También podría gustarte
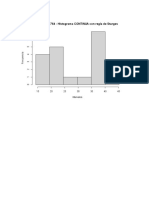
- Trabajo de HistogramaDocumento6 páginasTrabajo de HistogramaRicardo Robledo Díaz50% (2)
- Metodo de Hardy Cross - HidraulicaDocumento45 páginasMetodo de Hardy Cross - HidraulicaNeyron Stalin Zapata100% (1)
- R StudioDocumento42 páginasR Studioangeldcristo100% (6)
- Comandos Básicos STATADocumento7 páginasComandos Básicos STATAbeatlenzo87Aún no hay calificaciones
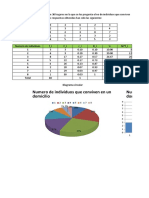
- Se Ha Realizado Una Encuesta en 30 Hogares en La Que Se Les Pregunta El No de Individuos Que ConvivenDocumento12 páginasSe Ha Realizado Una Encuesta en 30 Hogares en La Que Se Les Pregunta El No de Individuos Que ConvivenJose luis Lopez Arevalo75% (4)
- Proyecto Final EstadisticaDocumento9 páginasProyecto Final EstadisticaJose Gonzalez AranedaAún no hay calificaciones
- R AvanzadoDocumento122 páginasR AvanzadoPierre Mort100% (1)
- Estadistica ElementalDocumento15 páginasEstadistica Elementalluis javier dominguez aguiarAún no hay calificaciones
- Tarea MD 2020Documento15 páginasTarea MD 2020Patricio ValdiviaAún no hay calificaciones
- Tarea 1 v.2Documento12 páginasTarea 1 v.2Loreto LoreAún no hay calificaciones
- ESTAD+ìSTICA DESCRIPTIVADocumento141 páginasESTAD+ìSTICA DESCRIPTIVAPeter Aguirre KlugeAún no hay calificaciones
- Medidas - de - Tendencia - Central - ACTIVIDAD 3Documento4 páginasMedidas - de - Tendencia - Central - ACTIVIDAD 3MARIO ADOLFO VALLES MENDOZA0% (1)
- Jose Luis Hernandez - Fase 4Documento11 páginasJose Luis Hernandez - Fase 4Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Presentacion Fase 4 - 3Documento20 páginasPresentacion Fase 4 - 3Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Practica5 SeñalesDocumento12 páginasPractica5 SeñalesAngel Vidals VazquezAún no hay calificaciones
- Alfredo Cosio - Plan de Muestreo Por Variables PDFDocumento20 páginasAlfredo Cosio - Plan de Muestreo Por Variables PDFAlxdangelo Choque FloresAún no hay calificaciones
- Seleccion AtributosrDocumento29 páginasSeleccion AtributosrdavizonnAún no hay calificaciones
- Proyecto de Estadística IIDocumento12 páginasProyecto de Estadística IIcristhian tomas viracocha chilanAún no hay calificaciones
- Intervalo de Confianza para El Coeficiente de CorrelaciónDocumento6 páginasIntervalo de Confianza para El Coeficiente de CorrelaciónSamantha AhumadaAún no hay calificaciones
- Semana 10 Resultados y DiscusionDocumento31 páginasSemana 10 Resultados y DiscusionJhonatan Salazar OrihuelaAún no hay calificaciones
- AR Introducción - 1 - Estadística Aplicada-Spanish by RGDocumento68 páginasAR Introducción - 1 - Estadística Aplicada-Spanish by RGhenryAún no hay calificaciones
- SQL Ciclismo y OtrosDocumento32 páginasSQL Ciclismo y OtrosDavid RoyalesAún no hay calificaciones
- Perfil de VelocidadesDocumento13 páginasPerfil de Velocidadesangel jesus sernaque nunuraAún no hay calificaciones
- R Version 4Documento33 páginasR Version 4Brayan GuzmanAún no hay calificaciones
- Estadísticas en RDocumento10 páginasEstadísticas en RJEAN POOL AXEL SAMANIEGO MENDOZAAún no hay calificaciones
- Clase 1 Análisis de Flujo de PotenciaDocumento28 páginasClase 1 Análisis de Flujo de PotenciaEddie PazosAún no hay calificaciones
- Juan Lorca Proyecto FinalDocumento9 páginasJuan Lorca Proyecto FinalJuan LorcaAún no hay calificaciones
- Ficha Plano InclinadoDocumento6 páginasFicha Plano InclinadoSebastian gutierrez diazAún no hay calificaciones
- Unidad 1-EJERCICIOSDocumento7 páginasUnidad 1-EJERCICIOSRosita HernándezAún no hay calificaciones
- Tarea1 KARLA VIVARDocumento7 páginasTarea1 KARLA VIVARKarla VivarAún no hay calificaciones
- Ejercicios de SimulinkDocumento13 páginasEjercicios de SimulinkEduardo Briones ZambranoAún no hay calificaciones
- Practica3 01Documento30 páginasPractica3 01GH LissetheAún no hay calificaciones
- Tendencia Central Dispersion y FormaDocumento14 páginasTendencia Central Dispersion y FormaLuisa Fer28Aún no hay calificaciones
- Modelamiento y Simulación 3Documento37 páginasModelamiento y Simulación 3luisaAún no hay calificaciones
- Envio - Actividad1 - Evidencia2 V3Documento4 páginasEnvio - Actividad1 - Evidencia2 V3duvan porrasAún no hay calificaciones
- Tablas de FrecuenciaDocumento38 páginasTablas de FrecuenciaYulmer Sneyder Quiquia MangaAún no hay calificaciones
- 4 - HistogramasDocumento35 páginas4 - HistogramasAngelo RamosAún no hay calificaciones
- S2.2 Teoría Cuantitativa - Herramientas de CalidadDocumento62 páginasS2.2 Teoría Cuantitativa - Herramientas de CalidadAndrea GonzalesAún no hay calificaciones
- Prueba de Entrada Control de Procesos 2021Documento4 páginasPrueba de Entrada Control de Procesos 2021Rasec Morales DiazAún no hay calificaciones
- Pasos para El Analisis Estadistico en Investigacion DescriptivaDocumento5 páginasPasos para El Analisis Estadistico en Investigacion DescriptivaEmmanuel LópezAún no hay calificaciones
- Proyecto Estadística Inferencial..Documento13 páginasProyecto Estadística Inferencial..lucinalfredo01Aún no hay calificaciones
- Guía 3 MEDIDAS DE TENDENCIA CENTRALDocumento4 páginasGuía 3 MEDIDAS DE TENDENCIA CENTRALbrandon stiven clavijo torresAún no hay calificaciones
- Series de Tiempo - Webinars PDFDocumento24 páginasSeries de Tiempo - Webinars PDFEduardo Páez DíazAún no hay calificaciones
- Ejercicios Estadística y ProbabilidadDocumento7 páginasEjercicios Estadística y ProbabilidadSofia Montañez VelozaAún no hay calificaciones
- Pasos para El Analisis Estadistico en Investigacion CorrelacionalDocumento5 páginasPasos para El Analisis Estadistico en Investigacion CorrelacionalEmmanuel LópezAún no hay calificaciones
- Ejercicios Clase 070715Documento7 páginasEjercicios Clase 070715jzambranovasAún no hay calificaciones
- Modelo de MarkovDocumento10 páginasModelo de MarkovArturo GarciaAún no hay calificaciones
- HistogramaDocumento25 páginasHistogramaIngREJLAún no hay calificaciones
- Valor en Riesgo (VaR) en R (4) - Basados en Un Proceso ARMA-GARCHDocumento9 páginasValor en Riesgo (VaR) en R (4) - Basados en Un Proceso ARMA-GARCHalvarortunsAún no hay calificaciones
- Mini TabDocumento8 páginasMini TabElisvan Pauccarmayta AlvarezAún no hay calificaciones
- Estadistica Bolo 1Documento31 páginasEstadistica Bolo 1Pedro alavi cruzAún no hay calificaciones
- Distribucion de FrecuenciasDocumento31 páginasDistribucion de FrecuenciasPedro alavi cruzAún no hay calificaciones
- Trabajo Finall WordDocumento20 páginasTrabajo Finall WordUlises Clemente AcevedoAún no hay calificaciones
- Pruebas de Tension y DobladoDocumento16 páginasPruebas de Tension y DobladoJose Octavio riveraAún no hay calificaciones
- Macroeconometria-03-Estacionariedad 1Documento35 páginasMacroeconometria-03-Estacionariedad 1Alexandra Guzman BurgaAún no hay calificaciones
- Herramientas de CalidadDocumento82 páginasHerramientas de CalidadNich ChecaAún no hay calificaciones
- TP 1 Estadistica DescriptivaDocumento30 páginasTP 1 Estadistica DescriptivaFederico IbarraAún no hay calificaciones
- Procesamiento de La InformacionDocumento31 páginasProcesamiento de La InformacionAnllela PerezAún no hay calificaciones
- Bioestadistica 1-4Documento45 páginasBioestadistica 1-4Zujeiry PastranaAún no hay calificaciones
- Detección de bordes: Explorando los límites en la visión por computadoraDe EverandDetección de bordes: Explorando los límites en la visión por computadoraAún no hay calificaciones
- Gráfico de trama digital: Revelando el poder de los gráficos rasterizados digitales en la visión por computadoraDe EverandGráfico de trama digital: Revelando el poder de los gráficos rasterizados digitales en la visión por computadoraAún no hay calificaciones
- Media ModaDocumento4 páginasMedia ModaJaqueline PóndigoAún no hay calificaciones
- Estadistica Ii 4560Documento8 páginasEstadistica Ii 4560Azael GarciaAún no hay calificaciones
- Distribuciones Muestrales Con y Sin ReposiciónDocumento8 páginasDistribuciones Muestrales Con y Sin ReposicióncarlosAún no hay calificaciones
- Bonus EstadisticaDocumento5 páginasBonus Estadisticajuan davidAún no hay calificaciones
- Tarea Ejercicio 25Documento5 páginasTarea Ejercicio 25Edwin Zapata RojasAún no hay calificaciones
- Taller6 3791Documento4 páginasTaller6 3791valentina canterAún no hay calificaciones
- Tarea 1. Primer Parcial. Estadistica 1Documento6 páginasTarea 1. Primer Parcial. Estadistica 1DanielAún no hay calificaciones
- Bank Aleman Media Moda y MedianaDocumento12 páginasBank Aleman Media Moda y Medianaerikagasai.04Aún no hay calificaciones
- Wuolah Free Leccion 2Documento67 páginasWuolah Free Leccion 2paquito mendezAún no hay calificaciones
- Taller Tranbersal de MatemáticaDocumento10 páginasTaller Tranbersal de Matemáticaeduar maldonadoAún no hay calificaciones
- 12.1 Medidas de DispersiónDocumento13 páginas12.1 Medidas de DispersiónDavid Cuenca OrozcoAún no hay calificaciones
- Facultad de Medicina Humana Escuela Profesional de Medicina Humana Facultad de Medicina HumanaDocumento8 páginasFacultad de Medicina Humana Escuela Profesional de Medicina Humana Facultad de Medicina HumanaANA PAULA PIERINA CESPEDES STANPELFELDAún no hay calificaciones
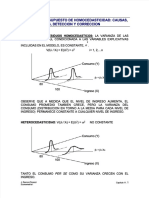
- PDF Capitulo11 Violacion Del Supuesto de Homocedasticidad Causas Consecuencias Deteccion y Correccion - CompressDocumento10 páginasPDF Capitulo11 Violacion Del Supuesto de Homocedasticidad Causas Consecuencias Deteccion y Correccion - CompressJONATHAN FABIAN PINZON CANOAún no hay calificaciones
- Parcial Practico 11 Nvo 2021Documento42 páginasParcial Practico 11 Nvo 2021Marleny CañasAún no hay calificaciones
- Semana 12analis DCLDocumento2 páginasSemana 12analis DCLJuan RiosAún no hay calificaciones
- 5 Medidas de Dispersión Datos No AgrupadosDocumento6 páginas5 Medidas de Dispersión Datos No Agrupadoscalvita2494Aún no hay calificaciones
- Maria Fernanda Giler Valencia M.C Taller2Documento4 páginasMaria Fernanda Giler Valencia M.C Taller2Mafer Giler100% (1)
- Tarea #1 - Estadística Básica RQDocumento12 páginasTarea #1 - Estadística Básica RQJOSE RODRIGO QUEZADA VALLADARESAún no hay calificaciones
- Problemario de Probabilidad y EstadisticaDocumento4 páginasProblemario de Probabilidad y EstadisticaYarely Nicté AguilarAún no hay calificaciones
- Tarea 9 de Estadistica 1.Documento6 páginasTarea 9 de Estadistica 1.Esteban Pichardo MartinezAún no hay calificaciones
- Análisis Previo y Exploratorio de DatosDocumento27 páginasAnálisis Previo y Exploratorio de DatosCLASE PRUEBAAún no hay calificaciones
- Tema 8 EstadisticaDocumento9 páginasTema 8 EstadisticajacintoAún no hay calificaciones
- Laboratorio-3 MegaStat DESCRIPTIVOS 2020Documento10 páginasLaboratorio-3 MegaStat DESCRIPTIVOS 2020Marin Diaz YuberAún no hay calificaciones
- 2 Lección U3 Estadisticos DescriptivosDocumento9 páginas2 Lección U3 Estadisticos Descriptivosevelincita777Aún no hay calificaciones
- Tarea Regresión Lineal SimpleDocumento6 páginasTarea Regresión Lineal SimpleYamileth Jerónimo RomeroAún no hay calificaciones
- TCP6 - Estadistica - 1PDocumento5 páginasTCP6 - Estadistica - 1PErly Escala100% (1)
- Parcial Final Semana FinalDocumento10 páginasParcial Final Semana Finalgiovanni fernandezAún no hay calificaciones
- Examen de EstadisticaDocumento21 páginasExamen de EstadisticaHANSAún no hay calificaciones