocumento20 páginasInforme N°1 - Disparo de Un TiristorNate River Near Vega HerreraAún no hay calificaciones
- Diseño Robusto QuilumbaquinDocumento11 páginasDiseño Robusto QuilumbaquinCesar QuilumbaquinAún no hay calificaciones
- DISEÑO DE VIGAS UltimoDocumento12 páginasDISEÑO DE VIGAS UltimoEfrain Jauregui Llanco100% (1)
- Evaluacion Final de Pavimentos 2021 - PvitbDocumento17 páginasEvaluacion Final de Pavimentos 2021 - PvitbEdwin Cerna AvilaAún no hay calificaciones
- Geometric modeling in computer: Aided geometric designDe EverandGeometric modeling in computer: Aided geometric designAún no hay calificaciones
- Diseño Pavimento Método Aashto MTCDocumento124 páginasDiseño Pavimento Método Aashto MTCLes Castillo RomeroAún no hay calificaciones
- Tabla Nº. I.1 Análisis de Varianza para Los Equipos de La Liga NacionalDocumento8 páginasTabla Nº. I.1 Análisis de Varianza para Los Equipos de La Liga Nacionaljesus lopez100% (3)
- Informe Final CypecadDocumento29 páginasInforme Final CypecadMaría AlejandraAún no hay calificaciones
- Pautas Guías Tópicos en RDocumento63 páginasPautas Guías Tópicos en RBrian Philippe Tampier Tapia100% (1)
- PD9 - 15 03 23Documento25 páginasPD9 - 15 03 23Jose Alfredo Ramirez RodriguezAún no hay calificaciones
- Prob 6 22Documento2 páginasProb 6 22ALCIDES LUIS FABIAN BRA�EZAún no hay calificaciones
- Estadistica PracticoDocumento7 páginasEstadistica Practicolaura lopezAún no hay calificaciones
- Práctica 1Documento15 páginasPráctica 1RRHH-ParqueEternoAún no hay calificaciones
- Guia Pad Preparatoria-51-52Documento2 páginasGuia Pad Preparatoria-51-52ernesto.sanchez.castroAún no hay calificaciones
- Estadistica Ii - Con Lenguaje RDocumento10 páginasEstadistica Ii - Con Lenguaje RRicardo RaldeAún no hay calificaciones
- Soluciones Walpole 1Documento9 páginasSoluciones Walpole 1As Ru4Aún no hay calificaciones
- UntitledDocumento26 páginasUntitledAlberto Cabrera AlanyaAún no hay calificaciones
- Diseño en Bloques Completos Al Azar Dbca Con RDocumento8 páginasDiseño en Bloques Completos Al Azar Dbca Con RfermadAún no hay calificaciones
- Tablas de AASHTO 1993-6Documento33 páginasTablas de AASHTO 1993-6Juan PiedrahitaAún no hay calificaciones
- Cap 6Documento36 páginasCap 6Carlos Venegas0% (1)
- HT Arq S01Documento2 páginasHT Arq S01Lisbet Carpa XDAún no hay calificaciones
- Ejercicios-Investigacion OperativaDocumento10 páginasEjercicios-Investigacion OperativaLeonel Cabrera GomezAún no hay calificaciones
- Ejercicio de SalsasDocumento7 páginasEjercicio de SalsasBeto RojasAún no hay calificaciones
- Guía RDocumento23 páginasGuía RJavier SaavedraAún no hay calificaciones
- INSTRUMENTO DE EVAL QUIMESTRAL 9noDocumento7 páginasINSTRUMENTO DE EVAL QUIMESTRAL 9noAndrea XimenaAún no hay calificaciones
- Graficos 2D: MatlabDocumento6 páginasGraficos 2D: MatlabDanny Daniel Aguilar PalominoAún no hay calificaciones
- Laboratorio 2Documento7 páginasLaboratorio 2Carlos Vicente Quiche ChiyalAún no hay calificaciones
- Ecuacion Explicita Calculo FriccionDocumento11 páginasEcuacion Explicita Calculo FriccionbravoalfadeltaAún no hay calificaciones
- Clase 3 Coma FlotanteDocumento11 páginasClase 3 Coma FlotanteDario CortesAún no hay calificaciones
- Laboratorio 01 27498934Documento11 páginasLaboratorio 01 27498934Francisco J CastilloAún no hay calificaciones
- Dca TareaDocumento5 páginasDca TareaAndrew 2560Aún no hay calificaciones
- Practica de Habilidad Operativa 2021Documento2 páginasPractica de Habilidad Operativa 2021Geovani MincholaAún no hay calificaciones
- Laboratorio Nº1 de Ingenierìa de Anàlisis MultidimensionalDocumento4 páginasLaboratorio Nº1 de Ingenierìa de Anàlisis MultidimensionalCarlos LongobardiAún no hay calificaciones
- Archivo 202311791841Documento6 páginasArchivo 202311791841María Alexandra Chica MacayAún no hay calificaciones
- Raz Ded e InductivoDocumento3 páginasRaz Ded e InductivoDelia CvAún no hay calificaciones
- Ejercicio-7 2Documento17 páginasEjercicio-7 2stefano mujica winchonlongAún no hay calificaciones
- Puntaje para Este IntentoDocumento12 páginasPuntaje para Este Intentomarlen AguirreAún no hay calificaciones
- Examen Muestra 2 2021Documento11 páginasExamen Muestra 2 2021Reyna BlessureAún no hay calificaciones
- Boletines de Problemas 20 21Documento24 páginasBoletines de Problemas 20 21gatuso123Aún no hay calificaciones
- Actividad 12 PDFDocumento18 páginasActividad 12 PDFjose martinezAún no hay calificaciones
- Soluciones Walpole 1 A 6Documento88 páginasSoluciones Walpole 1 A 6As Ru4Aún no hay calificaciones
- Examen EstadísticaDocumento5 páginasExamen EstadísticaILEN NICOLE XIOMARA CASTRO CUSIAún no hay calificaciones
- WEIBULLDocumento34 páginasWEIBULLCRISTIAN CAMILO MORALES SOLISAún no hay calificaciones
- Tecnolog - Mat. Parte III-finDocumento37 páginasTecnolog - Mat. Parte III-finMirio Arevalo BardalesAún no hay calificaciones
- Solsem12 Preposición - UnlockedDocumento110 páginasSolsem12 Preposición - UnlockedEDGARAún no hay calificaciones
- TP1 Algoritmos Generales2021 - 2cuatDocumento12 páginasTP1 Algoritmos Generales2021 - 2cuatTimoteo LangAún no hay calificaciones
- Laboratorio Ii Unidad 2Documento5 páginasLaboratorio Ii Unidad 2Gian AscoyAún no hay calificaciones
- 3CM01 Ejercicios de Demanda, Oferta y CostosDocumento8 páginas3CM01 Ejercicios de Demanda, Oferta y CostosSuriel Jesus Martinez EspinozaAún no hay calificaciones
- Tarea ListaDocumento6 páginasTarea Listapiarq STUDIOAún no hay calificaciones
- Actividad 2.01Documento9 páginasActividad 2.01Kevin Sánchez ViteAún no hay calificaciones
- R ProjectDocumento19 páginasR ProjectJuan DiegoAún no hay calificaciones
- Solsem 12Documento110 páginasSolsem 12guitarpro670Aún no hay calificaciones
- Actividades de La Unidad 3 - Christopher Palacios de LiraDocumento20 páginasActividades de La Unidad 3 - Christopher Palacios de LiraChristopher Palacios De LiraAún no hay calificaciones
- RM Semi3 2011-IiDocumento4 páginasRM Semi3 2011-Iiisis gonzalesAún no hay calificaciones
- Eliminación de líneas ocultas: Revelando lo invisible: secretos de la visión por computadoraDe EverandEliminación de líneas ocultas: Revelando lo invisible: secretos de la visión por computadoraAún no hay calificaciones
- S Sem14 Ses28 Prueba de HomogeneidadDocumento4 páginasS Sem14 Ses28 Prueba de HomogeneidadfredyAún no hay calificaciones
- Cuestionario-Impacto UrbanisticoDocumento5 páginasCuestionario-Impacto UrbanisticofredyAún no hay calificaciones
- Pasos para El Recojo de La Canasta 2022Documento3 páginasPasos para El Recojo de La Canasta 2022fredyAún no hay calificaciones
- Disponibilidad Horaria Ciclo Enero 2020Documento1 páginaDisponibilidad Horaria Ciclo Enero 2020fredyAún no hay calificaciones
- Trabajo PrácticoDocumento5 páginasTrabajo PrácticofredyAún no hay calificaciones
- P Sem14 Ses28 Prueba de HomogeneidadDocumento12 páginasP Sem14 Ses28 Prueba de HomogeneidadfredyAún no hay calificaciones
- 100000A43Q Material S10.s1Documento16 páginas100000A43Q Material S10.s1fredyAún no hay calificaciones
- 100000A43Q Material S04.s1 PDFDocumento15 páginas100000A43Q Material S04.s1 PDFfredyAún no hay calificaciones
- SILABODocumento2 páginasSILABOfredyAún no hay calificaciones
- 100000A43Q Material S03.s1Documento18 páginas100000A43Q Material S03.s1fredyAún no hay calificaciones
- Manual de Instalación SQL Server 2016Documento38 páginasManual de Instalación SQL Server 2016fredyAún no hay calificaciones
- Sistema de Evaluacion e Incentivos Docente Abril 2020Documento26 páginasSistema de Evaluacion e Incentivos Docente Abril 2020fredyAún no hay calificaciones
- CONTA - Silabo - IIC - Habilidades para El Pensamiento Lógico - 2017.1Documento4 páginasCONTA - Silabo - IIC - Habilidades para El Pensamiento Lógico - 2017.1fredyAún no hay calificaciones
- Orbegoso Aspillaga Evaluación PDFDocumento250 páginasOrbegoso Aspillaga Evaluación PDFfredyAún no hay calificaciones
- Promelac PDFDocumento1 páginaPromelac PDFfredyAún no hay calificaciones
- A02Q Sem02 Ses03 Elipse SEPARATADocumento2 páginasA02Q Sem02 Ses03 Elipse SEPARATAfredy0% (1)
- 100000CP38 EstadisticaDocumento2 páginas100000CP38 EstadisticafredyAún no hay calificaciones
- UNITEC1Documento24 páginasUNITEC1fredyAún no hay calificaciones
- Rubrica Del Trabajo Aplicado - Estadística Aplicada para Los NegociosDocumento2 páginasRubrica Del Trabajo Aplicado - Estadística Aplicada para Los NegociosfredyAún no hay calificaciones
- Inducción Corporativa - Docentes - 2019.1 PDFDocumento55 páginasInducción Corporativa - Docentes - 2019.1 PDFfredy100% (1)
- Tabla 1 - Distribución Normal Estándar PDFDocumento2 páginasTabla 1 - Distribución Normal Estándar PDFfredyAún no hay calificaciones
- Repaso EDP2Documento2 páginasRepaso EDP2fredyAún no hay calificaciones
- Ascensos 2018 - Noviembre PDFDocumento1 páginaAscensos 2018 - Noviembre PDFfredyAún no hay calificaciones
- Flujo de Caja Cafe Habas-ProyectoDocumento49 páginasFlujo de Caja Cafe Habas-ProyectofredyAún no hay calificaciones
- Bitdefender Business Security 132 Nodos Unidad Materno Infantil Del Tolima S.A.Documento2 páginasBitdefender Business Security 132 Nodos Unidad Materno Infantil Del Tolima S.A.sistemas UmitAún no hay calificaciones
- Generalidades Del Protocolo Ipv6Documento15 páginasGeneralidades Del Protocolo Ipv6SergioOspitiaRojasAún no hay calificaciones
- Introduccion A SMPPDocumento21 páginasIntroduccion A SMPPVictor Celer100% (1)
- Universidad Del Valle de Mexico: Campus QuerétaroDocumento1 páginaUniversidad Del Valle de Mexico: Campus QuerétaroAbigail Chavarin ZavalaAún no hay calificaciones
- Informe de Comandos de Ubuntu 12Documento8 páginasInforme de Comandos de Ubuntu 12Noe AbuAún no hay calificaciones
- Unidad 2 - Tarea 4 - Quiz - Cuestionario de Evaluación 1Documento3 páginasUnidad 2 - Tarea 4 - Quiz - Cuestionario de Evaluación 1ANGIE CAPERAAún no hay calificaciones
- Ejemplos Resueltos Por El Método GráficoDocumento8 páginasEjemplos Resueltos Por El Método GráficoAlex Z.Aún no hay calificaciones
- STEPHANIE ESTRADA - Tutorial de Fórmula y GráficosDocumento48 páginasSTEPHANIE ESTRADA - Tutorial de Fórmula y GráficosStephanie EstradaAún no hay calificaciones
- Encuesta Sobre El Uso de Las TicDocumento7 páginasEncuesta Sobre El Uso de Las TicSaid Suarez FloresAún no hay calificaciones
- Final Project 1P22 - Networking and CommunicationDocumento13 páginasFinal Project 1P22 - Networking and CommunicationCristian PuentesAún no hay calificaciones
- Tarea de Algoritmos.Documento7 páginasTarea de Algoritmos.La Paloma del MercadoAún no hay calificaciones
- Periférico, Unidades Basicas, Garantias, TECNOLOGIA Dany Macz ChunDocumento4 páginasPeriférico, Unidades Basicas, Garantias, TECNOLOGIA Dany Macz ChunAxel Alexande AlexAún no hay calificaciones
- Ficha 01 C Dispositvos de Seguridad Cargadores Frontales Con Garras y Pi...Documento1 páginaFicha 01 C Dispositvos de Seguridad Cargadores Frontales Con Garras y Pi...Gerson Cartes EspinozaAún no hay calificaciones
- Tutorial Nº1 - InstalaciónDocumento14 páginasTutorial Nº1 - InstalaciónCristian LlumpoAún no hay calificaciones
- Eali U2 A3 SedcDocumento6 páginasEali U2 A3 SedcSergio De La TobaAún no hay calificaciones
- Lista Precios Atx 1 Octubre 22 VfinalDocumento48 páginasLista Precios Atx 1 Octubre 22 VfinalAlain Jaramillo RuizAún no hay calificaciones
- 10.2.6 LabDocumento5 páginas10.2.6 LabALEIDA MARISOL CASILLAS SERRANOAún no hay calificaciones
- GUIAnDEnAPRENDIZAJEnPHYTON 96655f68b69d4cdDocumento14 páginasGUIAnDEnAPRENDIZAJEnPHYTON 96655f68b69d4cdvale25091016Aún no hay calificaciones
- El Micromedio y Su Relación Con El Proceso Salud Enfermedad. PreguntasDocumento3 páginasEl Micromedio y Su Relación Con El Proceso Salud Enfermedad. PreguntasAna Luisa Tejada100% (1)
- Manual Asistente ContableDocumento2 páginasManual Asistente ContableDIEGO ALEXANDER AGURTO MERA100% (1)
- Contactos Mujeres Sexo Maduras Vallecas en MadridDocumento2 páginasContactos Mujeres Sexo Maduras Vallecas en MadridConocer mujeres en MadridAún no hay calificaciones
- Informe - Cubo de Leds PDFDocumento6 páginasInforme - Cubo de Leds PDFAlejandro FernandezAún no hay calificaciones
- Paso A Paso para Instalar XAMPPDocumento14 páginasPaso A Paso para Instalar XAMPPANGUIE CANTORAún no hay calificaciones
- Cuantitativo Alaina ZawadyDocumento6 páginasCuantitativo Alaina ZawadyALAINA LARISSA ZAWADY PEREZAún no hay calificaciones
- 2023 Tarea 1 DBDocumento3 páginas2023 Tarea 1 DBEvelyn Aida RuanoAún no hay calificaciones
- Como Hacer Un Periódico EscolarDocumento11 páginasComo Hacer Un Periódico EscolarZero Zeta100% (1)