También podría gustarte
- Manual de Supervivencia del Administrador de Bases de DatosDe EverandManual de Supervivencia del Administrador de Bases de DatosAún no hay calificaciones
- UF1472 - Lenguajes de definición y modificación de datos SQLDe EverandUF1472 - Lenguajes de definición y modificación de datos SQLAún no hay calificaciones
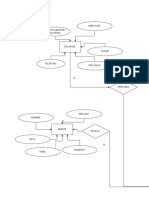
- Reglas Codd Sistema RelacionalDocumento18 páginasReglas Codd Sistema RelacionalCristian GarayAún no hay calificaciones
- 12 ReglasDocumento11 páginas12 ReglasTOMOYO870612Aún no hay calificaciones
- Las 12 Reglas de CoddDocumento6 páginasLas 12 Reglas de CoddpatriciaeneaAún no hay calificaciones
- 12 Reglas de CoddDocumento6 páginas12 Reglas de CoddWalter ArriazaAún no hay calificaciones
- Trabajo 2Documento6 páginasTrabajo 2Ernesto BahamondeAún no hay calificaciones
- 12 Reglas de CoddDocumento6 páginas12 Reglas de CoddLars FloRivAún no hay calificaciones
- Reglas de Codd: 12 reglas para sistemas de bases de datos relacionalesDocumento5 páginasReglas de Codd: 12 reglas para sistemas de bases de datos relacionalesOmar MartínezAún no hay calificaciones
- Las 12 Reglas de CoddDocumento3 páginasLas 12 Reglas de Coddruben_10_0Aún no hay calificaciones
- 12 Reglas de Codd - InternetDocumento5 páginas12 Reglas de Codd - InternetFlor B DelgadoAún no hay calificaciones
- 12 Reglas de Codd - InternetDocumento7 páginas12 Reglas de Codd - InternetFlor B DelgadoAún no hay calificaciones
- 12 Reglas CoddDocumento5 páginas12 Reglas CoddEmilio VarelaAún no hay calificaciones
- 12 Reglas RDBMSDocumento9 páginas12 Reglas RDBMSJuan Carlos Romero CheroAún no hay calificaciones
- A4luisernestocasadonova19 Eisn 8 012Documento7 páginasA4luisernestocasadonova19 Eisn 8 012pupuAún no hay calificaciones
- Reglas de Codd 2023Documento28 páginasReglas de Codd 2023Juanjo FelAún no hay calificaciones
- TEMA 5 - Diseño de Base de Datos Relacionales - RÍos Alcántara, Alma (2019)Documento5 páginasTEMA 5 - Diseño de Base de Datos Relacionales - RÍos Alcántara, Alma (2019)Robin hoodAún no hay calificaciones
- Doce Reglas de CoddDocumento9 páginasDoce Reglas de Coddkydn26Aún no hay calificaciones
- Reg Las CoddDocumento6 páginasReg Las CoddFranklin Ramos OrtizAún no hay calificaciones
- 12 Reglas de CoddDocumento2 páginas12 Reglas de Coddfalc_jirehAún no hay calificaciones
- Reglas Codd SqlserverDocumento24 páginasReglas Codd SqlserverFernandoMMonroyAún no hay calificaciones
- A7 - Fasv - Proyecto Integrador2 - BDRDocumento6 páginasA7 - Fasv - Proyecto Integrador2 - BDRFre SerrAún no hay calificaciones
- Actividad I Base de DatosDocumento3 páginasActividad I Base de DatosJhobnatanRosarioSantosAún no hay calificaciones
- Las 12 Reglas de Codd PDFDocumento2 páginasLas 12 Reglas de Codd PDFLanncetAún no hay calificaciones
- BASES DE DATOS ApuntesDocumento6 páginasBASES DE DATOS ApuntesThomasAún no hay calificaciones
- Reglas de Codd Motores de Base de DatosDocumento28 páginasReglas de Codd Motores de Base de DatosFelipeA.DuránRodriguez100% (3)
- Modelo Relacional de CoddDocumento7 páginasModelo Relacional de CoddIvan IbarraAún no hay calificaciones
- Reglas de Codd Motores de Base de DatosDocumento27 páginasReglas de Codd Motores de Base de DatosFelipeA.DuránRodriguezAún no hay calificaciones
- Curso - SQL BasicoDocumento39 páginasCurso - SQL Basicoblasman77Aún no hay calificaciones
- Las 12 Reglas de Codd.Documento3 páginasLas 12 Reglas de Codd.Araceli GalvánAún no hay calificaciones
- Bases de Datos Las Leyes de CoodDocumento2 páginasBases de Datos Las Leyes de CoodIan A HerreraAún no hay calificaciones
- Reglas de CoddDocumento3 páginasReglas de Coddjesuar8912Aún no hay calificaciones
- Taller 4Documento15 páginasTaller 4Santiago Alvarez VargasAún no hay calificaciones
- Fundamentos de La NormalizaciónDocumento5 páginasFundamentos de La NormalizaciónNeyfi M. BritoAún no hay calificaciones
- Las 13 Reglas de CoddDocumento1 páginaLas 13 Reglas de Coddbebesonik0Aún no hay calificaciones
- Reglas de Codd SGBDDocumento9 páginasReglas de Codd SGBDJose MasAún no hay calificaciones
- 12 Reglas de CoddDocumento2 páginas12 Reglas de Coddivan JmzAún no hay calificaciones
- 12 Reglas de Codd PDFDocumento2 páginas12 Reglas de Codd PDFStGAún no hay calificaciones
- Inteligencia NegociosDocumento3 páginasInteligencia NegociosLore UrregoAún no hay calificaciones
- 12 Reglas de CoddDocumento4 páginas12 Reglas de CoddCarlos MurciaAún no hay calificaciones
- 12 Reglas de CoddDocumento4 páginas12 Reglas de CoddCarlos MurciaAún no hay calificaciones
- 01 12 Reglas DR. CODDDocumento2 páginas01 12 Reglas DR. CODDJessica RodriguezAún no hay calificaciones
- V2-MP - 0484 - UF1 - WBT4 - Restricciones Inherentes Del Modelo RelacionalDocumento13 páginasV2-MP - 0484 - UF1 - WBT4 - Restricciones Inherentes Del Modelo RelacionalRubenAsecaSecasAún no hay calificaciones
- Practica 3 Laboratorio de Base de DatosDocumento5 páginasPractica 3 Laboratorio de Base de DatosRhina Ramos MorelAún no hay calificaciones
- Las 12 reglas de Codd para un SGBDRDocumento10 páginasLas 12 reglas de Codd para un SGBDRSonia CalAún no hay calificaciones
- ACID compliant y transacciones en bases de datosDocumento8 páginasACID compliant y transacciones en bases de datosGustavo GonzalezAún no hay calificaciones
- 12 Reglas de CoddDocumento19 páginas12 Reglas de CoddRichard RodriguezAún no hay calificaciones
- Instituto Tecnologico de Nuevo LeonDocumento8 páginasInstituto Tecnologico de Nuevo LeonesagarAún no hay calificaciones
- 0002 - Temas semana 6 unidad 3Documento20 páginas0002 - Temas semana 6 unidad 3global goldAún no hay calificaciones
- T2 12 Reglas de Codd2Documento5 páginasT2 12 Reglas de Codd2AbrahamAún no hay calificaciones
- Sistema de Gestion de Base de Datos SQLDocumento12 páginasSistema de Gestion de Base de Datos SQLDmolitionBoyAún no hay calificaciones
- Curso - SQL BasicoDocumento39 páginasCurso - SQL BasicoJuan Alejandro Rosales CoronelAún no hay calificaciones
- Normalización en Base de DatosDocumento10 páginasNormalización en Base de Datosjuanbedoyaamu04Aún no hay calificaciones
- Las 12 reglas de CoddDocumento17 páginasLas 12 reglas de CoddNelson Romero VeraAún no hay calificaciones
- Bases de Datos C# PDFDocumento15 páginasBases de Datos C# PDFtheweebmanAún no hay calificaciones
- Consejos para Disminuir Los Niveles de Contensión y Aumentar La ConcurrenciaDocumento1 páginaConsejos para Disminuir Los Niveles de Contensión y Aumentar La ConcurrenciaJack Castro ArizaAún no hay calificaciones
- Modelo E-RDocumento8 páginasModelo E-RjbramosAún no hay calificaciones
- BASESDEDATOSDocumento51 páginasBASESDEDATOSABRAHAMAún no hay calificaciones
- 12 Reglas de CoddDocumento3 páginas12 Reglas de CoddDaniel Alexander Rivas NietoAún no hay calificaciones
- Guìa de Aprendizaje - Taller Conceptos Bases de DatosDocumento7 páginasGuìa de Aprendizaje - Taller Conceptos Bases de DatosWilliam RicauteAún no hay calificaciones
- SGBD-conceptos-claves-BDDocumento3 páginasSGBD-conceptos-claves-BDRoberto Marc Hernández DíazAún no hay calificaciones
- Relaciones N:M entre entidadesDocumento2 páginasRelaciones N:M entre entidadesRoberto Marc Hernández DíazAún no hay calificaciones
- RHD AgenciaviajesDocumento6 páginasRHD AgenciaviajesRoberto Marc Hernández DíazAún no hay calificaciones
- RHD 1.5.exámenesDocumento1 páginaRHD 1.5.exámenesRoberto Marc Hernández DíazAún no hay calificaciones
- DRAGODocumento11 páginasDRAGOMaritza Parihuancollo ChoqueAún no hay calificaciones
- Curso de Introducción Al Desarrollo Web - HTML y CSS (1 - 2) - EvaluaciónDocumento3 páginasCurso de Introducción Al Desarrollo Web - HTML y CSS (1 - 2) - EvaluaciónJorge Yupanqui TorresAún no hay calificaciones
- Visual C++Documento3 páginasVisual C++flgrhnAún no hay calificaciones
- 2.1.3.6 Lab - Setting Up A Virtualized Server EnvironmentDocumento13 páginas2.1.3.6 Lab - Setting Up A Virtualized Server EnvironmentFredy Alexander Sandoval FuqueneAún no hay calificaciones
- Control y Seguridad de Un Centro de ComputoDocumento8 páginasControl y Seguridad de Un Centro de ComputoLaRana28Aún no hay calificaciones
- Codigos de BarrasDocumento29 páginasCodigos de BarrasOswaldo Montoya RangelAún no hay calificaciones
- Excel 2016 - New HorizonteDocumento8 páginasExcel 2016 - New HorizonteSADHE0% (1)
- SaaP vs. SaaSDocumento40 páginasSaaP vs. SaaSAmanda DuranAún no hay calificaciones
- 02 MySQL UPDATEDocumento7 páginas02 MySQL UPDATEMaualeoAún no hay calificaciones
- Mfa Okta Setup EsDocumento2 páginasMfa Okta Setup EsROBERTO CORONAAún no hay calificaciones
- Teorema de Cap en Bases de Datos NosqlDocumento3 páginasTeorema de Cap en Bases de Datos NosqlJjcp CornejoAún no hay calificaciones
- Investigacion Sistemas OperativosDocumento4 páginasInvestigacion Sistemas OperativosfdsvAún no hay calificaciones
- CronogramaConvocatoria 029 2019 AateDocumento7 páginasCronogramaConvocatoria 029 2019 AateArturo Galvez AguilarAún no hay calificaciones
- Villafuerte2019 en EsDocumento7 páginasVillafuerte2019 en EsKimberly ZavaletaAún no hay calificaciones
- Plan de Trabajo CIST SJB2019Documento12 páginasPlan de Trabajo CIST SJB2019juanAún no hay calificaciones
- Practica 0 HidraulicaDocumento6 páginasPractica 0 HidraulicaPolly LozanoAún no hay calificaciones
- Trabajo N 3Documento4 páginasTrabajo N 3Jean Carlos Mendizabal ChecmapoccoAún no hay calificaciones
- v6 - Dsi - Poa ReformuladoDocumento80 páginasv6 - Dsi - Poa ReformuladoOrlandoAún no hay calificaciones
- T Espe 029761 PDFDocumento219 páginasT Espe 029761 PDFEdwin EstradaAún no hay calificaciones
- 02 Programacion Segura Sitios Web PDFDocumento78 páginas02 Programacion Segura Sitios Web PDFarmandocasasAún no hay calificaciones
- Capacitacion Centro DatosDocumento20 páginasCapacitacion Centro DatosKhalú C'rAún no hay calificaciones
- Practica de ArchivosDocumento10 páginasPractica de ArchivosAlejandra FernándezAún no hay calificaciones
- Sistemas Expertos Basado en ReglasDocumento55 páginasSistemas Expertos Basado en ReglasEdson Huerta GamarraAún no hay calificaciones
- Sistema RedWiDocumento4 páginasSistema RedWiGuinazu MoyaAún no hay calificaciones
- Instalación AUTOCAD PAMCAD 2014Documento16 páginasInstalación AUTOCAD PAMCAD 2014manolo tenaAún no hay calificaciones
- AvayaDocumento276 páginasAvayaFher RGAún no hay calificaciones
- Metodología de ProyectosDocumento24 páginasMetodología de ProyectosAldo Velásquez Huerta95% (39)
- Modelo RACI, Metas y Objetivos de La Estrategia de Servicios de TIDocumento12 páginasModelo RACI, Metas y Objetivos de La Estrategia de Servicios de TIJocsan Benitez ValdezAún no hay calificaciones
- Caso N.2-Better FitnessDocumento12 páginasCaso N.2-Better FitnessJosé Ramos PonceAún no hay calificaciones
- Ejercicio Resuelto 3 - Ferreteria IndustrialDocumento9 páginasEjercicio Resuelto 3 - Ferreteria IndustrialcamiraveraAún no hay calificaciones