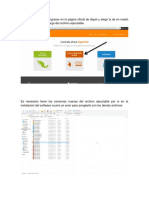
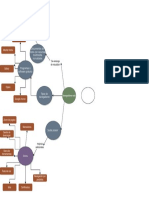
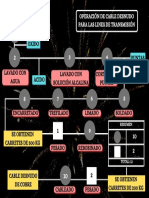
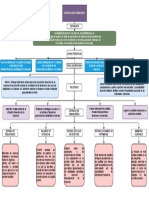
También podría gustarte
- Final 2 Gerencia de Op 30 de Julio 2021Documento2 páginasFinal 2 Gerencia de Op 30 de Julio 2021Orlando DiaAún no hay calificaciones
- Quinta Parte Del Segundo Trabajo EstadisticaDocumento17 páginasQuinta Parte Del Segundo Trabajo Estadisticaangelo pialuisa100% (1)
- PAULVALVERDETRANSDocumento6 páginasPAULVALVERDETRANSDavidAún no hay calificaciones
- Diseño de Experimento TruchasDocumento24 páginasDiseño de Experimento Truchasoracio riveraAún no hay calificaciones
- TAREAESTADISTICADocumento16 páginasTAREAESTADISTICAEdwinPerez100% (2)
- Organizador Grafico Cuantitative Methods in America AirlinesDocumento3 páginasOrganizador Grafico Cuantitative Methods in America AirlinesLaura Maria Navarro AbregoAún no hay calificaciones
- Pablollumiluisa Estadistica 15Documento14 páginasPablollumiluisa Estadistica 15Pablo LlumiluisaAún no hay calificaciones
- Caso 1 EjercicioDocumento6 páginasCaso 1 Ejercicioallan muñoz100% (1)
- 3Documento2 páginas3Marilyn G.100% (1)
- Unidad 1 Ejercicio 6 - 10Documento6 páginasUnidad 1 Ejercicio 6 - 10Teffy ZkyAún no hay calificaciones
- Tarea 5 4.13 4.16 4.25 4.39 y 4.49Documento11 páginasTarea 5 4.13 4.16 4.25 4.39 y 4.49Yenifer PerezAún no hay calificaciones
- Quiz - Modelo de TransporteDocumento1 páginaQuiz - Modelo de TransporteOnly Memes100% (1)
- 11 Razones FinancierasDocumento13 páginas11 Razones FinancierasMIRNA PATRICIA FUENTES DELGADOAún no hay calificaciones
- NATTDocumento13 páginasNATTMirëyä QuishpeAún no hay calificaciones
- Practica 05Documento6 páginasPractica 05Llanos Guevara IvanAún no hay calificaciones
- Ejer Cici OsDocumento24 páginasEjer Cici OsKaren GarayAún no hay calificaciones
- Inv de Operaciones II CorteDocumento11 páginasInv de Operaciones II CorteMarcela Contreras CucaitaAún no hay calificaciones
- Actividades de Debate 4Documento91 páginasActividades de Debate 4Luis Bermeo100% (1)
- Trbajo Investigacion de OperacionesDocumento7 páginasTrbajo Investigacion de OperacionesMAURICIO GONZALEZAún no hay calificaciones
- Ej 23 25Documento3 páginasEj 23 25Dayana AriasAún no hay calificaciones
- Informe de Pronosticos Con EstacionalidadDocumento12 páginasInforme de Pronosticos Con EstacionalidadEdy Wotzbely Vásquez Gómez100% (1)
- Ejercicio 7-41..Documento4 páginasEjercicio 7-41..Melany CarrascoAún no hay calificaciones
- El Cambio S.A.Documento2 páginasEl Cambio S.A.Kevin BustamanteAún no hay calificaciones
- Le1 PT PDFDocumento2 páginasLe1 PT PDFMiguel LimonAún no hay calificaciones
- Ejercicio 4.41Documento3 páginasEjercicio 4.41Joan Rizos Puerto33% (3)
- Ejercicio 11 4 5Documento3 páginasEjercicio 11 4 5Carlos ChavaAún no hay calificaciones
- Deber OperativaDocumento10 páginasDeber OperativaKaren VelezAún no hay calificaciones
- Metodo SimplexDocumento13 páginasMetodo Simplexemersonblas0% (1)
- Problemas de Gestion TácticaDocumento2 páginasProblemas de Gestion TácticaPaul Lopez0% (4)
- Taller de EstadisticaDocumento26 páginasTaller de EstadisticaDenise Yissel MoralesAún no hay calificaciones
- Baterías DisBatteryDocumento2 páginasBaterías DisBatteryTinkyWinkyAún no hay calificaciones
- Analisis EconomicoDocumento3 páginasAnalisis EconomicoGuillermo Art20% (5)
- Cuestionario 2 - Noboa - Solis - Ordoñez - UrquizaDocumento4 páginasCuestionario 2 - Noboa - Solis - Ordoñez - UrquizaANTHONY FRANKLIN ORDO�EZ RIOSAún no hay calificaciones
- Deber GestionDocumento5 páginasDeber GestionRafael PatricioAún no hay calificaciones
- Expansión de negocio para maximizar ganancias a largo plazoDocumento1 páginaExpansión de negocio para maximizar ganancias a largo plazonata0% (1)
- D5.-Una Compañía Conservera Opera Dos Plantas de Conservas. Los Productores Están DispuestosDocumento11 páginasD5.-Una Compañía Conservera Opera Dos Plantas de Conservas. Los Productores Están DispuestosXavier SevillaAún no hay calificaciones
- Guía 3 Gestión de OperacionesDocumento6 páginasGuía 3 Gestión de OperacionesJavier Andres Avila0% (2)
- Ejercicio 7Documento3 páginasEjercicio 7Rosani AguilarAún no hay calificaciones
- Tarea 2 Metodo GraficoDocumento4 páginasTarea 2 Metodo GraficoZenenVelasco100% (1)
- Actividad 2 Probabilidad - 1Documento2 páginasActividad 2 Probabilidad - 1Alec FonsecaAún no hay calificaciones
- InventariosDocumento5 páginasInventariosNicole Yanez33% (3)
- Deber 4 IODocumento13 páginasDeber 4 IOInti Burga100% (1)
- Examen INVOPEDocumento2 páginasExamen INVOPEluis anthony jamill avila sanchezAún no hay calificaciones
- Programacion LinealDocumento6 páginasProgramacion LinealOsdalys Arauz Aguilar100% (2)
- TEMA 2 - EJERCICIOS+completos - EnunciadosDocumento7 páginasTEMA 2 - EJERCICIOS+completos - EnunciadosDavid VictoresAún no hay calificaciones
- Tipo de Fertilizante I II III 0.06X+0.08Y+0.12Z 0.08 A 0.06X+0.12Y+0.08Z 0.08 B 0.08X+0.04Y+0.12Z 0.08 C Producto QuímicoDocumento5 páginasTipo de Fertilizante I II III 0.06X+0.08Y+0.12Z 0.08 A 0.06X+0.12Y+0.08Z 0.08 B 0.08X+0.04Y+0.12Z 0.08 C Producto QuímicoJennifer RodríguezAún no hay calificaciones
- CaratulaDocumento27 páginasCaratulaPaul Diaz Chire100% (2)
- Farris Billiard SupplyDocumento1 páginaFarris Billiard SupplyroselyAún no hay calificaciones
- MKT tapiz SupertrexDocumento2 páginasMKT tapiz SupertrexWagner Mercado Ulloa67% (3)
- Libro Chase - Ejercicio 19Documento1 páginaLibro Chase - Ejercicio 19David Muzo BombónAún no hay calificaciones
- Ejer Cici OsDocumento9 páginasEjer Cici OsEdu Enriquez0% (3)
- LB 5 OperativaDocumento8 páginasLB 5 OperativaArnold Graus NeciosupAún no hay calificaciones
- Taller Financiera 2Documento4 páginasTaller Financiera 2Panchito Sinailin AgilaAún no hay calificaciones
- Modelos pronósticos cualitativos y cuantitativosDocumento7 páginasModelos pronósticos cualitativos y cuantitativosAlexis Gf0% (1)
- Tarea Semana 2 Capitulo 2Documento3 páginasTarea Semana 2 Capitulo 2Adriana ContrerasAún no hay calificaciones
- Ruiz Jhonatan-Taller 5 - Microeconomia IIDocumento3 páginasRuiz Jhonatan-Taller 5 - Microeconomia IIjhonatan ruiz0% (1)
- Modelo de transporte de mesas de madera entre ciudadesDocumento14 páginasModelo de transporte de mesas de madera entre ciudadesLuis FernandoAún no hay calificaciones
- Analisis de Regresion Lineal TareaDocumento12 páginasAnalisis de Regresion Lineal TareaLuis OrtezAún no hay calificaciones
- Regresion LinealDocumento7 páginasRegresion Linealblanco3av1Aún no hay calificaciones
- Regresion CorrelacionDocumento5 páginasRegresion Correlacionreynaldo1111Aún no hay calificaciones
- EJERCICIODocumento2 páginasEJERCICIOalexisAún no hay calificaciones
- CalculoDocumento13 páginasCalculoalexisAún no hay calificaciones
- Dibujo 2Documento1 páginaDibujo 2alexisAún no hay calificaciones
- Costo BeneficioDocumento2 páginasCosto BeneficioalexisAún no hay calificaciones
- DINAMICADocumento3 páginasDINAMICAalexisAún no hay calificaciones
- ImpactoPetróleoMxDocumento2 páginasImpactoPetróleoMxalexisAún no hay calificaciones
- DirecciónDocumento1 páginaDirecciónalexisAún no hay calificaciones
- Actividades para liberar estrésDocumento1 páginaActividades para liberar estrésalexisAún no hay calificaciones
- Instalación de Aspel en 10 pasosDocumento5 páginasInstalación de Aspel en 10 pasosalexisAún no hay calificaciones
- Software de GestionDocumento12 páginasSoftware de GestionalexisAún no hay calificaciones
- Navegadores web y sus característicasDocumento1 páginaNavegadores web y sus característicasalexisAún no hay calificaciones
- Sistema de Aplicación EjecutivaDocumento2 páginasSistema de Aplicación EjecutivaalexisAún no hay calificaciones
- Dibujo 2Documento1 páginaDibujo 2alexisAún no hay calificaciones
- Actos de Comercio, Requisitos para Ser Comerciante, Obligaciones de Los Comerciantes y Auxiliares Del ComercioDocumento2 páginasActos de Comercio, Requisitos para Ser Comerciante, Obligaciones de Los Comerciantes y Auxiliares Del ComercioalexisAún no hay calificaciones
- Expocicion 30%Documento13 páginasExpocicion 30%alexisAún no hay calificaciones
- EjercicioDocumento6 páginasEjercicioalexisAún no hay calificaciones
- DiagramaDocumento1 páginaDiagramaalexisAún no hay calificaciones
- GLOSARIODocumento3 páginasGLOSARIOalexisAún no hay calificaciones
- Ejercicio 1Documento1 páginaEjercicio 1alexisAún no hay calificaciones
- Investigacion 25Documento6 páginasInvestigacion 25alexisAún no hay calificaciones
- Ejercicio 3.1Documento1 páginaEjercicio 3.1alexisAún no hay calificaciones
- JustificaciónDocumento1 páginaJustificaciónalexisAún no hay calificaciones
- GLOSARIODocumento3 páginasGLOSARIOalexisAún no hay calificaciones
- EjerciciosDocumento4 páginasEjerciciosalexisAún no hay calificaciones
- Autoevaluacion y Preguntas de Analisis Cap 12Documento7 páginasAutoevaluacion y Preguntas de Analisis Cap 12alexis100% (1)
- Mapa ConceptualDocumento1 páginaMapa ConceptualalexisAún no hay calificaciones
- Ejercicio 1Documento1 páginaEjercicio 1alexisAún no hay calificaciones
- Ejercicio 1Documento7 páginasEjercicio 1alexisAún no hay calificaciones
- Autoevaluación Preguntas para Analisis y Ejercicio 6.18Documento6 páginasAutoevaluación Preguntas para Analisis y Ejercicio 6.18alexisAún no hay calificaciones
- Autoevaluación Preguntas para Analisis y Ejercicio 6.18Documento6 páginasAutoevaluación Preguntas para Analisis y Ejercicio 6.18alexisAún no hay calificaciones
- Inferencia Estadística Aplicada A La EconomíaDocumento47 páginasInferencia Estadística Aplicada A La EconomíaVicerrectorado de Investigación100% (1)
- Planillas Deflexiones SR-SB-BG - Hogg SimplificadoDocumento6 páginasPlanillas Deflexiones SR-SB-BG - Hogg SimplificadoRamon JohnsonAún no hay calificaciones
- Estimador de Newey-WestDocumento1 páginaEstimador de Newey-WestJavier Garcia RajoyAún no hay calificaciones
- Trabajo en Clase 2-06-2021...Documento11 páginasTrabajo en Clase 2-06-2021...daniela fernanda gualan pacchaAún no hay calificaciones
- Taller EstadisticaDocumento6 páginasTaller EstadisticaJuan Sebastian ForeroAún no hay calificaciones
- Ejercicios de FiabilidadDocumento3 páginasEjercicios de FiabilidadAna Leon Vega100% (1)
- Vida útil anaquel bebidasDocumento10 páginasVida útil anaquel bebidasPamela SimbañaAún no hay calificaciones
- Dificultades que obstaculizan el rendimiento estudiantil UTPDocumento20 páginasDificultades que obstaculizan el rendimiento estudiantil UTPMiguel RodasAún no hay calificaciones
- Intervalos de confianza para peso de tortasDocumento7 páginasIntervalos de confianza para peso de tortasAndres MilquezAún no hay calificaciones
- Los CuartilesDocumento6 páginasLos CuartilesJAVIER ISTAÑAAún no hay calificaciones
- Resumenes LaboratoriosDocumento23 páginasResumenes LaboratoriosTANNIA MURIEL QUIROZ OLMOSAún no hay calificaciones
- Unidad 4 Mínimos CuadradosDocumento57 páginasUnidad 4 Mínimos CuadradosMayra Espinel CamejoAún no hay calificaciones
- Introducción a conceptos básicos de estadísticaDocumento7 páginasIntroducción a conceptos básicos de estadísticaLis DelgadoAún no hay calificaciones
- Diabetes Tipo 2: Análisis de Datos de Glucosa SanguíneaDocumento6 páginasDiabetes Tipo 2: Análisis de Datos de Glucosa Sanguíneasairo panamaAún no hay calificaciones
- Estadistica Inferencial Intent1Documento5 páginasEstadistica Inferencial Intent1Milena PradaAún no hay calificaciones
- Ejemplo Variables CuantitativaDocumento9 páginasEjemplo Variables Cuantitativaoscar pavaAún no hay calificaciones
- Capítulo 9 Intervalos de ConfianzaDocumento8 páginasCapítulo 9 Intervalos de ConfianzaFernando Daniel Mendez BocanegraAún no hay calificaciones
- 1.7 Predicción Con Técnicas Numéricas.Documento28 páginas1.7 Predicción Con Técnicas Numéricas.Tratos ContratosAún no hay calificaciones
- N 144 X 160 10 A) Para: 0.95Documento3 páginasN 144 X 160 10 A) Para: 0.95ALVARO ELAR RIVAS CABRERAAún no hay calificaciones
- Cuaderno de Trabajo - PcoDocumento96 páginasCuaderno de Trabajo - PcoSilvia UtaniAún no hay calificaciones
- Tarea Segunda Unidad EstadisticaDocumento12 páginasTarea Segunda Unidad EstadisticaRosmeri VilchesAún no hay calificaciones
- Reciclaje residuos Lima 2021Documento32 páginasReciclaje residuos Lima 2021Kevin Julio Huayllane SolisAún no hay calificaciones
- Tcc-Est 2Documento3 páginasTcc-Est 2YINERIS MONTERO GOMEZAún no hay calificaciones
- An Álisis de Regresión y Correlación Múltiple Modelo de Regresi Ón Lineal MúltipleDocumento3 páginasAn Álisis de Regresión y Correlación Múltiple Modelo de Regresi Ón Lineal MúltipleKarina MarisolAún no hay calificaciones
- Esta Di SticaDocumento4 páginasEsta Di SticaKathy ChicaizaAún no hay calificaciones
- Ejercicios Prácticos Sobre Elaboración de Intervalos de Confianza e Interpretación de Resultados - GRUPO 20Documento5 páginasEjercicios Prácticos Sobre Elaboración de Intervalos de Confianza e Interpretación de Resultados - GRUPO 20Andrés Idrovo100% (1)
- CalProListNumPyDocumento5 páginasCalProListNumPyAsdrubal Joel Luna ValenzuelaAún no hay calificaciones
- Orca Share Media1553738348593Documento55 páginasOrca Share Media1553738348593Iván RodrigoAún no hay calificaciones
- MODULO 2 Analisis BivariadoDocumento34 páginasMODULO 2 Analisis BivariadoKaterin J Lugo AAún no hay calificaciones
- Ejercicios Regresion-CorrelaciónDocumento13 páginasEjercicios Regresion-CorrelaciónCarlos Morillo MirandaAún no hay calificaciones