También podría gustarte
- Secretos SeduccionDocumento61 páginasSecretos Seduccionvixosa100% (1)
- SOM07 TareaDocumento8 páginasSOM07 TareaBeef B0yAún no hay calificaciones
- Función Cuadrática Taller 2Documento13 páginasFunción Cuadrática Taller 2Maria Lorena Quintero Oviedo100% (1)
- Circuito Cerrado de Television IntegraDocumento98 páginasCircuito Cerrado de Television IntegraBlaster Perea100% (1)
- IFS LogisticDocumento25 páginasIFS LogisticvixosaAún no hay calificaciones
- 2021 06 15 Eir 2020 Preguntas ComentadasDocumento57 páginas2021 06 15 Eir 2020 Preguntas ComentadasvixosaAún no hay calificaciones
- Reglamento CE 1099 - 2009, Relativo A La Protección de Los Animales en El Momento de La MatanzaDocumento5 páginasReglamento CE 1099 - 2009, Relativo A La Protección de Los Animales en El Momento de La MatanzavixosaAún no hay calificaciones
- Manual Manipulador Alim. Higiene y Seguridad Alimentaria - 3Documento102 páginasManual Manipulador Alim. Higiene y Seguridad Alimentaria - 3vixosaAún no hay calificaciones
- Presentacion Silliker IFS Editora 241 17Documento42 páginasPresentacion Silliker IFS Editora 241 17vixosaAún no hay calificaciones
- IFS Food v6 Sin AnunciarDocumento18 páginasIFS Food v6 Sin AnunciarvixosaAún no hay calificaciones
- Broiler - PolloDocumento2 páginasBroiler - PollovixosaAún no hay calificaciones
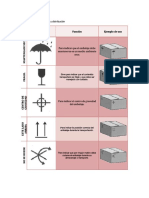
- Simbología de Almacenaje y DistribuciónDocumento2 páginasSimbología de Almacenaje y DistribuciónvixosaAún no hay calificaciones
- Circular - Certificacion - Competenciax1x CERTIFICACION DE LA COMPETENCIA EN BIENESTAR ANIMALDocumento3 páginasCircular - Certificacion - Competenciax1x CERTIFICACION DE LA COMPETENCIA EN BIENESTAR ANIMALvixosaAún no hay calificaciones
- Informe de Visita A Planta Dea de Sacrificio AgrodexDocumento7 páginasInforme de Visita A Planta Dea de Sacrificio AgrodexvixosaAún no hay calificaciones
- Instruccion.117-2012 Sacrificio Por Rito Religioso Sin AturdimientoDocumento2 páginasInstruccion.117-2012 Sacrificio Por Rito Religioso Sin AturdimientovixosaAún no hay calificaciones
- Lenguaje y PensamientoDocumento3 páginasLenguaje y Pensamientovixosa100% (1)
- Catalogo Peliculas Speak UpDocumento5 páginasCatalogo Peliculas Speak UpvixosaAún no hay calificaciones
- Taller de Escritura-DocumentaciónDocumento34 páginasTaller de Escritura-DocumentaciónvixosaAún no hay calificaciones
- Desgloses AdministracionDocumento6 páginasDesgloses AdministracionvixosaAún no hay calificaciones
- Recomendaciones ICMJE Spanish - 2021Documento17 páginasRecomendaciones ICMJE Spanish - 2021vixosaAún no hay calificaciones
- Eir Pediatria Examenes IfsesDocumento12 páginasEir Pediatria Examenes IfsesvixosaAún no hay calificaciones
- Comandos para Revisar ConectividadDocumento5 páginasComandos para Revisar ConectividadJOFFRE MIGUEL PACHECO PACHECOAún no hay calificaciones
- Practica 7 Lab DigitalDocumento16 páginasPractica 7 Lab DigitalSergio RamirezAún no hay calificaciones
- MI GioiaDocumento252 páginasMI GioiarafaelmarcelocarmonaAún no hay calificaciones
- INTRODUCCIÓNDocumento6 páginasINTRODUCCIÓNHermi BurquesAún no hay calificaciones
- Ingles Sin Fronteras Derechos de AutorDocumento2 páginasIngles Sin Fronteras Derechos de AutorJose Salazar AguileraAún no hay calificaciones
- Prueba N 3Documento13 páginasPrueba N 3Paula AndreaAún no hay calificaciones
- Modernización y Migración A La Nube Con Microsoft Azure.Documento14 páginasModernización y Migración A La Nube Con Microsoft Azure.Jorge RomeroAún no hay calificaciones
- Practica 2Documento2 páginasPractica 2Raúl Díaz GutiérrezAún no hay calificaciones
- Mantenimiento PreventivoDocumento12 páginasMantenimiento PreventivoJanki VasquezAún no hay calificaciones
- Groys Boris Bajo SospechaDocumento296 páginasGroys Boris Bajo SospechaLeandro montoya j100% (1)
- GEN2 (Especificaciones Técnicas)Documento1 páginaGEN2 (Especificaciones Técnicas)Lalo HernandezAún no hay calificaciones
- PEU2022 Comunicado1 HLDocumento2 páginasPEU2022 Comunicado1 HLGioSoria88Aún no hay calificaciones
- ManualAccess C02Documento29 páginasManualAccess C02Javier HnAún no hay calificaciones
- PaypalDocumento5 páginasPaypalJorge Andres Vega MateusAún no hay calificaciones
- Instrucciones Distancia Semipresencial 22 23Documento12 páginasInstrucciones Distancia Semipresencial 22 23José Javier Bermúdez HernándezAún no hay calificaciones
- Manual Dso Fnirsi 5012hDocumento22 páginasManual Dso Fnirsi 5012hLuis Raúl Aguilar Castelán.75% (4)
- Evidencias Del Proceso Aulico 2017-2018Documento11 páginasEvidencias Del Proceso Aulico 2017-2018arisleyda hernandezAún no hay calificaciones
- Arduino TecnoDocumento11 páginasArduino Tecnoroberto firulais gonzalesAún no hay calificaciones
- GFPI-F-019 - Guía Transicion - Animacion HTMLDocumento9 páginasGFPI-F-019 - Guía Transicion - Animacion HTMLJorge PinzónAún no hay calificaciones
- 1.3.2 Implementando Teléfonos y Gestionando UsuariosDocumento20 páginas1.3.2 Implementando Teléfonos y Gestionando UsuariosFelipe AndresAún no hay calificaciones
- Sistema Operativo WindowsDocumento18 páginasSistema Operativo WindowsLisbeth FuentesAún no hay calificaciones
- Cuaderno Formato de Recepcion de ResultadosDocumento2 páginasCuaderno Formato de Recepcion de ResultadosAlanGarriazoBernalAún no hay calificaciones
- MFC-9970CDW Brochure PDFDocumento4 páginasMFC-9970CDW Brochure PDFDavidEspi1990Aún no hay calificaciones
- Investigacion Sobe El Manejo de Archivos en JavaDocumento5 páginasInvestigacion Sobe El Manejo de Archivos en JavaJUAN JOSE QUINTERO SANCHEZAún no hay calificaciones
- nx6000 (Modulo 8 Ea Tension Corriente)Documento16 páginasnx6000 (Modulo 8 Ea Tension Corriente)matiasvazquezAún no hay calificaciones
- 5.nuevas Tendencias Tecnológicas en Los Negocios Mercantiles en Colombia Fintech, Blockchain, Big Data, Economía Colaborativa y Su Impacto en Las Relaciones Comerciales. Pontifica UniDocumento26 páginas5.nuevas Tendencias Tecnológicas en Los Negocios Mercantiles en Colombia Fintech, Blockchain, Big Data, Economía Colaborativa y Su Impacto en Las Relaciones Comerciales. Pontifica UniNatalia OrtízAún no hay calificaciones
- Diapositiva de MatematicasDocumento8 páginasDiapositiva de MatematicasLeandra ArteagaAún no hay calificaciones