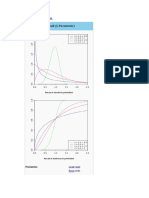
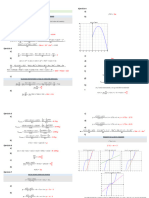
También podría gustarte
- Unidad 2 Metodos de Conteo-CDocumento82 páginasUnidad 2 Metodos de Conteo-CRoberto Gil80% (5)
- Activiadades ProbaDocumento16 páginasActiviadades ProbaJonathan Damian0% (1)
- 1.4 Distribución BinomialDocumento9 páginas1.4 Distribución BinomialMike Rivera yahoo 07 y 2010Aún no hay calificaciones
- Estadística Descriptiva Evaluación Unidades 1,2,3 y Evaluación Final Intentos 1 y 2 AsturiasDocumento21 páginasEstadística Descriptiva Evaluación Unidades 1,2,3 y Evaluación Final Intentos 1 y 2 AsturiasEldrinAún no hay calificaciones
- Imprimir Matemáticas FinancieraDocumento7 páginasImprimir Matemáticas FinancieraMichelle CastilloAún no hay calificaciones
- Formulas de Estadistica I - 16Documento2 páginasFormulas de Estadistica I - 16Sparki AngelAún no hay calificaciones
- Distribución de WeibullDocumento7 páginasDistribución de Weibulleddy gutierrezAún no hay calificaciones
- Formulas de Estadistica DescriptivaDocumento2 páginasFormulas de Estadistica DescriptivaAlessio Amore100% (2)
- Formulario - Estadística Aplicada para Los Negocios (2024)Documento5 páginasFormulario - Estadística Aplicada para Los Negocios (2024)lucianabereniceprAún no hay calificaciones
- Formulario - Estadística Aplicada para Los Negocios (V2) - 1Documento5 páginasFormulario - Estadística Aplicada para Los Negocios (V2) - 1Ardnassela RiveraAún no hay calificaciones
- Formulario - Estadística Aplicada para Los NegociosDocumento5 páginasFormulario - Estadística Aplicada para Los NegociosSamira cordovaAún no hay calificaciones
- Formulario Ingeniería EconómicaDocumento5 páginasFormulario Ingeniería EconómicaFabiana Kilzi BuenoAún no hay calificaciones
- Pauta Prueba 3Documento10 páginasPauta Prueba 3Ámbar MuñozAún no hay calificaciones
- Valores ExtremosDocumento1 páginaValores ExtremosKarol MorenoAún no hay calificaciones
- Formulario - 2023 - UCSUR-Parte 1Documento1 páginaFormulario - 2023 - UCSUR-Parte 1JHOMERT JHEFERSON RIOS ZELAYAAún no hay calificaciones
- Ma444-2021 01-Formulas y tablas-EBDocumento10 páginasMa444-2021 01-Formulas y tablas-EBMoisés Romero FloresAún no hay calificaciones
- Formulario Estadística DescriptivaDocumento2 páginasFormulario Estadística DescriptivaJaroslav ValerAún no hay calificaciones
- Formulario de BioestadísticaDocumento3 páginasFormulario de BioestadísticaIleana GómezAún no hay calificaciones
- TRANSFERENCIA DE CALOR FormularioDocumento6 páginasTRANSFERENCIA DE CALOR FormularioÓscar Soto-GuaderramaAún no hay calificaciones
- Calculo IntegralDocumento11 páginasCalculo Integraljuanguerra970412Aún no hay calificaciones
- Práctica1 AndreaSánchezDocumento23 páginasPráctica1 AndreaSánchezAC Sánchez MaldonadoAún no hay calificaciones
- Tablas EstadísticasDocumento12 páginasTablas Estadísticasarisalopez586Aún no hay calificaciones
- Formulas Estadística Descriptiva y Análisis de DatosDocumento3 páginasFormulas Estadística Descriptiva y Análisis de DatosJulian CornejoAún no hay calificaciones
- Examen Parcial de Mecánica Cuántica 1Documento4 páginasExamen Parcial de Mecánica Cuántica 1oscarAún no hay calificaciones
- ADA4 InfEst LIS Equipo6Documento10 páginasADA4 InfEst LIS Equipo6mgltchmAún no hay calificaciones
- Notas de ClaseDocumento8 páginasNotas de ClaseRonny Alberto Rueda MendezAún no hay calificaciones
- Formulario - Examen v4Documento4 páginasFormulario - Examen v4Alvaro Sanchez GonzalezAún no hay calificaciones
- Balotario CastroDocumento23 páginasBalotario CastroArturo LJAún no hay calificaciones
- 00.summary Mat FinancDocumento2 páginas00.summary Mat FinancjuanjosealvarezpalmaAún no hay calificaciones
- Deber de ComunicacionesDocumento3 páginasDeber de ComunicacionesJefferrson Steven Reyes ZambranoAún no hay calificaciones
- U4. Respuesta Actividad Integradora - Análisis Matemático (72) - 2C - 2021Documento5 páginasU4. Respuesta Actividad Integradora - Análisis Matemático (72) - 2C - 2021thiago aizenbergAún no hay calificaciones
- FormularioDocumento4 páginasFormularioJavier DuetteAún no hay calificaciones
- Formulario 1°parcialDocumento2 páginasFormulario 1°parcialJose Felix Vega SolisAún no hay calificaciones
- 4-Derivadas Parte 1Documento13 páginas4-Derivadas Parte 1juanAún no hay calificaciones
- Exposicion Grupo 4 S3Documento39 páginasExposicion Grupo 4 S3Joan Jesús Tipiani ValdiviaAún no hay calificaciones
- FORMULARIO Bonos y AccionesDocumento2 páginasFORMULARIO Bonos y AccionesGabytel GomezAún no hay calificaciones
- Lagrange TareaDocumento10 páginasLagrange Tareaeduardo franco ortega urdaniviaAún no hay calificaciones
- Cotangente Hiperbolica InversaDocumento7 páginasCotangente Hiperbolica InversaXavier EspinosaAún no hay calificaciones
- FORMULASDocumento1 páginaFORMULASFrancisco Alejandro BeltranAún no hay calificaciones
- ESPE - Examen - Ecuaciones DiferencialesDocumento2 páginasESPE - Examen - Ecuaciones DiferencialesDamian ReinosoAún no hay calificaciones
- Ecuaciones DiferencialesDocumento5 páginasEcuaciones DiferencialesJuan David DelgadoAún no hay calificaciones
- Luis Chusino Taller3Documento12 páginasLuis Chusino Taller3LUIS ENRIQUE CHUSINO CHABLAAún no hay calificaciones
- S03.s1 - Función BetaDocumento19 páginasS03.s1 - Función BetaErick Yauricasa JeronimoAún no hay calificaciones
- Formulario Análisis de Datos 1 IntersemestralDocumento1 páginaFormulario Análisis de Datos 1 IntersemestralEsli Jair Martínez OrdoñezAún no hay calificaciones
- S03.s1 - MaterialDocumento20 páginasS03.s1 - MaterialYovana Cardenas ApazaAún no hay calificaciones
- Formulario Examen Parcial I de Gerencia de InversionesDocumento1 páginaFormulario Examen Parcial I de Gerencia de InversionesJavierAún no hay calificaciones
- Evelin T03Documento12 páginasEvelin T03arturo linaresAún no hay calificaciones
- Sesion 13 Minimos y MaximosDocumento3 páginasSesion 13 Minimos y Maximoscarlos salinas roblesAún no hay calificaciones
- Respuesta Natural de Un Circuito RLCDocumento10 páginasRespuesta Natural de Un Circuito RLCPeter Jonathan Murillo LajeAún no hay calificaciones
- Limites Especiales y ContinuidadDocumento13 páginasLimites Especiales y ContinuidadBenji ApelAún no hay calificaciones
- Celula N°4Documento3 páginasCelula N°4Thiare Melissa Quintero MarriagaAún no hay calificaciones
- Distribucion Normal de Probabilidad - DemostracionesDocumento3 páginasDistribucion Normal de Probabilidad - DemostracionesLeandro Javier RomeroAún no hay calificaciones
- Formulario FinalDocumento2 páginasFormulario FinalCristian Daniel CruzAún no hay calificaciones
- Dominio y RangoDocumento20 páginasDominio y Rangomaberroi sotoAún no hay calificaciones
- 7 - Integrales ImpropiasDocumento16 páginas7 - Integrales ImpropiasAlgebra LinealAún no hay calificaciones
- Pregunta Grupo 7 (3) ...Documento6 páginasPregunta Grupo 7 (3) ...Elizabeth CarmenAún no hay calificaciones
- Discusión 1 - Sumas de RiemannDocumento17 páginasDiscusión 1 - Sumas de RiemannLourdes MartinezAún no hay calificaciones
- Tarea 1. EquipoDocumento15 páginasTarea 1. EquipoPanfilo estefanoAún no hay calificaciones
- Notas de Clase Capítulo 1Documento3 páginasNotas de Clase Capítulo 1ivan.sl.01Aún no hay calificaciones
- FORMULARIODocumento2 páginasFORMULARIOlauraAún no hay calificaciones
- Inducción MatemáticaDocumento7 páginasInducción MatemáticaKirito KiritoAún no hay calificaciones
- 2biind#6 6690 Fep PDFDocumento19 páginas2biind#6 6690 Fep PDFIrving Lorenzo Rojas Canul100% (1)
- Guía Distribución Normal y BinomialDocumento15 páginasGuía Distribución Normal y Binomialaphl6070Aún no hay calificaciones
- Distribución T de HotellingDocumento3 páginasDistribución T de HotellingJavier Garcia RajoyAún no hay calificaciones
- Bin Pois NormDocumento8 páginasBin Pois NormJairo GomezAún no hay calificaciones
- Varialbles Aleatorias GrupalDocumento5 páginasVarialbles Aleatorias GrupalJeremy rodriguezAún no hay calificaciones
- Investigación Estadistica Unidad 3Documento12 páginasInvestigación Estadistica Unidad 3DAVID VALERIO VELAZQUEZAún no hay calificaciones
- ESTADÍSTICA DESCRIPTIVA 2022 - Parte 1Documento69 páginasESTADÍSTICA DESCRIPTIVA 2022 - Parte 1Francisco SoccaAún no hay calificaciones
- Distribución de Probabilidad BinomialDocumento9 páginasDistribución de Probabilidad BinomialJosua RodriguezAún no hay calificaciones
- Econometría Financiera: Clase 1. Modelos Lineales de Series FinancierasDocumento82 páginasEconometría Financiera: Clase 1. Modelos Lineales de Series FinancierasRichard GacitúaAún no hay calificaciones
- Distribución de Probabilidades 1Documento2 páginasDistribución de Probabilidades 1Gustavo Enrique Navarro CapaquiaAún no hay calificaciones
- Generacion de Procesos EstocasticosDocumento12 páginasGeneracion de Procesos EstocasticosEddy Fernández OchoaAún no hay calificaciones
- Tarea 3Documento9 páginasTarea 3tony lucianoAún no hay calificaciones
- Probabilidad GuiaDocumento112 páginasProbabilidad Guiaoscar leonardo delgado trianaAún no hay calificaciones
- VarianzaDocumento26 páginasVarianzaJorge RamirezAún no hay calificaciones
- Trabajo Práctico 4Documento4 páginasTrabajo Práctico 4René PonceAún no hay calificaciones
- Estadística y ProbabilidadDocumento6 páginasEstadística y ProbabilidadAmIn20122Aún no hay calificaciones
- Distribución ExponencialDocumento5 páginasDistribución ExponencialCarlos DiazAún no hay calificaciones
- Calculo de Probabilidades Practica Dirigida 2Documento12 páginasCalculo de Probabilidades Practica Dirigida 2Jessenia R.MoralesAún no hay calificaciones
- Análisis de Datos y VariagrafíaDocumento80 páginasAnálisis de Datos y VariagrafíaMelany Grissel Aguilar100% (1)
- Parcial 1 Ejemplo Simulacion GerencialDocumento8 páginasParcial 1 Ejemplo Simulacion GerencialAlfred ManAún no hay calificaciones
- Guia 1 (Ind 411 - I - 22)Documento3 páginasGuia 1 (Ind 411 - I - 22)Jhoselyn Isabel Usmayo QuispeAún no hay calificaciones
- Silabo Bioestadistica (Medicina Si-19)Documento12 páginasSilabo Bioestadistica (Medicina Si-19)Angie BenitesAún no hay calificaciones
- Trabajo Final Estadistica DescriptivaDocumento6 páginasTrabajo Final Estadistica DescriptivaYaselis CorchoAún no hay calificaciones
- Actividad 1 M3 - Consigna PDFDocumento3 páginasActividad 1 M3 - Consigna PDFCharly DominguezAún no hay calificaciones
- Estad Isticos para La Prueba de Hip Otesis: Dr. Ronald Quispe Flores 28 de Noviembre de 2022Documento3 páginasEstad Isticos para La Prueba de Hip Otesis: Dr. Ronald Quispe Flores 28 de Noviembre de 2022Mileyne PiedraAún no hay calificaciones