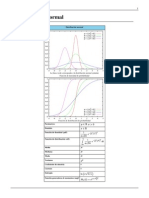
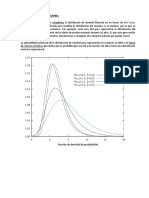
También podría gustarte
- Distribución Normal WIKIDocumento19 páginasDistribución Normal WIKIPedro PucheAún no hay calificaciones
- Distribucion Normal y Normal Reducida o EstandarDocumento13 páginasDistribucion Normal y Normal Reducida o EstandarLMVVAún no hay calificaciones
- Distribuccion NormalDocumento22 páginasDistribuccion NormalsilviaAún no hay calificaciones
- Trabajo de Estadistica 2Documento22 páginasTrabajo de Estadistica 2Anabel Isaura Camacho GomezAún no hay calificaciones
- Distribucion NormalDocumento19 páginasDistribucion NormalSebastian Nieto100% (1)
- Estadistica 2. Distribucion NormalDocumento17 páginasEstadistica 2. Distribucion NormalGabrielAún no hay calificaciones
- Mendiola San 2Documento11 páginasMendiola San 2Lau GMZAún no hay calificaciones
- Distribución Normal - Wikipedia, La Enciclopedia LibreDocumento51 páginasDistribución Normal - Wikipedia, La Enciclopedia LibreCristobal Isaac Arthieedd Vera PalaciosAún no hay calificaciones
- GSM Jamc PiaDocumento12 páginasGSM Jamc PiaGerman SepulvedaAún no hay calificaciones
- Distribución Normal - WikipediaDocumento20 páginasDistribución Normal - WikipediaRicardo VillalongaAún no hay calificaciones
- ESTADISTICADocumento9 páginasESTADISTICAkevinmc 181Aún no hay calificaciones
- D NormalDocumento8 páginasD NormalFranz Brayan Cotache RojasAún no hay calificaciones
- Proyecto Final ProbabilidadDocumento7 páginasProyecto Final Probabilidadmiguel antonioAún no hay calificaciones
- Cuestionario ProbabilidadDocumento4 páginasCuestionario ProbabilidadMarielys BrijaldoAún no hay calificaciones
- Leyes de DistribuciónDocumento16 páginasLeyes de DistribuciónlequirogafAún no hay calificaciones
- Distribucion NormalDocumento4 páginasDistribucion NormalAngeles BeltranAún no hay calificaciones
- Distribucionnormal 1Documento7 páginasDistribucionnormal 1Andrés Eduardo Guevara AmayaAún no hay calificaciones
- TRABAJO DE INVESTIGACION Distribuciã N NormalDocumento16 páginasTRABAJO DE INVESTIGACION Distribuciã N NormalMigdalia LinaresAún no hay calificaciones
- La Distribución NormalDocumento45 páginasLa Distribución NormalTrevor DixonAún no hay calificaciones
- Campana de GaussDocumento9 páginasCampana de GaussAnonymous puMwhm901Aún no hay calificaciones
- Distribucion NormalDocumento13 páginasDistribucion NormalrodrigoAún no hay calificaciones
- Distribucion NormalDocumento6 páginasDistribucion Normalsofi zavallaAún no hay calificaciones
- Distribución NormalDocumento3 páginasDistribución NormalEl winerAún no hay calificaciones
- Informe de Distri - NormalDocumento12 páginasInforme de Distri - NormalGreys VillaAún no hay calificaciones
- Distribución Probabilística ContinuaDocumento13 páginasDistribución Probabilística ContinuaElimar ReyesAún no hay calificaciones
- Evidencias Unidad 4Documento19 páginasEvidencias Unidad 4alu.22130165Aún no hay calificaciones
- Taller Distribucion NormalDocumento7 páginasTaller Distribucion NormalHernan QuinteroAún no hay calificaciones
- Distribucion Normal - EstadisticaDocumento16 páginasDistribucion Normal - EstadisticaPaola RoseroAún no hay calificaciones
- Trabajo de Investigación - EstadísticaDocumento17 páginasTrabajo de Investigación - Estadísticafabianasalanic202131446Aún no hay calificaciones
- Reporte de Teleclase 1Documento11 páginasReporte de Teleclase 1Enrique Zamora EspinozaAún no hay calificaciones
- D. Continua Normal IntroducciónDocumento6 páginasD. Continua Normal IntroducciónJose Pujota ZambranoAún no hay calificaciones
- La Curva NormalDocumento6 páginasLa Curva NormalJessy MorochoAún no hay calificaciones
- Paso 2 Actividad Sobre Distribuciones Muéstrales y EstimaciónDocumento9 páginasPaso 2 Actividad Sobre Distribuciones Muéstrales y EstimaciónDave RinconAún no hay calificaciones
- Articulo de Distribucion Normal.Documento6 páginasArticulo de Distribucion Normal.yuly castroAún no hay calificaciones
- Distribuciones de ProbabilidadDocumento22 páginasDistribuciones de ProbabilidadAlejandro VeleiroAún no hay calificaciones
- Distribución Normal EjerciciosDocumento13 páginasDistribución Normal EjerciciosAngel David Villanueva CajasAún no hay calificaciones
- Cepeda - Deber 3Documento8 páginasCepeda - Deber 3Marisol CepedaAún no hay calificaciones
- Distribución Normal PDFDocumento2 páginasDistribución Normal PDFJose Alfonso Ovalles AlmonteAún no hay calificaciones
- Informe 1 Probabilidad 3Documento8 páginasInforme 1 Probabilidad 3cristinoAún no hay calificaciones
- Distribucion Normal, Logaritmica y GumbelDocumento32 páginasDistribucion Normal, Logaritmica y GumbelJorge CerratoAún no hay calificaciones
- Tarea de Estadista Distribución de ProbabilidadesDocumento25 páginasTarea de Estadista Distribución de Probabilidadesam22039Aún no hay calificaciones
- Distribucion NormalDocumento19 páginasDistribucion Normalcristian toribio acevedoAún no hay calificaciones
- Grafica de GaussDocumento4 páginasGrafica de GaussFidel OsnayaAún no hay calificaciones
- Aporte Probabilidad UNADDocumento2 páginasAporte Probabilidad UNADroropirrorroAún no hay calificaciones
- Trabajo de Estadistica Ii Distribución Normal o de GaussDocumento20 páginasTrabajo de Estadistica Ii Distribución Normal o de GaussCARLOSAún no hay calificaciones
- Distribución NormalDocumento4 páginasDistribución Normaldrymon_159Aún no hay calificaciones
- La Distribución NormalDocumento2 páginasLa Distribución NormalAndre CantosAún no hay calificaciones
- Fase 3 - Distribución NormalDocumento6 páginasFase 3 - Distribución NormalViviana VenteroAún no hay calificaciones
- Untitled 1Documento10 páginasUntitled 1Jorge RuizAún no hay calificaciones
- Distribucion de DatosDocumento19 páginasDistribucion de Datos'YanetCruzRamosAún no hay calificaciones
- Actividad 2.4 Distribuciones Continuas y Distribuciones Muestrales.Documento18 páginasActividad 2.4 Distribuciones Continuas y Distribuciones Muestrales.Reyli LealAún no hay calificaciones
- Probabilidad y Estadistica Investigacion Unidad 4Documento10 páginasProbabilidad y Estadistica Investigacion Unidad 4Santiago SánchezAún no hay calificaciones
- Trabajo Distribucion NormalDocumento9 páginasTrabajo Distribucion NormalGeiner Romero ZapataAún no hay calificaciones
- Inv de Los Temas de La Unidad - E2Documento18 páginasInv de Los Temas de La Unidad - E2Kevin RiveraAún no hay calificaciones
- Probabilidad y Estadística NormalDocumento9 páginasProbabilidad y Estadística NormalIsaac ZTAún no hay calificaciones
- Resumen Glosario 3Documento5 páginasResumen Glosario 3romejiapAún no hay calificaciones
- Cuadro Comparativo de Variables ContinuasDocumento5 páginasCuadro Comparativo de Variables ContinuasAlberto Zepeda100% (2)
- TBL Articulos - Pdf2.b12c812b1877d8a3.373330322e706466Documento9 páginasTBL Articulos - Pdf2.b12c812b1877d8a3.373330322e706466Maria HernándezAún no hay calificaciones
- Aplicaciones Prácticas de La Distribución Normal PDFDocumento7 páginasAplicaciones Prácticas de La Distribución Normal PDFMiranda PérezAún no hay calificaciones
- GVS-CO002 Contrato de Servicios Pospago Avantel 20160706 PDFDocumento4 páginasGVS-CO002 Contrato de Servicios Pospago Avantel 20160706 PDFDiana Carolina Martínez BernalAún no hay calificaciones
- 15 TI, Depreciaciones y AgotamientoDocumento50 páginas15 TI, Depreciaciones y AgotamientoCristina EstevezAún no hay calificaciones
- Ciclos BiogeoquimicosDocumento7 páginasCiclos BiogeoquimicosAlberto Ramirez MarquezAún no hay calificaciones
- S.1.2. - La Botella Azul PDFDocumento2 páginasS.1.2. - La Botella Azul PDFDanny Josué100% (1)
- (AAB02) Cuestionario 2 Resolución de Problemas de Funciones y Aplicaciones de La Vida Real. MATEMATICA BASICADocumento11 páginas(AAB02) Cuestionario 2 Resolución de Problemas de Funciones y Aplicaciones de La Vida Real. MATEMATICA BASICAAbel PachecoAún no hay calificaciones
- Tarea 1 Algebra SuperiorDocumento5 páginasTarea 1 Algebra SuperiorFernandoAndreeFloresEspinosaAún no hay calificaciones
- Alsina, Competencias, 26cuaderno PDFDocumento70 páginasAlsina, Competencias, 26cuaderno PDFOgarrio RojasAún no hay calificaciones
- Planeación Aprendo A Escribir Mi Nombre.Documento4 páginasPlaneación Aprendo A Escribir Mi Nombre.Isabel MonroyAún no hay calificaciones
- Dermaroller: Teófilo Djemal Medicina EstéticaDocumento8 páginasDermaroller: Teófilo Djemal Medicina Estéticamisabo2020Aún no hay calificaciones
- Circuitos o Compuertas LógicasDocumento5 páginasCircuitos o Compuertas LógicasAdriana Alexandra Tataje AllccaAún no hay calificaciones
- Manual de Participacion Ciudadana - PERCAN - MINEMDocumento78 páginasManual de Participacion Ciudadana - PERCAN - MINEMguille_al82Aún no hay calificaciones
- Res - 117 CFE 10Documento6 páginasRes - 117 CFE 10WalterAún no hay calificaciones
- Informe Final Del Proceso de InspeccionDocumento32 páginasInforme Final Del Proceso de InspeccionAlan CuentasAún no hay calificaciones
- Tesis Final Maltrato Psicologico Fe-UnicaDocumento75 páginasTesis Final Maltrato Psicologico Fe-UnicaLuna RXAún no hay calificaciones
- Rubrica Construccion de MapasDocumento2 páginasRubrica Construccion de MapasCesar LicandeoAún no hay calificaciones
- Sesion ABRILDocumento15 páginasSesion ABRILSteisi Evelyn ValdiviezoAún no hay calificaciones
- Procedimiento de Conformaciòn Del CCDocumento8 páginasProcedimiento de Conformaciòn Del CCLeidy MarulandaAún no hay calificaciones
- Informe PsicologicoDocumento4 páginasInforme Psicologicomary0% (1)
- Actividad de Aprendizaje 1. Principios Clave Del Posicionamiento Estratégico.Documento4 páginasActividad de Aprendizaje 1. Principios Clave Del Posicionamiento Estratégico.Jose100% (5)
- Adrian FurnhamDocumento2 páginasAdrian FurnhamPablo Gerardo Barbudez33% (3)
- El Marxismo y El Nuevo Giro ÉticoDocumento23 páginasEl Marxismo y El Nuevo Giro ÉticoBlanca GómezAún no hay calificaciones
- NMX A 069 1990Documento8 páginasNMX A 069 1990Max JaggerjackAún no hay calificaciones
- SGC 2 DiapositivasDocumento46 páginasSGC 2 DiapositivasMiguel Angel Quispe SolanoAún no hay calificaciones
- 4.3. Legislación Informática - PPXDocumento8 páginas4.3. Legislación Informática - PPXmodarcAún no hay calificaciones
- Estadistica 2023 - ResueltoDocumento5 páginasEstadistica 2023 - ResueltoStefany hmAún no hay calificaciones
- PORCELANOSADocumento3 páginasPORCELANOSAJanett FloresAún no hay calificaciones
- Descripcion Del Diploma PDFDocumento4 páginasDescripcion Del Diploma PDFLuis Gustavo Perez SanhuezaAún no hay calificaciones
- NTP - Iso 2859-2Documento51 páginasNTP - Iso 2859-2Jose Garcia75% (4)
- Soluciòn Del Onceavo Capítulo de Anàlisis Estructural IiDocumento29 páginasSoluciòn Del Onceavo Capítulo de Anàlisis Estructural IiRafaelHuaman100% (1)
- Sustitución de TritonesDocumento4 páginasSustitución de Tritonesaracelys ricoAún no hay calificaciones