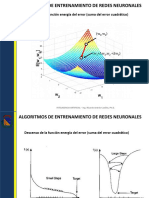
También podría gustarte
- Redes Neuronales y Aplicaciones en IngenieríaDocumento67 páginasRedes Neuronales y Aplicaciones en IngenieríaEddy Caceres100% (1)
- Inteligencia Artificial Aplicada A Los Rayos Gamma Espectrales (SL)Documento93 páginasInteligencia Artificial Aplicada A Los Rayos Gamma Espectrales (SL)ner68Aún no hay calificaciones
- Introducción A Las Redes NeuronalesDocumento16 páginasIntroducción A Las Redes Neuronalesjacastillo68Aún no hay calificaciones
- Informe Ia Borja SevillaDocumento4 páginasInforme Ia Borja SevillaAnthony SevillaAún no hay calificaciones
- Sesion Redes V4Documento22 páginasSesion Redes V4Carlos EstelaAún no hay calificaciones
- Clase 7. Redes NeuronalesDocumento24 páginasClase 7. Redes NeuronalesMaria Edilma ParraAún no hay calificaciones
- Redes Neuronales-1Documento18 páginasRedes Neuronales-1LOURDES GISELE LOPEZ RAMIREZAún no hay calificaciones
- Introducción A Las Redes PDFDocumento14 páginasIntroducción A Las Redes PDFDANIEL SILVAAún no hay calificaciones
- Sesion6 SI UNTELS2021Documento40 páginasSesion6 SI UNTELS2021WILLY FRANCIS DELGADO TUANAMAAún no hay calificaciones
- Redes Neuronales Cursillo Congreso 95Documento19 páginasRedes Neuronales Cursillo Congreso 95Jesus LandaetaAún no hay calificaciones
- Sesion5 RN UntelsDocumento43 páginasSesion5 RN UntelsISABELLA SUSANA CABALLERO MORENOAún no hay calificaciones
- Manual Proyectos Electronica - MeduagDocumento12 páginasManual Proyectos Electronica - MeduagJeymis P. De la Cruz PalaciosAún no hay calificaciones
- HopfieldDocumento10 páginasHopfieldjumh9908Aún no hay calificaciones
- Capitulo2 BackpropagationDocumento39 páginasCapitulo2 BackpropagationArmando Miguel Brito CriadoAún no hay calificaciones
- Ricardo Coronado Redes Neuronales FINALDocumento168 páginasRicardo Coronado Redes Neuronales FINALJulio PardoAún no hay calificaciones
- Equipo 14Documento11 páginasEquipo 14Juan Diego Marin RodriguezAún no hay calificaciones
- Redes Neuronales ArtificialesDocumento129 páginasRedes Neuronales ArtificialesLibbeth Faustino Arias0% (1)
- Practica 1 y 2 Circuitos LogicosDocumento15 páginasPractica 1 y 2 Circuitos LogicosRoberto Samuel Tuda AlonzoAún no hay calificaciones
- Introduccion Redes NeuralesDocumento47 páginasIntroduccion Redes NeuralesWiisshoo DeppAún no hay calificaciones
- Cia - U2 - Cap4 - Redes NeuronalesDocumento126 páginasCia - U2 - Cap4 - Redes NeuronalesSebastian CavieresAún no hay calificaciones
- Perceptrón Simple: Redes Neuronales Con Aprendizaje SupervisadoDocumento68 páginasPerceptrón Simple: Redes Neuronales Con Aprendizaje SupervisadosuviryAún no hay calificaciones
- EXPO CONTROL INTELIGENTE Redes HopfieldDocumento27 páginasEXPO CONTROL INTELIGENTE Redes HopfieldCAROAún no hay calificaciones
- Presentacion Neurona Artificial 02-05-2022Documento56 páginasPresentacion Neurona Artificial 02-05-2022Luis ChavarriaAún no hay calificaciones
- Clase 8. Redes NeuronalesDocumento23 páginasClase 8. Redes NeuronalesMaria Edilma ParraAún no hay calificaciones
- Redes Neuronales 1Documento23 páginasRedes Neuronales 1Luis Emilio Alvarez O.Aún no hay calificaciones
- S02.s1 - Material-1 Redes NeuronalesDocumento27 páginasS02.s1 - Material-1 Redes Neuronalesgenesis claresAún no hay calificaciones
- NEURONADocumento31 páginasNEURONAMiranda MezaAún no hay calificaciones
- MADALINEDocumento17 páginasMADALINEDiego BaesAún no hay calificaciones
- Clase 5Documento40 páginasClase 5henry fsAún no hay calificaciones
- Redes NeuronalesDocumento24 páginasRedes NeuronalesDarkrampageAún no hay calificaciones
- Redes Neuronales ESPEDocumento76 páginasRedes Neuronales ESPEbryanAún no hay calificaciones
- CerebroDocumento71 páginasCerebroAndrea AlvaradoaAún no hay calificaciones
- 2.1. Redes Neuronales. - IntroducciónDocumento37 páginas2.1. Redes Neuronales. - IntroducciónmonicaAún no hay calificaciones
- Clase 7Documento10 páginasClase 7mariana palacios hinestrozaAún no hay calificaciones
- Session11 IADocumento21 páginasSession11 IAraulhuaroteAún no hay calificaciones
- Aplicaciones Con Tecnicas de IADocumento60 páginasAplicaciones Con Tecnicas de IALadislao Acosta CortesAún no hay calificaciones
- Redes Neuronales - ppt-1Documento74 páginasRedes Neuronales - ppt-1Adriana ChicaizaAún no hay calificaciones
- 07MBID Transparencias - 6 Redes NeuronalesDocumento43 páginas07MBID Transparencias - 6 Redes Neuronaleskevin_1234Aún no hay calificaciones
- Expo Redes Neuron Ales ArtificialesDocumento54 páginasExpo Redes Neuron Ales ArtificialesBeimarAún no hay calificaciones
- RNA Uso de Las Funciones de Activación - g1 - FinalDocumento11 páginasRNA Uso de Las Funciones de Activación - g1 - FinalJosé Luis Díaz CotrinaAún no hay calificaciones
- Redes Neuronales ConvolucionalesDocumento12 páginasRedes Neuronales Convolucionalesantosega100% (1)
- REDES NEURONALES Algoritmos de Entrenamiento - RBFDocumento60 páginasREDES NEURONALES Algoritmos de Entrenamiento - RBFEdward Mejia ChAún no hay calificaciones
- Tema 8: Redes Neuronales: Pedro Larra Naga, I Naki Inza, Abdelmalik MoujahidDocumento48 páginasTema 8: Redes Neuronales: Pedro Larra Naga, I Naki Inza, Abdelmalik MoujahidErRobert ChAún no hay calificaciones
- Redes Neuronales - D.C. Alejandro Medina SantiagoDocumento43 páginasRedes Neuronales - D.C. Alejandro Medina SantiagoOctavio Serrano TalaveraAún no hay calificaciones
- Apuntes Redes Neurales Oscar Chang 2014Documento60 páginasApuntes Redes Neurales Oscar Chang 2014ngdaviloAún no hay calificaciones
- Redes Neuronales 2023Documento25 páginasRedes Neuronales 2023Stephanny Cedeño VázquezAún no hay calificaciones
- Tema 8 Redes NeuronalesDocumento20 páginasTema 8 Redes NeuronalesRomero GhyoAún no hay calificaciones
- Voluntario1 RedNeuronalDocumento12 páginasVoluntario1 RedNeuronalDaniel Montesinos CapaceteAún no hay calificaciones
- 6 Cap6SOMDocumento8 páginas6 Cap6SOMDanelysAún no hay calificaciones
- Medicina - Fisiologia General Ida Des SNCDocumento44 páginasMedicina - Fisiologia General Ida Des SNCDANIEL ALEJANDROAún no hay calificaciones
- Neural Network - Toolbox de MatlabDocumento51 páginasNeural Network - Toolbox de MatlabFranco Ramos Vilchez100% (2)
- Tema 7 DeepLearningDocumento37 páginasTema 7 DeepLearningJhonatan HernándezAún no hay calificaciones
- Paper Digitales - 11Documento2 páginasPaper Digitales - 11RUIZ HURTADO ARIANA STHEFANYAún no hay calificaciones
- Trabajo Investigacion EDDocumento11 páginasTrabajo Investigacion EDSandro Larico RamosAún no hay calificaciones
- Practica 2 Electronica - Jose Eusebio - 4-MMP-1 (Recuperado Automáticamente)Documento11 páginasPractica 2 Electronica - Jose Eusebio - 4-MMP-1 (Recuperado Automáticamente)Jose Eusebio Hernandez SanchezAún no hay calificaciones
- Sesion Redes Neuronales v3Documento46 páginasSesion Redes Neuronales v3WILLIAM MARTIN GUTIERREZ SAN MIGUELAún no hay calificaciones
- Clase10 - RedNeuronalDocumento33 páginasClase10 - RedNeuronalLukas JamesAún no hay calificaciones
- Grasa Proktive LCDocumento13 páginasGrasa Proktive LCLucecitho CriAún no hay calificaciones
- ChillerDocumento2 páginasChillerLucecitho CriAún no hay calificaciones
- Probador de Servos Con El Integrado 555Documento14 páginasProbador de Servos Con El Integrado 555Lucecitho CriAún no hay calificaciones
- Aproximacion Por Minimos Cuadrados, Cubicos y CuartosDocumento13 páginasAproximacion Por Minimos Cuadrados, Cubicos y CuartosLucecitho CriAún no hay calificaciones
- Hallazgos en MZDocumento7 páginasHallazgos en MZLucecitho CriAún no hay calificaciones
- Manual BungardDocumento2 páginasManual BungardLucecitho CriAún no hay calificaciones
- Electromagnetismo Serie SchaumDocumento209 páginasElectromagnetismo Serie Schaumseleuco91% (32)
- ACELERACIÓN MecanismosDocumento11 páginasACELERACIÓN MecanismosLucecitho CriAún no hay calificaciones
- 4 - Posición - Desplazamiento-MecanismosDocumento18 páginas4 - Posición - Desplazamiento-MecanismosLucecitho Cri50% (2)
- Electromagnetismo Serie SchaumDocumento209 páginasElectromagnetismo Serie Schaumseleuco91% (32)
- 9 Protocolo USB PDFDocumento29 páginas9 Protocolo USB PDFLucecitho CriAún no hay calificaciones
- Actividad 12Documento5 páginasActividad 12Adrian SotoAún no hay calificaciones
- Analisis de La Pelicula Still Alice.Documento2 páginasAnalisis de La Pelicula Still Alice.Vane CabreraAún no hay calificaciones
- Guia Diario Reflexivo.Documento3 páginasGuia Diario Reflexivo.Rosanna Valdez100% (1)
- Yohansi - Psicologia General - Tarea 5Documento10 páginasYohansi - Psicologia General - Tarea 5yuditAún no hay calificaciones
- Programa para Desarrollar La Memoria SensorialDocumento9 páginasPrograma para Desarrollar La Memoria SensorialJuan Carlos Canales SernaqueAún no hay calificaciones
- Mapa Conceptual La AtenciónDocumento1 páginaMapa Conceptual La AtenciónCarla Pierina Betzabé Tronocoso Paredes100% (1)
- Mapa Conceptual La Memoria 1Documento7 páginasMapa Conceptual La Memoria 1aleyda botelloAún no hay calificaciones
- Unidad 1 - Analisis de Ejercicios - Alexandra BenavidesDocumento13 páginasUnidad 1 - Analisis de Ejercicios - Alexandra BenavidesDiana alexandra Galvez juajinoyAún no hay calificaciones
- Taller Wisc-IV, EniDocumento11 páginasTaller Wisc-IV, EniValentina Arias Mesa100% (1)
- Maria Angelica Mamani BeltranDocumento33 páginasMaria Angelica Mamani BeltranCentro de Desarrollo Psicológico Integral LurínAún no hay calificaciones
- WISC IV Protocolo ErDocumento3 páginasWISC IV Protocolo ErRichard Condori ChampiAún no hay calificaciones
- Principios de La Neurociencia CognitivaDocumento37 páginasPrincipios de La Neurociencia Cognitivaserch100% (1)
- Wisc V Clase 3 - CompressedDocumento44 páginasWisc V Clase 3 - Compressedorianna lisselot martinezAún no hay calificaciones
- Instituto de Educacion Superior Pedagogico PrivadoDocumento21 páginasInstituto de Educacion Superior Pedagogico PrivadoOlivera AngelAún no hay calificaciones
- Grupo 4 - Funciones EjecutivasDocumento37 páginasGrupo 4 - Funciones EjecutivasAllye CressAún no hay calificaciones
- Tarea 1 - Grupo - 41Documento45 páginasTarea 1 - Grupo - 41MALVISMARIAAún no hay calificaciones
- La MemoraDocumento13 páginasLa Memoraledis vergaraAún no hay calificaciones
- Tarea 1 Trabajo GrupalDocumento47 páginasTarea 1 Trabajo GrupalZury MartinezAún no hay calificaciones
- Tema 2 Memoria Corto PlazoDocumento19 páginasTema 2 Memoria Corto PlazoAna EverdeenAún no hay calificaciones
- FLUJOGRAMADocumento3 páginasFLUJOGRAMAJaysara Sharid MOLINA TORRESAún no hay calificaciones
- Sopa de Letras Tipos de MemoriaDocumento2 páginasSopa de Letras Tipos de Memoriapaudodera0% (1)
- Repositorio Definicion de Memoria y OlvidoDocumento19 páginasRepositorio Definicion de Memoria y OlvidoTUTOR Apoyo Educativo y PsicologicoAún no hay calificaciones
- Informe Sobre Coreografía de Manos. Johan Alpízar GómezDocumento3 páginasInforme Sobre Coreografía de Manos. Johan Alpízar GómezJohan Alpizar G50% (4)
- Hoja Perfil WISC IVDocumento3 páginasHoja Perfil WISC IVLucero Angelica Vargas MurilloAún no hay calificaciones
- JuanDocumento15 páginasJuanANA VALERIA CARNEIRO GALLIAún no hay calificaciones
- La MemoriaDocumento3 páginasLa MemoriaSebastian Garay ArizaAún no hay calificaciones
- Evaluación de La Memoria CognitivaDocumento47 páginasEvaluación de La Memoria CognitivaEDUARDO JOSE HERRERAAún no hay calificaciones
- Cuadernillo de Estimulacion CognitivaDocumento53 páginasCuadernillo de Estimulacion CognitivaMaryori Amy Escalante NavarroAún no hay calificaciones
- Conclusiones Descriptivas 4BDocumento9 páginasConclusiones Descriptivas 4BFabian De La Cruz CastroAún no hay calificaciones
- Atkinson y ShiffrinDocumento34 páginasAtkinson y ShiffrinJuan Manriquez VergaraAún no hay calificaciones
- Recupera tu mente, reconquista tu vidaDe EverandRecupera tu mente, reconquista tu vidaCalificación: 5 de 5 estrellas5/5 (9)
- Resetea tu mente. Descubre de lo que eres capazDe EverandResetea tu mente. Descubre de lo que eres capazCalificación: 5 de 5 estrellas5/5 (196)
- Yo Pude, ¡Tú Puedes!: Cómo tomar el control de tu bienestar emocional y convertirte en una persona imparable (edición revisada y expandida)De EverandYo Pude, ¡Tú Puedes!: Cómo tomar el control de tu bienestar emocional y convertirte en una persona imparable (edición revisada y expandida)Calificación: 5 de 5 estrellas5/5 (11)
- Las trampas del miedo: Una visita a las dimensiones biológicas, psicológicas y espirituales para desmantelar el temor paralizante y la tiranía del autosabotajeDe EverandLas trampas del miedo: Una visita a las dimensiones biológicas, psicológicas y espirituales para desmantelar el temor paralizante y la tiranía del autosabotajeCalificación: 5 de 5 estrellas5/5 (61)
- Psicología oscura: Una guía esencial de persuasión, manipulación, engaño, control mental, negociación, conducta humana, PNL y guerra psicológicaDe EverandPsicología oscura: Una guía esencial de persuasión, manipulación, engaño, control mental, negociación, conducta humana, PNL y guerra psicológicaCalificación: 4.5 de 5 estrellas4.5/5 (766)
- La más profunda aceptación: Despertar radical en la vida ordinariaDe EverandLa más profunda aceptación: Despertar radical en la vida ordinariaCalificación: 5 de 5 estrellas5/5 (6)
- Una mente en calma: Técnicas para manejar los pensamientos intrusivosDe EverandUna mente en calma: Técnicas para manejar los pensamientos intrusivosCalificación: 4.5 de 5 estrellas4.5/5 (145)
- Cómo Conversar Con Cualquier Persona: Mejora tus habilidades sociales, desarrolla tu carisma, domina las conversaciones triviales y conviértete en una persona sociable para hacer verdaderos amigos y construir relaciones significativas.De EverandCómo Conversar Con Cualquier Persona: Mejora tus habilidades sociales, desarrolla tu carisma, domina las conversaciones triviales y conviértete en una persona sociable para hacer verdaderos amigos y construir relaciones significativas.Calificación: 5 de 5 estrellas5/5 (54)
- Ansiosos por nada: Menos preocupación, más pazDe EverandAnsiosos por nada: Menos preocupación, más pazCalificación: 4.5 de 5 estrellas4.5/5 (582)
- DMT: La molécula del espíritu (DMT: The Spirit Molecule): Las revolucionarias investigaciones de un medico sobre la biologia de las experiencias misticas y cercanas a la muerteDe EverandDMT: La molécula del espíritu (DMT: The Spirit Molecule): Las revolucionarias investigaciones de un medico sobre la biologia de las experiencias misticas y cercanas a la muerteCalificación: 4.5 de 5 estrellas4.5/5 (19)
- Cómo terminar lo que empiezas: El arte de perseverar, pasar a la acción, ejecutar los planes y tener disciplinaDe EverandCómo terminar lo que empiezas: El arte de perseverar, pasar a la acción, ejecutar los planes y tener disciplinaCalificación: 4.5 de 5 estrellas4.5/5 (6)
- Lee a las personas como un libro: Cómo analizar, entender y predecir las emociones, los pensamientos, las intenciones y los comportamientos de las personasDe EverandLee a las personas como un libro: Cómo analizar, entender y predecir las emociones, los pensamientos, las intenciones y los comportamientos de las personasCalificación: 4.5 de 5 estrellas4.5/5 (3)
- El poder del optimismo: Herramientas para vivir de forma más positivaDe EverandEl poder del optimismo: Herramientas para vivir de forma más positivaCalificación: 5 de 5 estrellas5/5 (16)
- Terapia cognitivo-conductual (TCC) y terapia dialéctico-conductual (TDC): Cómo la TCC, la TDC y la ACT pueden ayudarle a superar la ansiedad, la depresión, y los TOCSDe EverandTerapia cognitivo-conductual (TCC) y terapia dialéctico-conductual (TDC): Cómo la TCC, la TDC y la ACT pueden ayudarle a superar la ansiedad, la depresión, y los TOCSCalificación: 5 de 5 estrellas5/5 (1)
- La violencia invisible: Identificar, entender y superar la violencia psicológica que sufrimos (y ejercemos) en nuestra vida cotidianaDe EverandLa violencia invisible: Identificar, entender y superar la violencia psicológica que sufrimos (y ejercemos) en nuestra vida cotidianaCalificación: 4 de 5 estrellas4/5 (2)
- La madre emocionalmente ausente: Como reconocer y sanar los efectos invisibles del abandono emocional infantilDe EverandLa madre emocionalmente ausente: Como reconocer y sanar los efectos invisibles del abandono emocional infantilAún no hay calificaciones
- Lean Startup: Cómo trabajar de manera más inteligente y no más duro mientras se innova más rápido y se satisface a los clientesDe EverandLean Startup: Cómo trabajar de manera más inteligente y no más duro mientras se innova más rápido y se satisface a los clientesCalificación: 4 de 5 estrellas4/5 (8)
- Ejercicios de Psicología Positiva para aumentar tu felicidadDe EverandEjercicios de Psicología Positiva para aumentar tu felicidadCalificación: 4.5 de 5 estrellas4.5/5 (18)
- Homo antecessor: El nacimiento de una especieDe EverandHomo antecessor: El nacimiento de una especieCalificación: 5 de 5 estrellas5/5 (1)
- Educar la atención: Cómo entrenar esta habilidad en niños y adultosDe EverandEducar la atención: Cómo entrenar esta habilidad en niños y adultosCalificación: 4.5 de 5 estrellas4.5/5 (10)
- Disciplina Mental: Técnicas infalibles para lograr todo lo que te propones y eliminar la pereza y la procrastinación de tu vida para siempreDe EverandDisciplina Mental: Técnicas infalibles para lograr todo lo que te propones y eliminar la pereza y la procrastinación de tu vida para siempreCalificación: 5 de 5 estrellas5/5 (3)