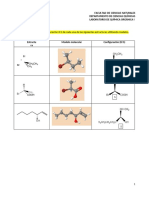
También podría gustarte
- Ruta de Clase Estadísticas DescriptivasDocumento11 páginasRuta de Clase Estadísticas DescriptivasJuliana GuevaraAún no hay calificaciones
- Unidad 7 Medidas ResumenDocumento7 páginasUnidad 7 Medidas ResumenAnalia PoglianoAún no hay calificaciones
- EstadísticaDocumento11 páginasEstadísticarequeabaddorothy100% (2)
- Estadística: Medidas de Tendencia Central (O de Posición)Documento9 páginasEstadística: Medidas de Tendencia Central (O de Posición)Elsa PérezAún no hay calificaciones
- Presentacion Estadistica IV Medidas Descriptivas N 4Documento46 páginasPresentacion Estadistica IV Medidas Descriptivas N 4Roxana PorrasAún no hay calificaciones
- Medidas de Tendencia CentralDocumento21 páginasMedidas de Tendencia Centralmoradtfc100% (2)
- Fase 2 - Variables Estadísticas - Folkenberg DíazDocumento13 páginasFase 2 - Variables Estadísticas - Folkenberg DíazFOLKENBERG DÍAZ PÉREZAún no hay calificaciones
- Medidas Estadísticas 1 y 2Documento15 páginasMedidas Estadísticas 1 y 2Gio HopeAún no hay calificaciones
- Desviación MediaDocumento3 páginasDesviación MediaAnthony MendozaAún no hay calificaciones
- Medidas de Tendencia Central 1Documento21 páginasMedidas de Tendencia Central 1Manuel De Jesus Santeliz LacayoAún no hay calificaciones
- Medidas Estadísticas de Tendencia Central y de DispersiónDocumento33 páginasMedidas Estadísticas de Tendencia Central y de DispersiónRomán Terrazas ValdezAún no hay calificaciones
- Resumen 3.6-3.16Documento9 páginasResumen 3.6-3.16Daniela CherrezAún no hay calificaciones
- Medidas de Tendencia CentralDocumento10 páginasMedidas de Tendencia CentralOsli MuñozAún no hay calificaciones
- Investigacion Aguas EstadisticaDocumento9 páginasInvestigacion Aguas EstadisticaMauro AcostaAún no hay calificaciones
- Estadistica DescriptivaDocumento11 páginasEstadistica DescriptivaOscar SaenzAún no hay calificaciones
- Estadistica ExposiciónDocumento15 páginasEstadistica ExposiciónWiherzon ContrerasAún no hay calificaciones
- Unidad 3 Resumen Completo Probabilidad y EstadísticaDocumento9 páginasUnidad 3 Resumen Completo Probabilidad y EstadísticadientesfornerisAún no hay calificaciones
- Metodos Estadisticos - Unidad 2Documento8 páginasMetodos Estadisticos - Unidad 2Mademoiselle HugAún no hay calificaciones
- RESUMEN-Medida de DespersiónDocumento35 páginasRESUMEN-Medida de DespersiónGhiovani Romero AguirreAún no hay calificaciones
- Clase Nº2Documento50 páginasClase Nº2Ivana Dilia JustinianoAún no hay calificaciones
- Apuntes #2 (Estadígrafos)Documento13 páginasApuntes #2 (Estadígrafos)Katy Nicolet Rojas PiñonesAún no hay calificaciones
- Conocimientos en EstadísticaDocumento9 páginasConocimientos en EstadísticaEduardo HernandezAún no hay calificaciones
- Trabajo de Metrologia (Estadistica)Documento35 páginasTrabajo de Metrologia (Estadistica)Camilo De Jesus PipeAún no hay calificaciones
- Tarea 1Documento9 páginasTarea 1dianibelAún no hay calificaciones
- Medidas de Posición y de VariabilidadDocumento16 páginasMedidas de Posición y de VariabilidadAbi RamosAún no hay calificaciones
- La Media AritméticaDocumento15 páginasLa Media AritméticaCINTHIA MARLENE GARCIA VERAAún no hay calificaciones
- Diapo 2Documento57 páginasDiapo 2omar chuquillanquiAún no hay calificaciones
- INVESTIGACIÓNDocumento10 páginasINVESTIGACIÓNAnyi GarciaAún no hay calificaciones
- Medidas de DispercionDocumento8 páginasMedidas de DispercionChristian Yovanny Pauca CuariteAún no hay calificaciones
- ESTADÍSTICA Matemática AplicadaDocumento15 páginasESTADÍSTICA Matemática Aplicadaselvakornoski100% (27)
- Estadistica Tema 2Documento17 páginasEstadistica Tema 2EDWIN FERNANDO SALINAS QUISPEAún no hay calificaciones
- Invs. EstadisticaDocumento7 páginasInvs. EstadisticaAngel Murdoc MancillaAún no hay calificaciones
- 3-E. Descriptiva-Resumen-de-datosDocumento18 páginas3-E. Descriptiva-Resumen-de-datosRafael BertoniAún no hay calificaciones
- Clase Octubre 19 MC - CAPITULO 3 TAREA - ANGIE ALVARADODocumento8 páginasClase Octubre 19 MC - CAPITULO 3 TAREA - ANGIE ALVARADOAngie AlvaradoAún no hay calificaciones
- InvestigaciónDocumento4 páginasInvestigaciónJennifer GonzalezAún no hay calificaciones
- Cap 3 Descripción de Datos Medidas NuméricasDocumento11 páginasCap 3 Descripción de Datos Medidas NuméricasRoxanaAún no hay calificaciones
- Medidas EstadisticaDocumento7 páginasMedidas EstadisticaYesenia ChinchillaAún no hay calificaciones
- Medidas de Tendencia CentralDocumento4 páginasMedidas de Tendencia CentralDiaz Arias YeseniaAún no hay calificaciones
- Medidas de Posición IntroducciónDocumento26 páginasMedidas de Posición IntroducciónFatima MoralesAún no hay calificaciones
- Medidas de Tendencias CentralesDocumento10 páginasMedidas de Tendencias CentralesgladysAún no hay calificaciones
- Estadistica-Descriptiva - 1Documento21 páginasEstadistica-Descriptiva - 1samantaAún no hay calificaciones
- Resumen Capítulo 3Documento4 páginasResumen Capítulo 3Camila GuevaraAún no hay calificaciones
- Medidas de Tendencia Central - Herrera Gutiérrez María Del RosarioDocumento9 páginasMedidas de Tendencia Central - Herrera Gutiérrez María Del RosarioMary HGAún no hay calificaciones
- Unidad 1 Distribuciones Fundamentales para El MuestreoDocumento10 páginasUnidad 1 Distribuciones Fundamentales para El MuestreoJunior AlbertoAún no hay calificaciones
- Estadística DescriptivaDocumento6 páginasEstadística DescriptivaGlendaZamoraAún no hay calificaciones
- Conceptos Básicos de Probabilidad y EstadísticaDocumento17 páginasConceptos Básicos de Probabilidad y Estadísticaequipo5tosemestre4a gmailAún no hay calificaciones
- Introduccion Al Tratamiento Estadistico de DatosDocumento23 páginasIntroduccion Al Tratamiento Estadistico de DatosDiplomadoEnTecnicasCromatograficasAún no hay calificaciones
- Medidas EstadisticasDocumento16 páginasMedidas EstadisticasEVELYN YOLANDA SANTILLAN VEGAAún no hay calificaciones
- Estadistica SumatoriaDocumento13 páginasEstadistica Sumatoriaammari parraAún no hay calificaciones
- De acuerdo con recientes estudios de la UNICEF (2012) y el Banco Interamericano de Desarrollo (2012) uno de cada dos adolescentes logra completar la secundaria3 Según la Unicef hay 117 millones de niños y jóvenes en América Latina, de estos 22.1 millones se encuentran fuera del sistema educativo o están en riesgo de hacerlo.4 Este dato sólo incluye a los estudiantes entre 5 a 14 años (educación básica). De acuerdo con el BID la tasa de culminación de secundaria completa (12 años), es cercana al 40% entre los jóvenes de 20 a 24 años. Lo que implica que 50 millones de jóvenes de la región no lograr culminar la secundaria completa.5Documento41 páginasDe acuerdo con recientes estudios de la UNICEF (2012) y el Banco Interamericano de Desarrollo (2012) uno de cada dos adolescentes logra completar la secundaria3 Según la Unicef hay 117 millones de niños y jóvenes en América Latina, de estos 22.1 millones se encuentran fuera del sistema educativo o están en riesgo de hacerlo.4 Este dato sólo incluye a los estudiantes entre 5 a 14 años (educación básica). De acuerdo con el BID la tasa de culminación de secundaria completa (12 años), es cercana al 40% entre los jóvenes de 20 a 24 años. Lo que implica que 50 millones de jóvenes de la región no lograr culminar la secundaria completa.5April ReyesAún no hay calificaciones
- Manuel Alejandro - 93Documento12 páginasManuel Alejandro - 93Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Tarea 1-PROB - 2006845Documento16 páginasTarea 1-PROB - 2006845Sergio MedellinAún no hay calificaciones
- Open Class Sem 3 Nov-Dic21Documento33 páginasOpen Class Sem 3 Nov-Dic21Nayeli YocupicioAún no hay calificaciones
- Estadística - (Tema 3) - Medidas de Posición y de Dispersión - (PPT) (2019-1)Documento26 páginasEstadística - (Tema 3) - Medidas de Posición y de Dispersión - (PPT) (2019-1)ToteB.P-hAún no hay calificaciones
- U3A1 DEF DefincionesDocumento6 páginasU3A1 DEF DefincionesLaura RivasAún no hay calificaciones
- Tema 3Documento11 páginasTema 3Jorge Rojas LopezAún no hay calificaciones
- VariabilidadDocumento31 páginasVariabilidadJulia Elena Sanoja RialAún no hay calificaciones
- Parámetros Posición y Dispersión - RevisadoDocumento12 páginasParámetros Posición y Dispersión - RevisadoPepe CastañedaAún no hay calificaciones
- PROBABILIDAD Conceptos Avanzados y SimbologiaDocumento6 páginasPROBABILIDAD Conceptos Avanzados y SimbologiaOscar PonceAún no hay calificaciones
- Ruta de Clase Datos AgrupadosDocumento8 páginasRuta de Clase Datos Agrupadosjuan sebastian arellano henaoAún no hay calificaciones
- Taller para Examen 3Documento1 páginaTaller para Examen 3juan sebastian arellano henaoAún no hay calificaciones
- Taller para Examen 1Documento1 páginaTaller para Examen 1juan sebastian arellano henaoAún no hay calificaciones
- Tabla InfrarrojosDocumento10 páginasTabla Infrarrojosjuan sebastian arellano henaoAún no hay calificaciones
- Hoja de Trabajo 2Documento10 páginasHoja de Trabajo 2juan sebastian arellano henaoAún no hay calificaciones
- Tarea 2 Individual Estadistica - Laura MariaDocumento3 páginasTarea 2 Individual Estadistica - Laura Mariajuan sebastian arellano henaoAún no hay calificaciones
- Informe Lab 6 CorregidoDocumento27 páginasInforme Lab 6 Corregidojuan sebastian arellano henaoAún no hay calificaciones
- Hoja de Trabajo 2Documento10 páginasHoja de Trabajo 2juan sebastian arellano henaoAún no hay calificaciones
- Moleculares (8 PUNTOS)Documento4 páginasMoleculares (8 PUNTOS)juan sebastian arellano henaoAún no hay calificaciones
- Práctica 2 Virtual Taller 2 Estereoquímica y Reflexión Sobre Un Caso ÉticoDocumento8 páginasPráctica 2 Virtual Taller 2 Estereoquímica y Reflexión Sobre Un Caso Éticojuan sebastian arellano henaoAún no hay calificaciones
- Tarea 1 Analisis Matematico 2 (Sucesiones) UapaDocumento12 páginasTarea 1 Analisis Matematico 2 (Sucesiones) UapaVictor Campusano sosaAún no hay calificaciones
- Silabo de Analisis Matematico IDocumento6 páginasSilabo de Analisis Matematico IMaximiliano Condor HuamanAún no hay calificaciones
- Ecuaciones DiferencialesDocumento4 páginasEcuaciones DiferencialesDaniel HernándezAún no hay calificaciones
- Informe 2Documento5 páginasInforme 2Javier Mauricio SanchezAún no hay calificaciones
- Instructivo R&RDocumento7 páginasInstructivo R&RfrankelisedwardoAún no hay calificaciones
- Teorema FundamentalDocumento12 páginasTeorema FundamentalTCAún no hay calificaciones
- Calculo Difencial e Integral Maximos y Minimos BibliografiaDocumento7 páginasCalculo Difencial e Integral Maximos y Minimos BibliografiaginnebraAún no hay calificaciones
- Analisis de Regresion Lineal PDFDocumento33 páginasAnalisis de Regresion Lineal PDFJefferson Márquez BarronAún no hay calificaciones
- Analisis de SensibilidadDocumento7 páginasAnalisis de Sensibilidadyuritzi100% (1)
- Prueba de Hipótesis EjerciciosDocumento1 páginaPrueba de Hipótesis EjerciciosManuel LipaAún no hay calificaciones
- 23 - Tarea No.2Documento56 páginas23 - Tarea No.2Kevin AlfonsoAún no hay calificaciones
- Series y Transformada de Fourier-ModificadaDocumento43 páginasSeries y Transformada de Fourier-Modificadaanuar charrupi araratAún no hay calificaciones
- PDF 20230110 212719 0000 PDFDocumento1 páginaPDF 20230110 212719 0000 PDFMiguel BrizuelaAún no hay calificaciones
- Usando Matlab para Resolver EDOs de Primer OrdenDocumento6 páginasUsando Matlab para Resolver EDOs de Primer Orden969609993Aún no hay calificaciones
- INGENIERÍA INDUSTRIAL 9°CICLO Investigacion de Operaciones IIDocumento6 páginasINGENIERÍA INDUSTRIAL 9°CICLO Investigacion de Operaciones IIPercy Ccancce QuispeAún no hay calificaciones
- Actividad 3-CálculoII-2018ADocumento4 páginasActividad 3-CálculoII-2018Afernando gomez cifuentesAún no hay calificaciones
- Derivadas ParcialesDocumento14 páginasDerivadas ParcialesNancy GonzalezAún no hay calificaciones
- Evaluacion Funciones 11 PDFDocumento3 páginasEvaluacion Funciones 11 PDFMariuxi AcencioAún no hay calificaciones
- Bibliografía Ciencias SocialesDocumento3 páginasBibliografía Ciencias SocialesYotas PelotasAún no hay calificaciones
- Guia Funciones 1Documento10 páginasGuia Funciones 1sita_yanisAún no hay calificaciones
- Problemas de Equilibrio Ionico-Unprg-2021Documento2 páginasProblemas de Equilibrio Ionico-Unprg-2021Britney Lu VásquezAún no hay calificaciones
- KCIN - Evidencia de Aprendizaje - U1Documento2 páginasKCIN - Evidencia de Aprendizaje - U1Darken KiraAún no hay calificaciones
- Tarea 1 Polinomio de TaylorDocumento25 páginasTarea 1 Polinomio de TaylorCórdova García Sergio EduardoAún no hay calificaciones
- Regresion Con R ComanderDocumento31 páginasRegresion Con R ComanderelsaunachiAún no hay calificaciones
- Taller 17Documento39 páginasTaller 17Sebastian CuevaAún no hay calificaciones
- Practica3 BuffersDocumento6 páginasPractica3 BuffersRodrigo Rijalba100% (1)
- Examen Unidad 3 PDFDocumento6 páginasExamen Unidad 3 PDFyeison estibenAún no hay calificaciones
- Entrega 1 SimulacionDocumento30 páginasEntrega 1 SimulacionCreyentes En CristoAún no hay calificaciones
- Clase 2.0 de Inferencia Estadística 2019-2Documento47 páginasClase 2.0 de Inferencia Estadística 2019-2Leidy Lozano JimenezAún no hay calificaciones
- Actividad de Puntos Evaluables - Escenario 2 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA IIDocumento5 páginasActividad de Puntos Evaluables - Escenario 2 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA IIJlAún no hay calificaciones
- Introducción al psicoanálisis: el mangaDe EverandIntroducción al psicoanálisis: el mangaCalificación: 5 de 5 estrellas5/5 (20)
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Entrelazamiento cuántico y sincronicidad. Campos de fuerza, no localidad, percepciones extrasensoriales. Las sorprendentes propiedades de la física cuántica.De EverandEntrelazamiento cuántico y sincronicidad. Campos de fuerza, no localidad, percepciones extrasensoriales. Las sorprendentes propiedades de la física cuántica.Calificación: 4.5 de 5 estrellas4.5/5 (9)
- Mi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaDe EverandMi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaCalificación: 5 de 5 estrellas5/5 (5)
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Armónicas en Sistemas Eléctricos IndustrialesDe EverandArmónicas en Sistemas Eléctricos IndustrialesCalificación: 4.5 de 5 estrellas4.5/5 (12)
- Fundamentos de matemática: Introducción al nivel universitarioDe EverandFundamentos de matemática: Introducción al nivel universitarioCalificación: 3 de 5 estrellas3/5 (9)
- Las matemáticas de la biología: De las celdas de las abejas a las simetrías de los virusDe EverandLas matemáticas de la biología: De las celdas de las abejas a las simetrías de los virusCalificación: 4 de 5 estrellas4/5 (1)
- Guía práctica para la refracción ocularDe EverandGuía práctica para la refracción ocularCalificación: 5 de 5 estrellas5/5 (2)
- La magia de los números: 136 recreaciones aritméticas y geométricasDe EverandLa magia de los números: 136 recreaciones aritméticas y geométricasCalificación: 1 de 5 estrellas1/5 (1)
- Visualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónDe EverandVisualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónCalificación: 5 de 5 estrellas5/5 (18)
- Aprendizaje Automático: El Aprendizaje Automático para principiantes que desean comprender aplicaciones, Inteligencia Artificial, Minería de Datos, Big Data y másDe EverandAprendizaje Automático: El Aprendizaje Automático para principiantes que desean comprender aplicaciones, Inteligencia Artificial, Minería de Datos, Big Data y másCalificación: 3.5 de 5 estrellas3.5/5 (6)
- Matemáticas financieras y evaluación de proyectos: Segunda ediciónDe EverandMatemáticas financieras y evaluación de proyectos: Segunda ediciónAún no hay calificaciones
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- La Física - Aventura del pensamientoDe EverandLa Física - Aventura del pensamientoCalificación: 4.5 de 5 estrellas4.5/5 (9)
- El Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalDe EverandEl Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalCalificación: 5 de 5 estrellas5/5 (3)
- Había una vez el átomo: O cómo los científicos imaginan lo invisibleDe EverandHabía una vez el átomo: O cómo los científicos imaginan lo invisibleCalificación: 5 de 5 estrellas5/5 (3)
- Los mágicos números del Doctor Matrix: Conviértete en un maestro de los númerosDe EverandLos mágicos números del Doctor Matrix: Conviértete en un maestro de los númerosCalificación: 5 de 5 estrellas5/5 (2)
- Estrategias de muestreo: Diseño de encuestas y estimación de parámetrosDe EverandEstrategias de muestreo: Diseño de encuestas y estimación de parámetrosCalificación: 5 de 5 estrellas5/5 (1)
- Cálculo integral: Técnicas de integraciónDe EverandCálculo integral: Técnicas de integraciónCalificación: 4 de 5 estrellas4/5 (8)