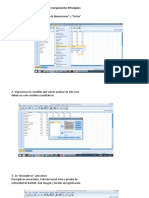
También podría gustarte
- Introducción al Álgebra: Historia y Conceptos BásicosDocumento43 páginasIntroducción al Álgebra: Historia y Conceptos BásicosWilder EscribaAún no hay calificaciones
- Historia del Álgebra Lineal desde los antiguos babilonios hasta el siglo XIXDocumento18 páginasHistoria del Álgebra Lineal desde los antiguos babilonios hasta el siglo XIXmorispAún no hay calificaciones
- Introducción al Álgebra: Historia y Conceptos BásicosDocumento79 páginasIntroducción al Álgebra: Historia y Conceptos BásicosFrans Bruss Flores VallesAún no hay calificaciones
- Historia de la algebra desde antiguos Egipto y BabiloniaDocumento2 páginasHistoria de la algebra desde antiguos Egipto y BabiloniaCielo María Cotillo MontesAún no hay calificaciones
- Algebra LinealDocumento7 páginasAlgebra LinealALANAún no hay calificaciones
- Álgebra y Su HistoriaDocumento6 páginasÁlgebra y Su HistoriaLudwin Salazar ValdiviaAún no hay calificaciones
- Hitoria Del Lenguaje AlgebraicoDocumento2 páginasHitoria Del Lenguaje AlgebraicojulioVenegas83% (6)
- Concepto de AlgebraDocumento2 páginasConcepto de AlgebraCarlos Jose Morales CastellanosAún no hay calificaciones
- Historia de Algebra LinealDocumento10 páginasHistoria de Algebra LinealRoge Urbina CuateAún no hay calificaciones
- Algebra 1°Documento43 páginasAlgebra 1°Cézhar Navarro PardavéAún no hay calificaciones
- Historia del álgebra desde la antigüedadDocumento2 páginasHistoria del álgebra desde la antigüedadEstuardo A RamirezAún no hay calificaciones
- ALGEBRADocumento12 páginasALGEBRAaldoAún no hay calificaciones
- Antecedentes Historicos Del AlgebraDocumento9 páginasAntecedentes Historicos Del AlgebraCecilio García PérezAún no hay calificaciones
- Jitorres HistoriaDocumento3 páginasJitorres Historiahéctor_vazuezAún no hay calificaciones
- Historia Del AlgebraDocumento2 páginasHistoria Del AlgebraJuan Gonzales0% (1)
- Historia Del ÁlgebraDocumento14 páginasHistoria Del ÁlgebraMarkos MarkosAún no hay calificaciones
- Cetis 71: El Lenguaje de Las Matemáticas Historias de Sus SímbolosDocumento5 páginasCetis 71: El Lenguaje de Las Matemáticas Historias de Sus SímbolosHELEN DAYANA IBARRA HERNANDEZAún no hay calificaciones
- AlgebraDocumento7 páginasAlgebraKhadir AcuñaAún no hay calificaciones
- Algebra HistoriaDocumento14 páginasAlgebra HistoriaafdasfsafAún no hay calificaciones
- Capítulo 3 NR David 1raparteDocumento37 páginasCapítulo 3 NR David 1raparteAndres Sanga TitoAún no hay calificaciones
- Algebra SuperiorDocumento14 páginasAlgebra SuperiorDan10Aún no hay calificaciones
- Teoría de Ecuaciones - TXDocumento9 páginasTeoría de Ecuaciones - TXDiego InguilanAún no hay calificaciones
- Trabajo Final Análisis Matemático IIDocumento25 páginasTrabajo Final Análisis Matemático IIGilberto UreñaAún no hay calificaciones
- Aplicaciones Ind PetroleraDocumento5 páginasAplicaciones Ind PetroleraWilly Nasif0% (1)
- Historia Del Álgebra LinealDocumento2 páginasHistoria Del Álgebra LinealRichard Hdz100% (1)
- Algebra Multilineal EsDocumento13 páginasAlgebra Multilineal EsDario MatehuAún no hay calificaciones
- Analisis InfinitesimalDocumento6 páginasAnalisis InfinitesimalRoxana Huerta Renteria100% (1)
- Teoría de EcuacionesDocumento11 páginasTeoría de EcuacionesMelvy Cuevas SilvaAún no hay calificaciones
- Transformación LinealDocumento10 páginasTransformación LinealEmmanuelAún no hay calificaciones
- Aportaciones Al Cálculo IntegralDocumento2 páginasAportaciones Al Cálculo IntegralMarcos RogelioAún no hay calificaciones
- Algebra y Trigonometria BasicaDocumento54 páginasAlgebra y Trigonometria BasicaYuri QuihuiAún no hay calificaciones
- Trabajo de MatematicaDocumento12 páginasTrabajo de MatematicaLeugenis Beltre RamirezAún no hay calificaciones
- Ecuaciones LinealesDocumento11 páginasEcuaciones LinealesIvan Crespin NicasioAún no hay calificaciones
- El Algebra en La AntiguedadDocumento3 páginasEl Algebra en La Antiguedadbibiana0% (1)
- Respuesta ForoDocumento4 páginasRespuesta ForoDiego Francisco Bolivar PinillaAún no hay calificaciones
- Historia Del Calculo IntegralDocumento12 páginasHistoria Del Calculo IntegralMateoAlexisGarciaOrtegaAún no hay calificaciones
- Math 4 - Unidad 1Documento7 páginasMath 4 - Unidad 1Gabi GarciaAún no hay calificaciones
- Ingeniería Didáctica para La Enseñanza Del Cálculo de Raíces Reales de Polinomios CompletoDocumento27 páginasIngeniería Didáctica para La Enseñanza Del Cálculo de Raíces Reales de Polinomios CompletoCristi Cristina100% (1)
- Hist del cálculoDocumento25 páginasHist del cálculoLily Mercedes Andrade RodriguezAún no hay calificaciones
- Tarea 1 Modulo 4Documento4 páginasTarea 1 Modulo 4api-427890585Aún no hay calificaciones
- ÁlgebraDocumento20 páginasÁlgebraRostuar OrloAún no hay calificaciones
- SESIÓN 3 y 8Documento11 páginasSESIÓN 3 y 8Brenda RodriguezAún no hay calificaciones
- Álgebra LinealDocumento15 páginasÁlgebra LinealGAún no hay calificaciones
- Inecuaciones Lineales y de Segundo GradoDocumento18 páginasInecuaciones Lineales y de Segundo GradoPablo Noel Aguirre Vargas100% (5)
- Álgebra LinjealDocumento43 páginasÁlgebra LinjealFrancoAún no hay calificaciones
- Álgebra Lineal - Wikipedia, La Enciclopedia LibreDocumento14 páginasÁlgebra Lineal - Wikipedia, La Enciclopedia Librejoseamh69062247Aún no hay calificaciones
- Antecedentes Historicos Del Cálculo DiferencialDocumento4 páginasAntecedentes Historicos Del Cálculo DiferencialrazielAún no hay calificaciones
- Ms EjrccsDocumento46 páginasMs EjrccsEl lobo ŠJAún no hay calificaciones
- Simbologia de MatematicasDocumento5 páginasSimbologia de MatematicasRicardo PerezAún no hay calificaciones
- Trabajo Historia de Funci N 2Documento6 páginasTrabajo Historia de Funci N 2JavierAún no hay calificaciones
- Unidad 4 Algebra LinealDocumento19 páginasUnidad 4 Algebra LinealBeethHoo IoAún no hay calificaciones
- Historia Del An Alisis Matem Atico AntecDocumento9 páginasHistoria Del An Alisis Matem Atico AntecLuis EduardoAún no hay calificaciones
- Historia Del Algebra LinealDocumento0 páginasHistoria Del Algebra LinealJosé Carlos Hugalde FlowersAún no hay calificaciones
- Espacios VectorialesDocumento29 páginasEspacios VectorialesKarlitos OsorioAún no hay calificaciones
- Antecedentes Históricos Del Álgebra LinealDocumento5 páginasAntecedentes Históricos Del Álgebra LinealRosely Savin Atencio VilcaranaAún no hay calificaciones
- ÁlgebraDocumento8 páginasÁlgebraJOSE JONATHAN MENDOZA MORALESAún no hay calificaciones
- Historia de Las Funciones (Rios Arnaldo)Documento10 páginasHistoria de Las Funciones (Rios Arnaldo)JavierAún no hay calificaciones
- Una mirada distinta de las matrices: Viajes, retos y magiaDe EverandUna mirada distinta de las matrices: Viajes, retos y magiaAún no hay calificaciones
- Practica 4Documento15 páginasPractica 4Zaid Saavedra MendozaAún no hay calificaciones
- Tema 1 Grupos y CamposDocumento3 páginasTema 1 Grupos y CamposZaid Saavedra MendozaAún no hay calificaciones
- Tema 1 - 2014-2Documento193 páginasTema 1 - 2014-2Zaid Saavedra MendozaAún no hay calificaciones
- Pres ArmDocumento45 páginasPres ArmZaid Saavedra MendozaAún no hay calificaciones
- Series - de - Fourier 2018Documento8 páginasSeries - de - Fourier 2018Zaid Saavedra MendozaAún no hay calificaciones
- Tema-1 Ecuaciones Diferenciales 2019-2tema 1 1 (G-3) PDFDocumento33 páginasTema-1 Ecuaciones Diferenciales 2019-2tema 1 1 (G-3) PDFZaid Saavedra MendozaAún no hay calificaciones
- Algebra Lineal Fundamentos y Aplicaciones - Bernard Kolman - 1edDocumento523 páginasAlgebra Lineal Fundamentos y Aplicaciones - Bernard Kolman - 1edStuart GarcíaAún no hay calificaciones
- MatricesDocumento9 páginasMatrices666incubo666Aún no hay calificaciones
- Presentación de CÁLCULO VECTORIAL (DIVERGENCIA Y ROTACIONAL, INTEGRALES DOBLES Y TRIPLES) (29 Julio 23)Documento23 páginasPresentación de CÁLCULO VECTORIAL (DIVERGENCIA Y ROTACIONAL, INTEGRALES DOBLES Y TRIPLES) (29 Julio 23)Rogelio Mauricio Fierro CortinaAún no hay calificaciones
- Métodos de Extracción de FactoresDocumento68 páginasMétodos de Extracción de FactoresViviana SarangoAún no hay calificaciones
- Módulo 4. Actividad 2. Laboratorio MatricesDocumento6 páginasMódulo 4. Actividad 2. Laboratorio MatricesJorge Novo50% (2)
- S1 - Espacios y Subespacios Vectoriales EJERCICIOSDocumento3 páginasS1 - Espacios y Subespacios Vectoriales EJERCICIOSOliver Espada CristobalAún no hay calificaciones
- Gauss SeidelDocumento3 páginasGauss SeidelCarlos PerezAún no hay calificaciones
- Ejercicios A # 5Documento4 páginasEjercicios A # 5asdasd asdasdAún no hay calificaciones
- Semana 1 VectoresDocumento31 páginasSemana 1 VectoresRudolf Keith Muñoz CristobalAún no hay calificaciones
- Ejercicios de Matrices - 1.PdDocumento2 páginasEjercicios de Matrices - 1.PdCesar HernandezAún no hay calificaciones
- Sistemas de Ingeniería - Física - Vectores y PropiedadesDocumento3 páginasSistemas de Ingeniería - Física - Vectores y PropiedadesNeji HyugaAún no hay calificaciones
- UNED - Matemáticas para La Economía: Álgebra (65011084) PEC Abril 2013 PDFDocumento3 páginasUNED - Matemáticas para La Economía: Álgebra (65011084) PEC Abril 2013 PDFuniversoexactoAún no hay calificaciones
- Secuencia Didactica AL 3Documento2 páginasSecuencia Didactica AL 3Rossana Ramirez Zeceña100% (1)
- 6.05 Núcleo e ImagenDocumento4 páginas6.05 Núcleo e ImagenBlog Algebra LinealAún no hay calificaciones
- IS03 S21046332 Sesion 13Documento32 páginasIS03 S21046332 Sesion 13Emanuel JaveAún no hay calificaciones
- Práctica de La Unidad 1 PDFDocumento2 páginasPráctica de La Unidad 1 PDFNathaly PuyaAún no hay calificaciones
- ACPDocumento42 páginasACPCony LepeAún no hay calificaciones
- Modelo de Ecuaciones SimultaneasDocumento5 páginasModelo de Ecuaciones SimultaneasEndersonBustamanteMartinez100% (1)
- Tarea 2 Calculo IntegralDocumento12 páginasTarea 2 Calculo IntegralFredy TumiñaAún no hay calificaciones
- Ejercicios Resueltos de Vectores en El Espacio. Ángulos. MasMates. Matemáticas de SecundariaDocumento1 páginaEjercicios Resueltos de Vectores en El Espacio. Ángulos. MasMates. Matemáticas de SecundariaSebastian andres Argote gonzaLezAún no hay calificaciones
- Los Teoremas Fundamentales Del Cálculo VectorialDocumento14 páginasLos Teoremas Fundamentales Del Cálculo VectorialNot 8Aún no hay calificaciones
- Transformación de Park 2 etapasDocumento4 páginasTransformación de Park 2 etapasEdwin Daniel TatayoAún no hay calificaciones
- Anexo Tarea 3 Jhoan MolanoDocumento8 páginasAnexo Tarea 3 Jhoan MolanoDuvan Eduardo Vergara BolivarAún no hay calificaciones
- Sistemas de Ecuaciones Lineales (Unidad 1)Documento21 páginasSistemas de Ecuaciones Lineales (Unidad 1)Enrique RedondoAún no hay calificaciones
- Matrices y determinantes en álgebra linealDocumento18 páginasMatrices y determinantes en álgebra linealTatiana CamargoAún no hay calificaciones
- UnadmDocumento12 páginasUnadmkenny cirino gallegos vicenteAún no hay calificaciones
- Vectores coordenados y bases ortonormalesDocumento8 páginasVectores coordenados y bases ortonormalesSofia QuintanaAún no hay calificaciones
- Sistemas de E.DDocumento17 páginasSistemas de E.DJohn Alain Stanley Viraca VegaAún no hay calificaciones
- Matemática BásicaDocumento11 páginasMatemática BásicaChinitexAún no hay calificaciones
- Compendio de Definiciones y TeoremasDocumento11 páginasCompendio de Definiciones y TeoremasDayra Ivette Sauri VazquezAún no hay calificaciones