También podría gustarte
- Dominio y RangoDocumento24 páginasDominio y RangoDidier Alexis Imbachi PoloAún no hay calificaciones
- Una Variable Aleatoria Es Un Valor Numérico Que Corresponde Al Resultado de Un Experimento AleatorioDocumento15 páginasUna Variable Aleatoria Es Un Valor Numérico Que Corresponde Al Resultado de Un Experimento AleatorioFrancis NavarroAún no hay calificaciones
- Separata EA1 2014 01Documento308 páginasSeparata EA1 2014 01avhcc167% (3)
- Funcion Buscarv y TallerDocumento7 páginasFuncion Buscarv y TallerViviana Jimenez SánchezAún no hay calificaciones
- ALGEBRA LINEAL Por Competencias v-2Documento9 páginasALGEBRA LINEAL Por Competencias v-2Eduardohrdz HernandezAún no hay calificaciones
- Guía de Estadística Descriptiva 2020Documento18 páginasGuía de Estadística Descriptiva 2020Valentina BalladaresAún no hay calificaciones
- Cuestionario de probabilidad y estadística para encuesta de empleadosDocumento5 páginasCuestionario de probabilidad y estadística para encuesta de empleadosOMAR TORRES RODRIGUEZAún no hay calificaciones
- Estimación de ParámetrosDocumento22 páginasEstimación de ParámetrosJesús PardoAún no hay calificaciones
- Álgebra lineal actividad 1Documento7 páginasÁlgebra lineal actividad 1Jhonny VegaAún no hay calificaciones
- Montaña Rusa de NewtonDocumento7 páginasMontaña Rusa de NewtonvictorAún no hay calificaciones
- Laboratorio 7 ElectroDocumento4 páginasLaboratorio 7 ElectroNeyer BastidasAún no hay calificaciones
- Ejercicios Propuestos de Arreglos UnidimensionalesDocumento1 páginaEjercicios Propuestos de Arreglos UnidimensionalesHUNTER - FOXAún no hay calificaciones
- Probabilidad CondicionalDocumento12 páginasProbabilidad CondicionalMax PaheinAún no hay calificaciones
- Comprensión de Textos GratisDocumento7 páginasComprensión de Textos GratisCess CuroAún no hay calificaciones
- Contenido y Taller de Vectores en El PlanoDocumento21 páginasContenido y Taller de Vectores en El PlanojaredAún no hay calificaciones
- Tarea 1Documento3 páginasTarea 1Daniel Vargas100% (1)
- Ejercicios de Estadistica DescriptivaDocumento5 páginasEjercicios de Estadistica DescriptivaFerchoMGAún no hay calificaciones
- Plan de Aula ECUACIONES DIFERENCIALESDocumento8 páginasPlan de Aula ECUACIONES DIFERENCIALESOmar TrespalaciosAún no hay calificaciones
- CONJUNTOSDocumento3 páginasCONJUNTOSVictor YaltaAún no hay calificaciones
- Estadistica Aplicada A La Informatica y Algunos PersonajesDocumento8 páginasEstadistica Aplicada A La Informatica y Algunos PersonajesSanta De La CruzAún no hay calificaciones
- Calculo VectorialDocumento26 páginasCalculo VectorialCougar JairomarvinAún no hay calificaciones
- Cálculo CombinatorioDocumento2 páginasCálculo Combinatorioprofesoramatematicas100% (1)
- Trabajo Sobre Informes EstadísticosDocumento10 páginasTrabajo Sobre Informes EstadísticosAgus BuffaAún no hay calificaciones
- Analisis Vectorial - PrimariaDocumento8 páginasAnalisis Vectorial - PrimariaBrunoAún no hay calificaciones
- Silabo Calculo III FIGAE-UNFV-2018-Ccesa007Documento9 páginasSilabo Calculo III FIGAE-UNFV-2018-Ccesa007Demetrio Ccesa RaymeAún no hay calificaciones
- Transversalidad de La Estadistica en La Ingenieria de Sistemas EnsayoDocumento2 páginasTransversalidad de La Estadistica en La Ingenieria de Sistemas EnsayoKalethistas MonteriaAún no hay calificaciones
- Ecuación general rectaDocumento4 páginasEcuación general rectaGabriela PinzonAún no hay calificaciones
- Componentes PrincipalesDocumento34 páginasComponentes PrincipalesCamilo ArizaAún no hay calificaciones
- Algebra LinealDocumento84 páginasAlgebra LinealAmistad BecergAún no hay calificaciones
- 4 EconometriasDocumento81 páginas4 EconometriaskrisbrickerAún no hay calificaciones
- Estadistica AplicadaDocumento11 páginasEstadistica AplicadaBRYAN OREAún no hay calificaciones
- Análisis numérico: resolución de problemas matemáticosDocumento3 páginasAnálisis numérico: resolución de problemas matemáticosDaniel Hernández Pulido50% (2)
- Contenido Semana I - Notación SumatoriaDocumento12 páginasContenido Semana I - Notación SumatoriaYimiAún no hay calificaciones
- Cuaderno de Trabajo de Algebra Lineal PDFDocumento212 páginasCuaderno de Trabajo de Algebra Lineal PDFAnonymous oCGO0E3yKPAún no hay calificaciones
- TP1 - EJERCICIOS 1 A 11 PARCIALMENTE RESUELTOSDocumento42 páginasTP1 - EJERCICIOS 1 A 11 PARCIALMENTE RESUELTOSMicaela Páez0% (1)
- Proyecto Final EstadisticaDocumento20 páginasProyecto Final EstadisticaMARIAM DIVIANA GOMEZ TORRESAún no hay calificaciones
- Variables Aleatorias y Distribuciones de ProbabilidadDocumento6 páginasVariables Aleatorias y Distribuciones de Probabilidaddiego alexander martinez lopezAún no hay calificaciones
- Ejercicios Propuestos Estimadores Puntuales USACHDocumento3 páginasEjercicios Propuestos Estimadores Puntuales USACHalejandroAún no hay calificaciones
- Silabo Ecuaciones Diferenciales P4 2020Documento12 páginasSilabo Ecuaciones Diferenciales P4 2020María José MadridAún no hay calificaciones
- Coeficiente de ContingenciaDocumento8 páginasCoeficiente de ContingenciaAurelio Garcia100% (1)
- Alren Bach G M1 U3Documento7 páginasAlren Bach G M1 U3José100% (1)
- Teoría de Conjuntos: Conceptos BásicosDocumento23 páginasTeoría de Conjuntos: Conceptos BásicosrubenAún no hay calificaciones
- Estadistica Aplicada A La Investigacion CientificaDocumento20 páginasEstadistica Aplicada A La Investigacion CientificaShakespeareAún no hay calificaciones
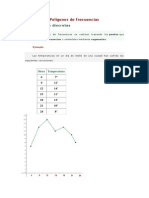
- Polígonos de FrecuenciasDocumento7 páginasPolígonos de FrecuenciasJonathan Dominguez100% (1)
- Estadistica GeneralDocumento178 páginasEstadistica GeneralJoel Ivan Salvador VilchezAún no hay calificaciones
- Curva de Ajuste, Regresion y CorrelacionDocumento24 páginasCurva de Ajuste, Regresion y CorrelacionJavier MernesAún no hay calificaciones
- MA-104 Álgebra Lineal RubricaDocumento18 páginasMA-104 Álgebra Lineal RubricaCaleb MarínAún no hay calificaciones
- AMIcap 3Documento40 páginasAMIcap 3Hernan BacciAún no hay calificaciones
- Micro CurriculoDocumento23 páginasMicro CurriculoAngel Castillo ChinchillaAún no hay calificaciones
- Conjunto Potencia: Matemáticas Conjunto Subconjuntos Axiomas de Zermelo-Fraenkel Axioma Del Conjunto PotenciaDocumento4 páginasConjunto Potencia: Matemáticas Conjunto Subconjuntos Axiomas de Zermelo-Fraenkel Axioma Del Conjunto Potenciaalberto_leguizaAún no hay calificaciones
- Combinatoria IDocumento3 páginasCombinatoria ITonksHerodaleAún no hay calificaciones
- Enfoques Económicos de La InvestigaciónDocumento2 páginasEnfoques Económicos de La InvestigaciónDaniel Rubio100% (1)
- Tesis UnanDocumento11 páginasTesis UnanyelinAún no hay calificaciones
- Contabilidad MatricialDocumento18 páginasContabilidad MatricialSergio PretteAún no hay calificaciones
- Teoría Del ProductorDocumento2 páginasTeoría Del ProductorMAYRA C100% (1)
- Grafico Estadísticos Gráfico de Bastones PDFDocumento4 páginasGrafico Estadísticos Gráfico de Bastones PDFAnamelba Edith Zare Varela0% (1)
- EstadísticaDocumento11 páginasEstadísticarequeabaddorothy100% (2)
- Taller de EstadisticaDocumento11 páginasTaller de EstadisticaJh JjAún no hay calificaciones
- Resumen EstadsticaDocumento26 páginasResumen EstadsticaJosé Mijael Acosta CastroAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Programa de Historia II 3º AÑO POLIMODALDocumento1 páginaPrograma de Historia II 3º AÑO POLIMODALselvakornoski100% (2)
- Programa de Historia I 1º AÑO POLIMODALDocumento1 páginaPrograma de Historia I 1º AÑO POLIMODALselvakornoski100% (3)
- Programa de Formación Ética y Ciudadana 8º EGB 3Documento2 páginasPrograma de Formación Ética y Ciudadana 8º EGB 3selvakornoski50% (2)
- Planificación Del Taller de MatemáticaDocumento7 páginasPlanificación Del Taller de Matemáticaselvakornoski92% (13)
- Programa Ciencias Sociales 8º AÑO EGB 3Documento1 páginaPrograma Ciencias Sociales 8º AÑO EGB 3selvakornoski100% (1)
- Trabajo Práctico #2 Del Taller de MatemáticaDocumento1 páginaTrabajo Práctico #2 Del Taller de MatemáticaselvakornoskiAún no hay calificaciones
- Trabajo Práctico #2 Del Taller de MatemáticaDocumento1 páginaTrabajo Práctico #2 Del Taller de MatemáticaselvakornoskiAún no hay calificaciones
- Programa de Contenidos 9Documento3 páginasPrograma de Contenidos 9selvakornoskiAún no hay calificaciones
- Planificación Anual de 8º AñoDocumento8 páginasPlanificación Anual de 8º Añoselvakornoski100% (17)
- C00204 4 2013 C EmailDocumento112 páginasC00204 4 2013 C EmailCarlosEduardoAcostaMateusAún no hay calificaciones
- Informe Pruebas Carbohidratos BioquímicaDocumento12 páginasInforme Pruebas Carbohidratos BioquímicaDanier Munoz BuitronAún no hay calificaciones
- Foro de Contextualización 4. Análisis de Acoplamientos Fijos y Móviles.Documento5 páginasForo de Contextualización 4. Análisis de Acoplamientos Fijos y Móviles.Selene Julio CastillaAún no hay calificaciones
- Unidad 1. Acción 1.3. Mapa Conceptual. Clasificación de Operaciones Unitarias.Documento3 páginasUnidad 1. Acción 1.3. Mapa Conceptual. Clasificación de Operaciones Unitarias.Manuel Arellano100% (2)
- Mapa de Karnaugh PDFDocumento3 páginasMapa de Karnaugh PDFtroyAún no hay calificaciones
- Analisis de Labaoratorio Pendulo - MaxwellDocumento15 páginasAnalisis de Labaoratorio Pendulo - MaxwellDanny CardenasAún no hay calificaciones
- Apuntes Realizacion TelevisivaDocumento16 páginasApuntes Realizacion TelevisivaFernando BotiaAún no hay calificaciones
- Análisis Del Caso de Patronaje, Corte y ConfeccionDocumento6 páginasAnálisis Del Caso de Patronaje, Corte y ConfeccionLeyit EscorciaAún no hay calificaciones
- EFMPDocumento9 páginasEFMPIngrid CarmonaAún no hay calificaciones
- TP Reactor 2021Documento9 páginasTP Reactor 2021Maxi PeraltaAún no hay calificaciones
- Calentadores IndustrialesDocumento5 páginasCalentadores Industrialesdavidyovera100% (1)
- Clasificacion y Designacion de RoscasDocumento22 páginasClasificacion y Designacion de RoscasIan Aldama100% (3)
- 2.2 Vectores y Geometria. Problemas Repaso.Documento18 páginas2.2 Vectores y Geometria. Problemas Repaso.Kevin Tapia RagasAún no hay calificaciones
- Resumen 1 - U1 - AbmDocumento3 páginasResumen 1 - U1 - AbmAngie BravoAún no hay calificaciones
- Química 1 InformeDocumento3 páginasQuímica 1 InformeDanna HoyosAún no hay calificaciones
- Estocásticos Utp Taller 3Documento3 páginasEstocásticos Utp Taller 3pastunageorgeAún no hay calificaciones
- Manual Vertor Espa - Ol PDFDocumento70 páginasManual Vertor Espa - Ol PDFadrian MXAún no hay calificaciones
- Contorl de Flujo Presion y TempDocumento5 páginasContorl de Flujo Presion y TempValeko AhXaAún no hay calificaciones
- Ley de FourierDocumento105 páginasLey de FourierLucero MamaniAún no hay calificaciones
- Provincias PetrologicasDocumento36 páginasProvincias PetrologicasBryan BalcazarAún no hay calificaciones
- ALCANOSDocumento39 páginasALCANOSraulAún no hay calificaciones
- Zw32-12d Interruptor de Potencia Sojo - 1Documento5 páginasZw32-12d Interruptor de Potencia Sojo - 1Luis Francisco Calderon EspinozaAún no hay calificaciones
- Informe de MoliendaDocumento9 páginasInforme de Moliendayuli gilAún no hay calificaciones
- Semana Del 15 Al 18 de Febrero de 2021Documento10 páginasSemana Del 15 Al 18 de Febrero de 2021Elsa RiveraAún no hay calificaciones
- Menas Mas ExplotadasDocumento26 páginasMenas Mas ExplotadasVicAún no hay calificaciones
- Informe Reloj de YODODocumento5 páginasInforme Reloj de YODOKevin ContrerasAún no hay calificaciones
- GuevaraVillalobosLuisCarlos PRA1 AltaDisponibilidadDocumento22 páginasGuevaraVillalobosLuisCarlos PRA1 AltaDisponibilidadLuis Carlos Guevara VillalobosAún no hay calificaciones
- 01-Elementos Visuales - Los Bloques de Construcción de Su PinturaDocumento12 páginas01-Elementos Visuales - Los Bloques de Construcción de Su PinturaJorge Peñaloza MendozaAún no hay calificaciones
- Biomoléculas orgánicas e inorgánicas en seres vivosDocumento10 páginasBiomoléculas orgánicas e inorgánicas en seres vivosjamerAún no hay calificaciones