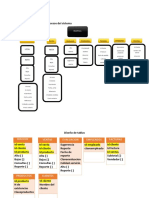
También podría gustarte
- Fase 3 Nadia JimenezDocumento14 páginasFase 3 Nadia Jimenezandrea mondragon leyvaAún no hay calificaciones
- NormalizacionDocumento33 páginasNormalizacionsergio arcilaAún no hay calificaciones
- Ejercicios en Clase 2Documento3 páginasEjercicios en Clase 2davidAún no hay calificaciones
- Insumos - Fase 3 - Base de DatosDocumento15 páginasInsumos - Fase 3 - Base de DatosMonica Yiseth Tigreros Briceño100% (1)
- Definición de EntidadesDocumento2 páginasDefinición de EntidadesSebastian BarahonaAún no hay calificaciones
- Normalizacion-Nahun MontesinoDocumento13 páginasNormalizacion-Nahun MontesinonahunAún no hay calificaciones
- 01 - 02 - Lección 02 - DiapositivasDocumento10 páginas01 - 02 - Lección 02 - DiapositivasFrancisco Murcia MarcialAún no hay calificaciones
- S Ttte : Nit: 8rfu200056-6 Entrega No. 10753201Documento1 páginaS Ttte : Nit: 8rfu200056-6 Entrega No. 10753201lenixAún no hay calificaciones
- Contabgeneral Taller4Documento8 páginasContabgeneral Taller4Jara Mild82% (11)
- RepasoDocumento4 páginasRepasosergio.vera.lobosAún no hay calificaciones
- T1 Gestion Mant. MICSAC Oct.18Documento15 páginasT1 Gestion Mant. MICSAC Oct.18javier vilchez romeroAún no hay calificaciones
- Ej Diagrama E-R y Modelo ConceptualDocumento4 páginasEj Diagrama E-R y Modelo ConceptualJeyson BritoAún no hay calificaciones
- prU12A NormaliDocumento5 páginasprU12A Normaliarnold espinozaAún no hay calificaciones
- Albaran Word Doc Plantilla FormatoDocumento1 páginaAlbaran Word Doc Plantilla FormatoBet FerAún no hay calificaciones
- Datos Del Cliente: Documento para Pago Por VentanillaDocumento1 páginaDatos Del Cliente: Documento para Pago Por VentanillaJonathan Pelaez CortezAún no hay calificaciones
- Base de Datos AlmacenDocumento5 páginasBase de Datos AlmacensahuaroggAún no hay calificaciones
- Julio de La Vegas - Matías, El Apóstol SuplenteDocumento1 páginaJulio de La Vegas - Matías, El Apóstol SuplenteBunker G. AcuñaAún no hay calificaciones
- Anexo 2 Plantilla para Definir EntidadesDocumento1 páginaAnexo 2 Plantilla para Definir EntidadesKelvin Jimenez MangaAún no hay calificaciones
- Diseño Lógico Base Da Datos PDFDocumento3 páginasDiseño Lógico Base Da Datos PDFJavierAún no hay calificaciones
- Tarea 8Documento8 páginasTarea 8Elvira Muñoz DonosoAún no hay calificaciones
- Jonathan Arrieta Vargas (Actividad 2)Documento2 páginasJonathan Arrieta Vargas (Actividad 2)JonathanAún no hay calificaciones
- NM1201N0247058Documento3 páginasNM1201N0247058PABLO SUÁREZ RODRÍGUEZAún no hay calificaciones
- AB Industrial, Molino Coloidal Nuevo CocinaDocumento1 páginaAB Industrial, Molino Coloidal Nuevo CocinaEdgar Josue C. CosAún no hay calificaciones
- Actividad - Noelia Beauty, SL - Factusol - v2021Documento9 páginasActividad - Noelia Beauty, SL - Factusol - v2021Augusto AcostaAún no hay calificaciones
- FactuSOL Importacion Excel CalcDocumento69 páginasFactuSOL Importacion Excel CalcLuis GodoyAún no hay calificaciones
- Tarea 1 Estefania RodriguezDocumento16 páginasTarea 1 Estefania RodriguezESTEFANIA RODRIGUEZ SANCHEZAún no hay calificaciones
- Ht-Plastiment He 98Documento1 páginaHt-Plastiment He 98Nat CaveAún no hay calificaciones
- NM1001N0165480Documento3 páginasNM1001N0165480PABLO SUÁREZ RODRÍGUEZAún no hay calificaciones
- Modelo de Base de Datos para Un Sistema DEFINITIVODocumento9 páginasModelo de Base de Datos para Un Sistema DEFINITIVOMichael Velásquez RodríguezAún no hay calificaciones
- Acta de Recibo Parcial Caso B 1Documento3 páginasActa de Recibo Parcial Caso B 1Gloria Amparo Jimenez TrujilloAún no hay calificaciones
- Tarea 4 - Bases de DatosDocumento8 páginasTarea 4 - Bases de DatosMaru Estrada67% (3)
- EJERCICIOnPRnnCTICO 816499c3be927e0Documento4 páginasEJERCICIOnPRnnCTICO 816499c3be927e0cesar martinez bazaAún no hay calificaciones
- Gescel 013-AC-proyecto Aden Rev2Documento7 páginasGescel 013-AC-proyecto Aden Rev2Aden EirlAún no hay calificaciones
- Tarea s4 BASE DE DATOSDocumento8 páginasTarea s4 BASE DE DATOSPablo SusrezAún no hay calificaciones
- Evidencia 2Documento3 páginasEvidencia 2Realizamos Sus Trabajos UniversitariosAún no hay calificaciones
- ENVACO - PRESUPUESTO CAJA EXT. 10x500 05 05 2023Documento1 páginaENVACO - PRESUPUESTO CAJA EXT. 10x500 05 05 2023Marco AriasAún no hay calificaciones
- 258 Mang BZ-2962Documento1 página258 Mang BZ-2962Jonathan SuarezAún no hay calificaciones
- Normalización de Rango Escalado y Centrado NuevoDocumento19 páginasNormalización de Rango Escalado y Centrado Nuevoshayra espinozaAún no hay calificaciones
- 346 2022 Ingenio La CabañaDocumento1 página346 2022 Ingenio La CabañaKevin Fernando Ramos RivasAún no hay calificaciones
- Sincronización de pedidos multiproductoDocumento4 páginasSincronización de pedidos multiproductodaniel santiago camero hinestrosaAún no hay calificaciones
- Candanedo Alan R4 U2Documento12 páginasCandanedo Alan R4 U2Alan CandAún no hay calificaciones
- RD030084KD-19 - MARQUISA SAC - TTA de 63ADocumento3 páginasRD030084KD-19 - MARQUISA SAC - TTA de 63AYorbi Rodrigues CastilloAún no hay calificaciones
- Datos InmuebleDocumento23 páginasDatos Inmuebleisraelina batistaAún no hay calificaciones
- Acta de Recepcion y Devolucion Gedesa Control CruzadoDocumento1 páginaActa de Recepcion y Devolucion Gedesa Control CruzadoWilmer López PacaAún no hay calificaciones
- PROYECTOFINALBASESDocumento25 páginasPROYECTOFINALBASESAlexander AlfaroAún no hay calificaciones
- 2018 420866 Siga Oc Energia IngenierosDocumento1 página2018 420866 Siga Oc Energia Ingenieroswalter medranoAún no hay calificaciones
- FallabelaDocumento3 páginasFallabelamichsAún no hay calificaciones
- SuministrosProgramaDocumento2 páginasSuministrosProgramaMarcelino Dzul UcanAún no hay calificaciones
- Tarea 13. Ejercicios 5.29 y 5.36Documento11 páginasTarea 13. Ejercicios 5.29 y 5.36Fernanda BetanceAún no hay calificaciones
- S2 Rafael GaliciaDocumento5 páginasS2 Rafael GaliciaOmar Perez SaldivarAún no hay calificaciones
- PROFORMADocumento4 páginasPROFORMAbernaljean4321Aún no hay calificaciones
- Practica 7 - Genesis ReconcoDocumento1 páginaPractica 7 - Genesis ReconcojossuexAún no hay calificaciones
- Informe Notas Credito 2021 ACTUALIZADODocumento30 páginasInforme Notas Credito 2021 ACTUALIZADOIván BolívarAún no hay calificaciones
- Orden de Stork PDFDocumento8 páginasOrden de Stork PDFPaolita PerezAún no hay calificaciones
- 1 - 107101 - 20201125120727 - fv-292 - Suroeste - Venta de Activos A LatincoDocumento1 página1 - 107101 - 20201125120727 - fv-292 - Suroeste - Venta de Activos A LatincoDiego VelezAún no hay calificaciones
- Ejercicios de Las Formas Normales - Base de DatosDocumento14 páginasEjercicios de Las Formas Normales - Base de DatosMarcial Quispe Valle0% (1)
- Casos de Data MartDocumento4 páginasCasos de Data MartJonathanAún no hay calificaciones
- Lab 04Documento9 páginasLab 04Elmer PérezAún no hay calificaciones
- Lab 01Documento13 páginasLab 01Elmer PérezAún no hay calificaciones
- Lab 05Documento8 páginasLab 05Elmer PérezAún no hay calificaciones
- Lab 02Documento8 páginasLab 02Elmer PérezAún no hay calificaciones
- Lab 03Documento7 páginasLab 03Elmer PérezAún no hay calificaciones
- Power Bi IntermedioDocumento1 páginaPower Bi IntermedioElmer PérezAún no hay calificaciones
- Eliminacion y Actualizacion CascadaDocumento5 páginasEliminacion y Actualizacion CascadaElmer PérezAún no hay calificaciones
- Lab 01Documento5 páginasLab 01Elmer PérezAún no hay calificaciones
- Cap 01.en - EsDocumento10 páginasCap 01.en - EsElmer PérezAún no hay calificaciones
- Clase4 Desing ThinkingDocumento7 páginasClase4 Desing ThinkingClaudia Marcela García OrtegónAún no hay calificaciones
- Software Requirements - En.esDocumento1 páginaSoftware Requirements - En.esElmer PérezAún no hay calificaciones
- Requirements Matrix - En.esDocumento1 páginaRequirements Matrix - En.esElmer PérezAún no hay calificaciones
- Interviews en EsDocumento6 páginasInterviews en EsElmer PérezAún no hay calificaciones
- CFD Formatov2Documento5 páginasCFD Formatov2Elmer PérezAún no hay calificaciones
- Clase2 Desing ThinkingDocumento11 páginasClase2 Desing ThinkingClaudia Marcela García OrtegónAún no hay calificaciones
- Clase5 Desing ThinkingDocumento9 páginasClase5 Desing ThinkingClaudia Marcela García OrtegónAún no hay calificaciones
- Clase1 Desing ThinkingDocumento10 páginasClase1 Desing ThinkingClaudia Marcela García OrtegónAún no hay calificaciones
- Clase3 Desing ThinkingDocumento9 páginasClase3 Desing ThinkingClaudia Marcela García OrtegónAún no hay calificaciones
- Requisitos Sistema Asistencia en LaravelDocumento6 páginasRequisitos Sistema Asistencia en LaravelLuisMiguelAún no hay calificaciones
- Ejercicios Linux - 02Documento11 páginasEjercicios Linux - 02PEREZ RIVAS YESSICAAún no hay calificaciones
- Artículo Inteligencia de Negocios Grupo N.°1Documento6 páginasArtículo Inteligencia de Negocios Grupo N.°1Guru RachellAún no hay calificaciones
- Actividad 3.3.2 - Config Básica Switch Respuestas Yesid Julian Pinilla RodriguezDocumento6 páginasActividad 3.3.2 - Config Básica Switch Respuestas Yesid Julian Pinilla RodriguezYesid Julian Pinilla RodriguezAún no hay calificaciones
- Informe de Gestion de DatosDocumento9 páginasInforme de Gestion de DatosJosé Flores QuispeAún no hay calificaciones
- Fase3 BDavanzadaDocumento17 páginasFase3 BDavanzadaHeather YelettniAún no hay calificaciones
- Ejercicios con pilas y colas en expresiones matemáticasDocumento19 páginasEjercicios con pilas y colas en expresiones matemáticasRafael CordovaAún no hay calificaciones
- Qué Es Central FinanceDocumento3 páginasQué Es Central FinanceJuanAún no hay calificaciones
- Unidad 05Documento34 páginasUnidad 05computacion grupo 1Aún no hay calificaciones
- 00 PresentaciónDocumento12 páginas00 PresentaciónAiquipa Lozano JGAún no hay calificaciones
- Roles y Permisos - ABDDocumento7 páginasRoles y Permisos - ABDFrancisco JavierAún no hay calificaciones
- Libro RailsDocumento428 páginasLibro RailsJehú GuillénAún no hay calificaciones
- Mejores Prácticas de DataWarehouse Con SQL ServerDocumento66 páginasMejores Prácticas de DataWarehouse Con SQL ServerDaniel AvilaAún no hay calificaciones
- CV 2022 SpanishDocumento1 páginaCV 2022 SpanishKevin SuazaAún no hay calificaciones
- Clase 2 - Instalación y Configuración Del Entorno PDFDocumento50 páginasClase 2 - Instalación y Configuración Del Entorno PDFJuan GraciaAún no hay calificaciones
- GA2-220501093-AA1-EV03 Elaboración de Historias de Usuario Del ProyectoDocumento5 páginasGA2-220501093-AA1-EV03 Elaboración de Historias de Usuario Del ProyectoANDRÉS GARCÍAAún no hay calificaciones
- Instalar en Ubuntu Apache, PHP, MySQL y PhpMyAdminDocumento3 páginasInstalar en Ubuntu Apache, PHP, MySQL y PhpMyAdminAlejandro Diego Sansalone GAún no hay calificaciones
- Material ApoyoDocumento10 páginasMaterial ApoyoGinna BurbanoAún no hay calificaciones
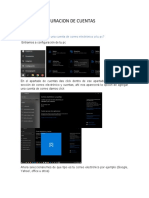
- Tema Configuracion de Cuentas Ejercicios y Preguntas Con RespuestasDocumento8 páginasTema Configuracion de Cuentas Ejercicios y Preguntas Con RespuestasCruz Talese MicheleAún no hay calificaciones
- Mongodb Architecture Guide July 2018Documento17 páginasMongodb Architecture Guide July 2018Fernando GuerraAún no hay calificaciones
- Lab3 T2Documento3 páginasLab3 T2Sergio Driss Melèndez MartìnezAún no hay calificaciones
- Java MVC, DAO y DTODocumento13 páginasJava MVC, DAO y DTOEduardo YoungAún no hay calificaciones
- U5. Lenguaje SQLDocumento3 páginasU5. Lenguaje SQLXina Callisaya LimachiAún no hay calificaciones
- ARI - Sesion 2. 1.1. Al 1.4.Documento48 páginasARI - Sesion 2. 1.1. Al 1.4.msantacruzrAún no hay calificaciones
- Material de Apoyo - Microsoft Access 2003 - IDocumento127 páginasMaterial de Apoyo - Microsoft Access 2003 - IElharPowersAún no hay calificaciones
- Clase 21 - Manejo de Archivos RealesDocumento63 páginasClase 21 - Manejo de Archivos RealesMiguel La RoccaAún no hay calificaciones
- Raul NavascuesDocumento2 páginasRaul Navascuesrnavascv5Aún no hay calificaciones
- Arquímedes y funcionalidad de impresiónDocumento29 páginasArquímedes y funcionalidad de impresiónAndres Navarro MoralAún no hay calificaciones
- 12 Reglas de BDDDocumento3 páginas12 Reglas de BDDTavo RomanAún no hay calificaciones
- Gesti N en Procesos de Negocio Modalidad de Ex Menes Semana 3 PDFDocumento2 páginasGesti N en Procesos de Negocio Modalidad de Ex Menes Semana 3 PDFEDSON ALEXANDER JARA CANTUAún no hay calificaciones
- Estructuras de Datos Básicas: Programación orientada a objetos con JavaDe EverandEstructuras de Datos Básicas: Programación orientada a objetos con JavaCalificación: 5 de 5 estrellas5/5 (1)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (116)
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- Excel 2021 y 365 Paso a Paso: Paso a PasoDe EverandExcel 2021 y 365 Paso a Paso: Paso a PasoCalificación: 5 de 5 estrellas5/5 (12)
- Minería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásDe EverandMinería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásCalificación: 4.5 de 5 estrellas4.5/5 (4)
- Investigación de operaciones: Conceptos fundamentalesDe EverandInvestigación de operaciones: Conceptos fundamentalesCalificación: 4.5 de 5 estrellas4.5/5 (2)
- ¿Cómo piensan las máquinas?: Inteligencia artificial para humanosDe Everand¿Cómo piensan las máquinas?: Inteligencia artificial para humanosCalificación: 5 de 5 estrellas5/5 (1)
- LAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.De EverandLAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.Calificación: 4.5 de 5 estrellas4.5/5 (54)
- ChatGPT Ganar Dinero Desde Casa Nunca fue tan Fácil Las 7 mejores fuentes de ingresos pasivos con Inteligencia Artificial (IA): libros, redes sociales, marketing digital, programación...De EverandChatGPT Ganar Dinero Desde Casa Nunca fue tan Fácil Las 7 mejores fuentes de ingresos pasivos con Inteligencia Artificial (IA): libros, redes sociales, marketing digital, programación...Calificación: 5 de 5 estrellas5/5 (4)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- El trading online de una forma sencilla: Cómo convertirse en un inversionista online y descubrir las bases para lograr un trading de éxitoDe EverandEl trading online de una forma sencilla: Cómo convertirse en un inversionista online y descubrir las bases para lograr un trading de éxitoCalificación: 4 de 5 estrellas4/5 (30)
- APLICACIONES PRACTICAS CON EXCELDe EverandAPLICACIONES PRACTICAS CON EXCELCalificación: 4.5 de 5 estrellas4.5/5 (6)
- Auditoría de seguridad informática: Curso prácticoDe EverandAuditoría de seguridad informática: Curso prácticoCalificación: 5 de 5 estrellas5/5 (1)
- Organizaciones Exponenciales: Por qué existen nuevas organizaciones diez veces más escalables y rentables que la tuya (y qué puedes hacer al respecto)De EverandOrganizaciones Exponenciales: Por qué existen nuevas organizaciones diez veces más escalables y rentables que la tuya (y qué puedes hacer al respecto)Calificación: 4.5 de 5 estrellas4.5/5 (11)
- La biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetDe EverandLa biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetCalificación: 5 de 5 estrellas5/5 (7)
- El mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosDe EverandEl mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosCalificación: 5 de 5 estrellas5/5 (2)
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- Aprender Illustrator 2020 con 100 ejercicios prácticosDe EverandAprender Illustrator 2020 con 100 ejercicios prácticosAún no hay calificaciones
- Gestión de Proyectos con Microsoft Project 2013: Software de gestión de proyectosDe EverandGestión de Proyectos con Microsoft Project 2013: Software de gestión de proyectosCalificación: 5 de 5 estrellas5/5 (3)
- AngularJS: Conviértete en el profesional que las compañías de software necesitan.De EverandAngularJS: Conviértete en el profesional que las compañías de software necesitan.Calificación: 3.5 de 5 estrellas3.5/5 (3)
- Guía De Hacking De Computadora Para Principiantes: Cómo Hackear Una Red Inalámbrica Seguridad Básica Y Pruebas De Penetración Kali Linux Su Primer HackDe EverandGuía De Hacking De Computadora Para Principiantes: Cómo Hackear Una Red Inalámbrica Seguridad Básica Y Pruebas De Penetración Kali Linux Su Primer HackAún no hay calificaciones
- Manual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasDe EverandManual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasCalificación: 4.5 de 5 estrellas4.5/5 (14)