También podría gustarte
- Desarrollo seguro en ingeniería del software.: Aplicaciones seguras con Android, NodeJS, Python y C++De EverandDesarrollo seguro en ingeniería del software.: Aplicaciones seguras con Android, NodeJS, Python y C++Aún no hay calificaciones
- Guia Axie Infinity Esp v1.0Documento119 páginasGuia Axie Infinity Esp v1.0Walk W92% (13)
- Lengua Castellana y LiteraturaDocumento4 páginasLengua Castellana y Literaturasuper-woman100% (3)
- NethServer Documentation PDFDocumento104 páginasNethServer Documentation PDFjesusyabayAún no hay calificaciones
- Hacking & cracking. Redes inalámbricas wifiDe EverandHacking & cracking. Redes inalámbricas wifiCalificación: 4.5 de 5 estrellas4.5/5 (2)
- Manual Usuario Informix 4GLDocumento43 páginasManual Usuario Informix 4GLDiego Alejandro Forero Mendieta50% (2)
- Guía Axie Infinity 2.0Documento22 páginasGuía Axie Infinity 2.0José Santana100% (6)
- Reevaluacion Cartografica Del Anticlinal de La CañadaDocumento19 páginasReevaluacion Cartografica Del Anticlinal de La CañadaJohn Mauricio Rico BautistaAún no hay calificaciones
- Linea TiempoDocumento1 páginaLinea TiempoMonica Munoz HAún no hay calificaciones
- Operacion Del MontacargasDocumento76 páginasOperacion Del MontacargasMarco Antonio Constantino Moreno100% (1)
- PFC HTGDocumento110 páginasPFC HTGUnbaAún no hay calificaciones
- Recibiendo Tramas 802.15.4 - ZigBee Con Waspmote GatewayDocumento11 páginasRecibiendo Tramas 802.15.4 - ZigBee Con Waspmote GatewayAgustín Rodríguez RojasAún no hay calificaciones
- Proyecto Con La RomDocumento144 páginasProyecto Con La RomluisAún no hay calificaciones
- Equipo 1 Grupo 814 ADocumento25 páginasEquipo 1 Grupo 814 AAdriana Elorza RamosAún no hay calificaciones
- Cimco Edit 6 (Es) NodbDocumento186 páginasCimco Edit 6 (Es) NodbMario Mtz RangelAún no hay calificaciones
- QGIS 3.10 UserGuide EsDocumento1233 páginasQGIS 3.10 UserGuide EsLlano Extremo GuanareAún no hay calificaciones
- Manual QGIS 2.8Documento346 páginasManual QGIS 2.8ramonAún no hay calificaciones
- Lopez Andres 2022 Sistema Teleoperacion RobotsDocumento78 páginasLopez Andres 2022 Sistema Teleoperacion RobotsManuel ortiz camachoAún no hay calificaciones
- QGIS 2.6 UserGuide EsDocumento739 páginasQGIS 2.6 UserGuide EsOscar ZamoraAún no hay calificaciones
- Recopilacion de Informacion Sobre Futbol y Prediccion Bardisa Serrano AdrianDocumento54 páginasRecopilacion de Informacion Sobre Futbol y Prediccion Bardisa Serrano AdrianMarc LinaresAún no hay calificaciones
- QGIS 2.8 UserGuide EsDocumento350 páginasQGIS 2.8 UserGuide EsMarcos Ferreira AmoedoAún no hay calificaciones
- Psicometría Aplicada Con Jamovi (Elosua, P., y Egaña, M. 2020)Documento124 páginasPsicometría Aplicada Con Jamovi (Elosua, P., y Egaña, M. 2020)PPjamoviAún no hay calificaciones
- Notas Python PDFDocumento57 páginasNotas Python PDFmjcarriAún no hay calificaciones
- Transformacion de La Emocion de Una Cara en Una Imagen A Azuar Alonso DavidDocumento84 páginasTransformacion de La Emocion de Una Cara en Una Imagen A Azuar Alonso DavidESNAYDER CASTILLEJOS TENAZOAAún no hay calificaciones
- Comandos Cisco Ccna ExplorationDocumento23 páginasComandos Cisco Ccna ExplorationdeimorgaAún no hay calificaciones
- QGIS 3.16 DesktopUserGuide EsDocumento1347 páginasQGIS 3.16 DesktopUserGuide EsJavier Yribarren MondejarAún no hay calificaciones
- YII 2 GuiaDocumento452 páginasYII 2 GuiaDirenAún no hay calificaciones
- Contenido Del LibroDocumento16 páginasContenido Del LibroEvane FortunatoAún no hay calificaciones
- QGIS 3.16 DesktopUserGuide EsDocumento1379 páginasQGIS 3.16 DesktopUserGuide EsMarlon AlfaroAún no hay calificaciones
- QGIS 3.28 DesktopUserGuide EsDocumento1581 páginasQGIS 3.28 DesktopUserGuide EsIoana NeculaAún no hay calificaciones
- Implementacion de Apps en AndroidDocumento36 páginasImplementacion de Apps en AndroidProgra MacionAún no hay calificaciones
- QGIS 3.16 DesktopUserGuide EsDocumento1367 páginasQGIS 3.16 DesktopUserGuide EspollodelaabuelaAún no hay calificaciones
- Gui 02Documento204 páginasGui 02Jean Carlos Guillen ParedesAún no hay calificaciones
- QGIS 2.8 UserGuide EsDocumento751 páginasQGIS 2.8 UserGuide Esmargarita_vivas_guevAún no hay calificaciones
- R para PrincipiantesDocumento61 páginasR para PrincipiantesMiguel Angel JimenezAún no hay calificaciones
- R para Principiantes Autor Emmanuel ParDocumento61 páginasR para Principiantes Autor Emmanuel ParCarlos Elias Altamar BolibarAún no hay calificaciones
- Clases PostgresqlDocumento113 páginasClases PostgresqlPedro Muñoz del Rio100% (1)
- TFG Javier Martinez Llamas CNN InformeDocumento57 páginasTFG Javier Martinez Llamas CNN InformeJhonny Ü PatricAún no hay calificaciones
- Texto StataDocumento35 páginasTexto StataAdrian FiantAún no hay calificaciones
- Curso Basico de R PDFDocumento128 páginasCurso Basico de R PDFHéctor W Moreno QAún no hay calificaciones
- Weka ProyectoDocumento20 páginasWeka ProyectoCarlos Francisco Ojeda UreñaAún no hay calificaciones
- Informe Aguado EmderDocumento37 páginasInforme Aguado EmderLuis DeEadAún no hay calificaciones
- PFC ManueltrinidadgarciaDocumento215 páginasPFC ManueltrinidadgarciaMarciano Acosta Anzueta100% (1)
- KernelDocumento106 páginasKernelCandido AramburuAún no hay calificaciones
- QGIS 2.14 UserGuide EsDocumento427 páginasQGIS 2.14 UserGuide EsDario NavarreteAún no hay calificaciones
- Qgis 2.18Documento490 páginasQgis 2.18JorgeNúñezAún no hay calificaciones
- Ejercicios Con DerivadasDocumento488 páginasEjercicios Con DerivadasreyesmanAún no hay calificaciones
- Manual Computo IDocumento84 páginasManual Computo IDaniel ParraAún no hay calificaciones
- TG - 1816 - Deteccion y Seguimiento de Personas - MontoyaDocumento49 páginasTG - 1816 - Deteccion y Seguimiento de Personas - MontoyaMatias FernándezAún no hay calificaciones
- Manual Latex Kile PDFDocumento76 páginasManual Latex Kile PDFRoyer Jhoset Cardenas HuamanAún no hay calificaciones
- Academia X Guia C# v1.0.0Documento41 páginasAcademia X Guia C# v1.0.0mgjpg201100% (1)
- Raw Sockets Programming With C (Spanish)Documento55 páginasRaw Sockets Programming With C (Spanish)Mauricio100% (3)
- QGIS 2.18 UserGuide EsDocumento490 páginasQGIS 2.18 UserGuide EsGiancarlo ItaAún no hay calificaciones
- Intro Ducci Nae Structur Aded A To SDocumento22 páginasIntro Ducci Nae Structur Aded A To SIris Claudia Rocha MartinezAún no hay calificaciones
- Ejercicios Weka PDFDocumento20 páginasEjercicios Weka PDFtodocfeAún no hay calificaciones
- QGIS 3.22 DesktopUserGuide EsDocumento1457 páginasQGIS 3.22 DesktopUserGuide EsRubén GuerraAún no hay calificaciones
- QGIS 3.4 UserGuide EsDocumento599 páginasQGIS 3.4 UserGuide EsDiego VázquezAún no hay calificaciones
- QGIS 2.18 UserGuide EsDocumento490 páginasQGIS 2.18 UserGuide EsSandreins Chacón GilAún no hay calificaciones
- Manual PythonDocumento27 páginasManual PythonErnesto RBAún no hay calificaciones
- Análisis y diseño de piezas de máquinas con CATIA V5De EverandAnálisis y diseño de piezas de máquinas con CATIA V5Aún no hay calificaciones
- Diseño de experimentos. Estrategias y análisis en ciencias e ingenieríasDe EverandDiseño de experimentos. Estrategias y análisis en ciencias e ingenieríasAún no hay calificaciones
- Circuitos Integrados Digitales CMOS: Análisis y DiseñoDe EverandCircuitos Integrados Digitales CMOS: Análisis y DiseñoAún no hay calificaciones
- John Lennon Un Humanista Subversivo PDFDocumento90 páginasJohn Lennon Un Humanista Subversivo PDFHector FarakAún no hay calificaciones
- Favor Emitir Transferencia O Cheque No Endosable A Nombre de Central Santo Tome I, C.ADocumento1 páginaFavor Emitir Transferencia O Cheque No Endosable A Nombre de Central Santo Tome I, C.AJosé SantanaAún no hay calificaciones
- 4gl GET ENVDocumento3 páginas4gl GET ENVJosé SantanaAún no hay calificaciones
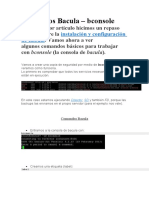
- Comandos BaculaDocumento16 páginasComandos BaculaJosé SantanaAún no hay calificaciones
- Comandos BaculaDocumento16 páginasComandos BaculaJosé SantanaAún no hay calificaciones
- Bacula 2021Documento44 páginasBacula 2021José SantanaAún no hay calificaciones
- República Bolivariana de Venezuela Ministerio de EducaciónDocumento6 páginasRepública Bolivariana de Venezuela Ministerio de EducaciónJosé SantanaAún no hay calificaciones
- Trayectoria Del Proyecto de Escuelas BolivarianaDocumento16 páginasTrayectoria Del Proyecto de Escuelas BolivarianaJosé SantanaAún no hay calificaciones
- T2-Metod - Inv. - Grupo 18Documento5 páginasT2-Metod - Inv. - Grupo 18Erika JulcaAún no hay calificaciones
- Act. - 1 - Tabla ComparativaDocumento3 páginasAct. - 1 - Tabla ComparativaJheily MorrobelAún no hay calificaciones
- Clasificacion de Presas PDFDocumento2 páginasClasificacion de Presas PDFFreddy Vargas RiveraAún no hay calificaciones
- PDF Sesion de Aprendizaje Fecundacion y Desarrollo Embrionario - CompressDocumento2 páginasPDF Sesion de Aprendizaje Fecundacion y Desarrollo Embrionario - CompressMaria Tu Lokita LindaAún no hay calificaciones
- Sifon InvertidoDocumento7 páginasSifon InvertidoGino Aguirre SanchezAún no hay calificaciones
- Ingenieria CivilDocumento1 páginaIngenieria CivilDaniel CaychoAún no hay calificaciones
- LABORATORIO DE ISV UNAH Agosto 2016 PDFDocumento1 páginaLABORATORIO DE ISV UNAH Agosto 2016 PDFJosselynAún no hay calificaciones
- Mousse de Sangrecita TripticoDocumento2 páginasMousse de Sangrecita TripticoEdward RosadoAún no hay calificaciones
- Ofimatica Power PointDocumento30 páginasOfimatica Power PointAlejandro Zorrilla Choez50% (2)
- Manual de Planta Productora de AmoniacoDocumento24 páginasManual de Planta Productora de AmoniacoThane BotticelliAún no hay calificaciones
- Región AndinaDocumento6 páginasRegión AndinaTatiana Andrea AlegriaAún no hay calificaciones
- 2° 1° Cuatrimestre - SotoDocumento5 páginas2° 1° Cuatrimestre - SotoLucas Soto100% (2)
- Miércoles de Temporas en La Octava de Pentecostés PDFDocumento4 páginasMiércoles de Temporas en La Octava de Pentecostés PDFIGLESIA DEL SALVADOR DE TOLEDO (ESPAÑA)100% (1)
- Trastorno de La PersonalidadDocumento17 páginasTrastorno de La PersonalidadAlexAún no hay calificaciones
- Compendio de Ejercicios de Comprensión Lectora - Textos Discontinuos RuzDocumento29 páginasCompendio de Ejercicios de Comprensión Lectora - Textos Discontinuos RuzRuben MarecosAún no hay calificaciones
- 496838-Introducci N A La Pedagog A PDFDocumento97 páginas496838-Introducci N A La Pedagog A PDFIván MorenoAún no hay calificaciones
- Mecanismos para OrientarseDocumento5 páginasMecanismos para OrientarseBiblioteca elcopey-cesar.gov.coAún no hay calificaciones
- EnsayoDocumento3 páginasEnsayoNely Estefany Pérez HernándezAún no hay calificaciones
- Eportfolio - Mahara Desde La ExperienciaDocumento240 páginasEportfolio - Mahara Desde La ExperienciaNagore Ipiña LarrañagaAún no hay calificaciones
- Toma de Decisiones.Documento8 páginasToma de Decisiones.jimmy alexander betancourtAún no hay calificaciones
- Foro 4-Seminario de InvestigaciónDocumento1 páginaForo 4-Seminario de InvestigaciónTania MauricioAún no hay calificaciones
- All-Products Esuprt Laptop Esuprt Latitude Laptop Latitude-2120 Service Manual Es-MxDocumento62 páginasAll-Products Esuprt Laptop Esuprt Latitude Laptop Latitude-2120 Service Manual Es-MxRonny FulcadoAún no hay calificaciones
- C221 C4 EJEMPLOS Instrumentos de EvaluacionDocumento6 páginasC221 C4 EJEMPLOS Instrumentos de EvaluacionNatalia de los Angeles GuaymasAún no hay calificaciones
- Yogurt de QuinuaDocumento1 páginaYogurt de QuinuaAlex WilberAún no hay calificaciones
- Informe Mantenimeinto de Obras CivilesDocumento7 páginasInforme Mantenimeinto de Obras CivilesAylín Colina JordánAún no hay calificaciones
- Escalera de InferenciaDocumento4 páginasEscalera de Inferenciarabas_Aún no hay calificaciones