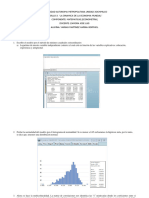
También podría gustarte
- Econometría I: manual de Eviews: Estimulación de un modelo de exportaciónDe EverandEconometría I: manual de Eviews: Estimulación de un modelo de exportaciónAún no hay calificaciones
- Método de La M GrandeDocumento5 páginasMétodo de La M GrandeYiduar Yair Escarraga TrianaAún no hay calificaciones
- Costos para gerenciar organizaciones manufactureras, comerciales y de servicios. Segunda EdiciónDe EverandCostos para gerenciar organizaciones manufactureras, comerciales y de servicios. Segunda EdiciónCalificación: 1 de 5 estrellas1/5 (1)
- Punto de Equilibrio - Contabilidad - COSTOS 2Documento21 páginasPunto de Equilibrio - Contabilidad - COSTOS 2cyndylAún no hay calificaciones
- Costos para gerenciar servicios de saludDe EverandCostos para gerenciar servicios de saludAún no hay calificaciones
- Manual Práctico para La Elaboración de Diagramas de Causa y Efecto, Varianza y Gráficas de Control NP PDFDocumento31 páginasManual Práctico para La Elaboración de Diagramas de Causa y Efecto, Varianza y Gráficas de Control NP PDFIng.OmargmtzAún no hay calificaciones
- UF0255 - Análisis y control de la desviación presupuestaria del producto editorialDe EverandUF0255 - Análisis y control de la desviación presupuestaria del producto editorialAún no hay calificaciones
- Ejemplo de Aplicación de Simulación Montecarlo en Un Caso RealDocumento8 páginasEjemplo de Aplicación de Simulación Montecarlo en Un Caso RealC Andres Angulo SalamancaAún no hay calificaciones
- Simulación de Montecarlo Con Risk SimulatorDocumento4 páginasSimulación de Montecarlo Con Risk SimulatormikelodeAún no hay calificaciones
- Como Hacer Una Regresión Lineal en ExcelDocumento22 páginasComo Hacer Una Regresión Lineal en ExcelMartin VenticinqueAún no hay calificaciones
- Como Hacer Una Regresion Lineal en ExcelDocumento21 páginasComo Hacer Una Regresion Lineal en ExcelMartin VenticinqueAún no hay calificaciones
- Análisis de Sensibilidad Por EscenariosDocumento5 páginasAnálisis de Sensibilidad Por EscenariosAndres CiqueroAún no hay calificaciones
- Análisis de SensibilidadDocumento6 páginasAnálisis de SensibilidadAnonymous sSR6edCAún no hay calificaciones
- Unidad 4 - Escenario 8Documento14 páginasUnidad 4 - Escenario 8Milena ArdilaAún no hay calificaciones
- Sumativa Semana 2Documento9 páginasSumativa Semana 2Jesus GilAún no hay calificaciones
- RiskDocumento17 páginasRiskNestor VillafaneAún no hay calificaciones
- Pasos para Detectar Multicolinealidad en Un Modelo EconometricoDocumento5 páginasPasos para Detectar Multicolinealidad en Un Modelo EconometricoAlvaroHerreraJimenezAún no hay calificaciones
- Estadística Descriptiva FinalDocumento16 páginasEstadística Descriptiva FinalYamel MartínezAún no hay calificaciones
- Hipótesis en El Modelo de Regresión Lineal Por Mínimos Cuadrados OrdinariosDocumento8 páginasHipótesis en El Modelo de Regresión Lineal Por Mínimos Cuadrados OrdinariosLINA MONTEROAún no hay calificaciones
- Clases Riesgo y Rentabilidad - PDF Parte2Documento35 páginasClases Riesgo y Rentabilidad - PDF Parte2Naiara ColmanAún no hay calificaciones
- Entrega FinalDocumento16 páginasEntrega Finalginna paola arevalo avendaño100% (1)
- An Lisis de Sensibilidad-1Documento13 páginasAn Lisis de Sensibilidad-1lucyAún no hay calificaciones
- Correlacion Series de Tiempo Distribucion Normal y ANOVA en Minitab 15Documento76 páginasCorrelacion Series de Tiempo Distribucion Normal y ANOVA en Minitab 15ivanuntAún no hay calificaciones
- Practica 2Documento14 páginasPractica 2Jose Fina GarciaAún no hay calificaciones
- Aplicacion Del Metodo de Monte Carlo en El Analisis de Riesgo de Los ProyectosDocumento8 páginasAplicacion Del Metodo de Monte Carlo en El Analisis de Riesgo de Los ProyectoschristianodavinhoAún no hay calificaciones
- Proyecto en Stata - EspolDocumento18 páginasProyecto en Stata - EspolGabriel Antonio CanalesAún no hay calificaciones
- Control Inv 1Documento9 páginasControl Inv 1R. TintíAún no hay calificaciones
- Aplicación Del Método de Monte Carlo en El Análisis de Riesgo de Los ProyectosDocumento8 páginasAplicación Del Método de Monte Carlo en El Análisis de Riesgo de Los ProyectosDennis SolorzanoAún no hay calificaciones
- Analisis de Regresion Multiple InformeDocumento12 páginasAnalisis de Regresion Multiple InformeSoraya Arotingo100% (1)
- Programación LinealDocumento10 páginasProgramación LinealRonny Eduardo AstudilloAún no hay calificaciones
- Análisis de Datos en ExcelDocumento6 páginasAnálisis de Datos en ExcelcolquisAún no hay calificaciones
- Punto de Equilibrio ResDocumento8 páginasPunto de Equilibrio ResYender peñaAún no hay calificaciones
- Guía Knime Módulo 2 Arboles de ClasificaciónDocumento18 páginasGuía Knime Módulo 2 Arboles de ClasificaciónGilbert BergnaAún no hay calificaciones
- Modelos de EquilirioDocumento9 páginasModelos de EquilirioMarlon Reginaldo Rivera AlvaradoAún no hay calificaciones
- Foro Simulacion Monte CarloDocumento3 páginasForo Simulacion Monte CarloLaura Luna SánchezAún no hay calificaciones
- Analisis de Sensibilidad en Excel Financiero EstudiantesDocumento9 páginasAnalisis de Sensibilidad en Excel Financiero Estudiantesdiego andres londoño pardoAún no hay calificaciones
- Análisis de Sensibilidad en ExcelDocumento8 páginasAnálisis de Sensibilidad en ExcelJESUS DE LA CRUZ BARTOLONAún no hay calificaciones
- Resumen de ClasesDocumento19 páginasResumen de ClasessofiaAún no hay calificaciones
- MNCO-08 Planificacion de A CO-PA en SAPDocumento40 páginasMNCO-08 Planificacion de A CO-PA en SAPLeonardo Mantilla100% (5)
- Semana 12 - El Riesgo en La Evaluación de Proyectos - Punto de EquilibrioDocumento3 páginasSemana 12 - El Riesgo en La Evaluación de Proyectos - Punto de EquilibrioFranklin Roger Del Aguila PazAún no hay calificaciones
- 0 - Analisis Financiero Con RegresiónDocumento14 páginas0 - Analisis Financiero Con RegresiónLuke SkywalkerAún no hay calificaciones
- Metodo de MontecarloDocumento11 páginasMetodo de MontecarloJOSE LUIS PONCE GARCIA DE LAS BAYONASAún no hay calificaciones
- Punto de EquilibrioDocumento7 páginasPunto de EquilibrioKaren Vanessa MejiaAún no hay calificaciones
- Agregar PartesDocumento23 páginasAgregar PartesBryan André Gallo BlasAún no hay calificaciones
- Caso Práctico U3 Plan de MarketingDocumento11 páginasCaso Práctico U3 Plan de Marketingalejandra aguasaco muñozAún no hay calificaciones
- Riesgo en ProyectosDocumento34 páginasRiesgo en ProyectosLuisxMiguelAún no hay calificaciones
- VideosDocumento13 páginasVideosDeiviAún no hay calificaciones
- MC, MS, MR Costos IIIDocumento9 páginasMC, MS, MR Costos IIIlauraAún no hay calificaciones
- Cómo Generar Números Aleatorios en SPSSDocumento12 páginasCómo Generar Números Aleatorios en SPSSNelson Pinto CoaquiraAún no hay calificaciones
- Expo de Financiera 2Documento3 páginasExpo de Financiera 2dayhana rosario ayala venturozoAún no hay calificaciones
- El Riesgo en La Evaluación de ProyectosDocumento7 páginasEl Riesgo en La Evaluación de ProyectosJesús Raúl Choque FernandezAún no hay calificaciones
- 2.2 Modelo Costo Volumen Utilidad Ecuace-2015-CA-cd00127Documento10 páginas2.2 Modelo Costo Volumen Utilidad Ecuace-2015-CA-cd00127Nando LuzuriagaAún no hay calificaciones
- Análisis de Regresión y CorrelaciónDocumento22 páginasAnálisis de Regresión y CorrelaciónJeferson Ruiz.0% (1)
- Punto de Equilibrio y Margen de ContribuciónDocumento45 páginasPunto de Equilibrio y Margen de ContribuciónJessica Corado ManciaAún no hay calificaciones
- Guia 12 - Analisis de Riesgo Crystal BallDocumento12 páginasGuia 12 - Analisis de Riesgo Crystal BallDaniela Calero100% (1)
- Capitulo IIc Contabilidad de Costos y PresupuestosDocumento12 páginasCapitulo IIc Contabilidad de Costos y PresupuestosJose Luis Rivera EspinozaAún no hay calificaciones
- Introducción A RCommander 2020Documento8 páginasIntroducción A RCommander 2020Paul ShelbyAún no hay calificaciones
- Trabajo de Simulación GerencialDocumento4 páginasTrabajo de Simulación GerencialGtc Diaz CarlosAún no hay calificaciones
- Simulación de Monte CarloDocumento9 páginasSimulación de Monte CarloValeskita Baeza LabraAún no hay calificaciones
- Punto de Equilibrio ExposicionDocumento18 páginasPunto de Equilibrio ExposicionmanuelAún no hay calificaciones
- Actividad 1 Vargas Martinez KarinaDocumento2 páginasActividad 1 Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones
- Actividad 2 Vargas Martinez KarinaDocumento3 páginasActividad 2 Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones
- Econometria Practica 6 - Vargas Martinez KarinaDocumento5 páginasEconometria Practica 6 - Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones
- Actividad 3 Vargas Martinez KarinaDocumento2 páginasActividad 3 Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones
- Econometria Practica 7 - Vargas Martinez KarinaDocumento4 páginasEconometria Practica 7 - Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones
- Econometria Practica 4 - Vargas Martinez KarinaDocumento3 páginasEconometria Practica 4 - Vargas Martinez KarinaKARINA XENTHIOL VARGAS MARTINEZAún no hay calificaciones