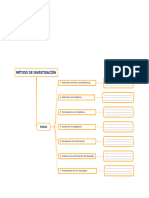
También podría gustarte
- CASO-DANIEL DOBBINS kEVINDocumento2 páginasCASO-DANIEL DOBBINS kEVINLarry Soza100% (4)
- Morozov Estadística AvanzadaDocumento8 páginasMorozov Estadística AvanzadaKiril MorozovAún no hay calificaciones
- Aprendephpconejercicios PDFDocumento128 páginasAprendephpconejercicios PDFMauricio ContrerasAún no hay calificaciones
- El Rumor de Las Casitas Vacias. Claudia LiraDocumento117 páginasEl Rumor de Las Casitas Vacias. Claudia Liraclaudia liraAún no hay calificaciones
- Tarea4 MoisesPortillo 31421148Documento5 páginasTarea4 MoisesPortillo 31421148Moises Portillo PinelAún no hay calificaciones
- A2 20212 Enunciado CASTDocumento7 páginasA2 20212 Enunciado CASTGuanijeiAún no hay calificaciones
- Logica UESDocumento171 páginasLogica UESwillian HernandezAún no hay calificaciones
- EnunciadoDocumento26 páginasEnunciadoEduardo TunAún no hay calificaciones
- Universidad Rey Juan Carlos: PR Acticas de Laboratorio de Ac Ustica y FluidosDocumento38 páginasUniversidad Rey Juan Carlos: PR Acticas de Laboratorio de Ac Ustica y FluidosAyyoub badine louraneAún no hay calificaciones
- Apunte Mat 024 PDFDocumento68 páginasApunte Mat 024 PDFdiegoAún no hay calificaciones
- Solución Ejercicio EstadísticaDocumento23 páginasSolución Ejercicio Estadísticaneomatrix2009Aún no hay calificaciones
- Preinforme de Fisica 4Documento10 páginasPreinforme de Fisica 4kerenAún no hay calificaciones
- Plantilla de Tesis UnacDocumento24 páginasPlantilla de Tesis UnacKeny AnchanteAún no hay calificaciones
- Fisica IIIDocumento78 páginasFisica IIIOscar Enrique Lopez MontañoAún no hay calificaciones
- Psicometría Aplicada Con Jamovi (Elosua, P., y Egaña, M. 2020)Documento124 páginasPsicometría Aplicada Con Jamovi (Elosua, P., y Egaña, M. 2020)PPjamoviAún no hay calificaciones
- Trabajo 2 CECDocumento19 páginasTrabajo 2 CECEmelis Correa VanegasAún no hay calificaciones
- Plantilla TFG Etsii UsDocumento25 páginasPlantilla TFG Etsii UstrabajoAún no hay calificaciones
- Estructuras DiscretasDocumento126 páginasEstructuras DiscretasHector EscobarAún no hay calificaciones
- DL Manual - Com Manual de Ejercicios de Matematicas DiscretasDocumento221 páginasDL Manual - Com Manual de Ejercicios de Matematicas Discretasluis andres beltran soto100% (1)
- Trabajo MLGDocumento36 páginasTrabajo MLGisidora.rusnighiAún no hay calificaciones
- Estadistica y Desiciones PDFDocumento177 páginasEstadistica y Desiciones PDFHolaq Ola OlaAún no hay calificaciones
- U 830557Documento29 páginasU 830557Almanelly Bartolo FloresAún no hay calificaciones
- Plantilla de Tesis UNASAM PDFDocumento25 páginasPlantilla de Tesis UNASAM PDFDamarisHenostrozaAún no hay calificaciones
- Inteligencia Artificial: Razonamiento Aproximado, Redes Bayesianas, Fuzzy Systems & Aprendizaje AutomatizadoDocumento27 páginasInteligencia Artificial: Razonamiento Aproximado, Redes Bayesianas, Fuzzy Systems & Aprendizaje AutomatizadoJoaquin ArroyoAún no hay calificaciones
- Manual de Practicas de Mineria de Datos Usando WEKADocumento21 páginasManual de Practicas de Mineria de Datos Usando WEKARocio ChavezAún no hay calificaciones
- Plantilla de Tesis UNAC 1 PDFDocumento24 páginasPlantilla de Tesis UNAC 1 PDFjmgmAún no hay calificaciones
- Curso IUCE FEES04Documento90 páginasCurso IUCE FEES04Fritjof CapraAún no hay calificaciones
- PFC HTGDocumento110 páginasPFC HTGUnbaAún no hay calificaciones
- Plantilla Trabajo de Grado AunarDocumento27 páginasPlantilla Trabajo de Grado AunarOSCAR ALEXIS QUINTERO L�PEZAún no hay calificaciones
- Notas JavaDocumento178 páginasNotas JavaRaul Erasto Espejel JassoAún no hay calificaciones
- Libro Guia Python3Documento122 páginasLibro Guia Python3ivan hernandez rodriguezAún no hay calificaciones
- Mapa Mental - 202353 - 12741Documento1 páginaMapa Mental - 202353 - 12741Barbara NuñezAún no hay calificaciones
- Eli 221Documento17 páginasEli 221Francisco MorenoAún no hay calificaciones
- Apuntes EstMatDocumento110 páginasApuntes EstMatJorge ChávezAún no hay calificaciones
- Madrid Manual PDFDocumento305 páginasMadrid Manual PDFÓscar RVAún no hay calificaciones
- Folleto OMMEB 2018Documento38 páginasFolleto OMMEB 2018Basshunter HernandezAún no hay calificaciones
- Capitulo 5 LogicaDocumento48 páginasCapitulo 5 LogicaVirginia Hernandez AlcobreAún no hay calificaciones
- HidrologiaDocumento25 páginasHidrologiaMelanio ManchaAún no hay calificaciones
- Apunte ProbaDocumento45 páginasApunte Probajoselep2011Aún no hay calificaciones
- Manual Estadistico PDFDocumento276 páginasManual Estadistico PDFCarlos Isla RiffoAún no hay calificaciones
- Informe CCUDocumento15 páginasInforme CCUamparo fuentesAún no hay calificaciones
- Ruta Bachillerato - Laboratorios de Innovación Educativa-SDocumento894 páginasRuta Bachillerato - Laboratorios de Innovación Educativa-SComunicaciones I. E. MirafloresAún no hay calificaciones
- Modelo de Vision Artificial para La Deteccion Automatica de Colision de Vehiculos en VideovigilanciaDocumento50 páginasModelo de Vision Artificial para La Deteccion Automatica de Colision de Vehiculos en VideovigilanciaNataly Maria VelasquezAún no hay calificaciones
- Aprender R Iniciación y PerfeccionamientoDocumento228 páginasAprender R Iniciación y PerfeccionamientoKinan Kahel KahelAún no hay calificaciones
- Manual de Ejercicios de Matematicas DiscretasDocumento221 páginasManual de Ejercicios de Matematicas DiscretasIsael GonzalezAún no hay calificaciones
- Recopilacion de Informacion Sobre Futbol y Prediccion Bardisa Serrano AdrianDocumento54 páginasRecopilacion de Informacion Sobre Futbol y Prediccion Bardisa Serrano AdrianMarc LinaresAún no hay calificaciones
- MN463 Laboratorio 02Documento42 páginasMN463 Laboratorio 02luis.espinoza.rAún no hay calificaciones
- BookDocumento215 páginasBookKevin VMAún no hay calificaciones
- r5 s3 PDFDocumento24 páginasr5 s3 PDFTutor GenericoAún no hay calificaciones
- Ejercicios Weka PDFDocumento20 páginasEjercicios Weka PDFtodocfeAún no hay calificaciones
- EstadísticaDocumento189 páginasEstadísticaluisanavapuenteAún no hay calificaciones
- A L G E B R A - Estructuras - Algebraicas - Francisco - Rivero - ULADocumento278 páginasA L G E B R A - Estructuras - Algebraicas - Francisco - Rivero - ULApaulysnazareth100% (1)
- Cimco Edit 6 (Es) NodbDocumento186 páginasCimco Edit 6 (Es) NodbMario Mtz RangelAún no hay calificaciones
- Un Curso de Topolog Ia: Demetrio Stojanoff March 6, 2020Documento208 páginasUn Curso de Topolog Ia: Demetrio Stojanoff March 6, 2020José Carlos Hernández RodríguezAún no hay calificaciones
- Ciencia de Datos para Gente SociableDocumento111 páginasCiencia de Datos para Gente Sociablegaston_russo87Aún no hay calificaciones
- Teoria de GaloisDocumento142 páginasTeoria de Galoisjhorckham100% (1)
- Apunte AlumnosDocumento254 páginasApunte AlumnosDarwin AlbornozAún no hay calificaciones
- S01 - APUNTES DOCENTE EDyPDocumento103 páginasS01 - APUNTES DOCENTE EDyPemely mamani100% (1)
- Guias FisicaDocumento62 páginasGuias FisicaDiego Mauricio Gallego MahechaAún no hay calificaciones
- Guias FisicaDocumento58 páginasGuias FisicaDANIELAún no hay calificaciones
- Manual Investigación en NeurocienciasDocumento60 páginasManual Investigación en NeurocienciasNicolasAún no hay calificaciones
- Manual de FisicaDocumento138 páginasManual de Fisicaluis daniel MonterozaAún no hay calificaciones
- Diseño de experimentos. Estrategias y análisis en ciencias e ingenieríasDe EverandDiseño de experimentos. Estrategias y análisis en ciencias e ingenieríasAún no hay calificaciones
- A3 20212 Enunciado ReDocumento5 páginasA3 20212 Enunciado ReGuanijeiAún no hay calificaciones
- A4 20212 Solucion CASTDocumento25 páginasA4 20212 Solucion CASTGuanijeiAún no hay calificaciones
- A4 20212 Enunciado CASTDocumento6 páginasA4 20212 Enunciado CASTGuanijeiAún no hay calificaciones
- Competición: Laliga SantanderDocumento43 páginasCompetición: Laliga SantanderGuanijeiAún no hay calificaciones
- Resultados Web: Servicio Aéreo Especial - Wikipedia, La Enciclopedia LibreDocumento4 páginasResultados Web: Servicio Aéreo Especial - Wikipedia, La Enciclopedia LibreGuanijeiAún no hay calificaciones
- GoogleasdasdDocumento3 páginasGoogleasdasdGuanijeiAún no hay calificaciones
- Eeee EeeeeeDocumento3 páginasEeee EeeeeeGuanijeiAún no hay calificaciones
- AmazonDocumento2 páginasAmazonGuanijeiAún no hay calificaciones
- Sociedad y Democracia SocialistaDocumento3 páginasSociedad y Democracia SocialistaLisandro0% (2)
- 6 Las Esculturas de Bronce de Alejandro ColungaDocumento2 páginas6 Las Esculturas de Bronce de Alejandro ColungaBecky BeckumAún no hay calificaciones
- Actividad de 2 Desarrrollo y CC - SsDocumento3 páginasActividad de 2 Desarrrollo y CC - SsPromoviendo Literatura Con ElicarAún no hay calificaciones
- Cuestionario Capitulo 6Documento3 páginasCuestionario Capitulo 6luisannaAún no hay calificaciones
- Actividad Evluativa Eje 3 CalculoDocumento13 páginasActividad Evluativa Eje 3 CalculoJose Trujillo ValencianoAún no hay calificaciones
- Cuadros ConectoresDocumento2 páginasCuadros ConectoresDoloresAriasRodriguezAún no hay calificaciones
- Ensayo Tema 2 ControlDocumento3 páginasEnsayo Tema 2 ControlJeremias Pineda RamosAún no hay calificaciones
- Rectas Tangentes A Una CircunferenciaDocumento4 páginasRectas Tangentes A Una CircunferenciaErickVelozAún no hay calificaciones
- Ponencia Leandro Alberto Dias, Comisión Derecho PenalDocumento18 páginasPonencia Leandro Alberto Dias, Comisión Derecho PenalLeandro DiasAún no hay calificaciones
- Informe Final-CatedraDocumento36 páginasInforme Final-CatedraMayKol Rosas PomaAún no hay calificaciones
- Diccionario Geología EstructuralDocumento322 páginasDiccionario Geología EstructuralCristian Fabian Mariño MirandaAún no hay calificaciones
- Diseño de Estrategias Didácticas para La Formación de CompetenciasDocumento3 páginasDiseño de Estrategias Didácticas para La Formación de CompetenciasJessica RodriguezAún no hay calificaciones
- Diapositivas de Revision de La Norma E.030Documento70 páginasDiapositivas de Revision de La Norma E.030Gabriel Gabrie80% (5)
- Articulo 288cDocumento2 páginasArticulo 288cNorma TantaAún no hay calificaciones
- El Ius Congens Internacional-ANTONIO GOMEZ ROBLEDODocumento343 páginasEl Ius Congens Internacional-ANTONIO GOMEZ ROBLEDOEdgard GaldosAún no hay calificaciones
- Diferencia de ProporcionesDocumento3 páginasDiferencia de Proporcionescarolina ogazaAún no hay calificaciones
- Apuntes Sobre La ComunicaciónDocumento2 páginasApuntes Sobre La ComunicaciónIngridAmayaCarrascoAún no hay calificaciones
- Informe - Determinación de Calcio en El Vino.Documento8 páginasInforme - Determinación de Calcio en El Vino.Yael MCAún no hay calificaciones
- Sistema Nervioso Autónomo O Neurovegetativo: Mg. Q.F. Madeleine Córdova RuizDocumento16 páginasSistema Nervioso Autónomo O Neurovegetativo: Mg. Q.F. Madeleine Córdova RuizAnonymous C8wpQ8roHmAún no hay calificaciones
- Ser Humano y Desarrollo Sostenible CompletoDocumento5 páginasSer Humano y Desarrollo Sostenible CompletoSeliné Paulino HernándezAún no hay calificaciones
- Orientaciones para La Diversificación Curriculo Nacional Miguel 2019Documento16 páginasOrientaciones para La Diversificación Curriculo Nacional Miguel 2019Jose Luis Salas NavarroAún no hay calificaciones
- Prueba de EntradaDocumento4 páginasPrueba de EntradaLover Jose CántaroAún no hay calificaciones
- Presas Ing - PehovazDocumento108 páginasPresas Ing - PehovazAndy TamayAún no hay calificaciones
- Gerio Cebada Axel Manuel.3ADocumento11 páginasGerio Cebada Axel Manuel.3A4VE PABLO DAMIAN VAQUEROAún no hay calificaciones
- Ejercicio Sexting, Sextorsion, GroomingDocumento4 páginasEjercicio Sexting, Sextorsion, GroomingMAYTE BENITEZAún no hay calificaciones
- El Constitucionalismo de Principios, ¿Entre El Positivismo y El Iusnaturalismo? (A Propósito de El Derecho Dúctil de Gustavo Zagrebelsky)Documento34 páginasEl Constitucionalismo de Principios, ¿Entre El Positivismo y El Iusnaturalismo? (A Propósito de El Derecho Dúctil de Gustavo Zagrebelsky)JPAún no hay calificaciones
- 6tos Lenguaje MarzoDocumento5 páginas6tos Lenguaje MarzoMARIA ANTONIETA PALMA ARBUROAún no hay calificaciones