100% encontró este documento útil (1 voto)
191 vistas22 páginasComandos SQL Server Esenciales
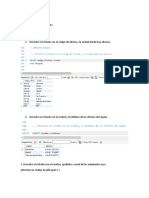
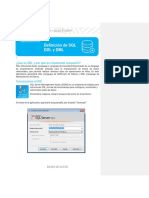
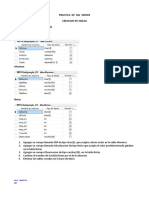
Este documento contiene instrucciones SQL para crear y manipular bases de datos y tablas, como crear una base de datos y tablas, insertar y eliminar registros, actualizar datos, y realizar consultas utilizando joins, variables, funciones y procedimientos almacenados. También incluye un ejemplo de procedimiento almacenado para reasignar clientes y eliminar un vendedor.
Cargado por
Miguel Garcia OchoaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como DOCX, PDF, TXT o lee en línea desde Scribd
100% encontró este documento útil (1 voto)
191 vistas22 páginasComandos SQL Server Esenciales
Este documento contiene instrucciones SQL para crear y manipular bases de datos y tablas, como crear una base de datos y tablas, insertar y eliminar registros, actualizar datos, y realizar consultas utilizando joins, variables, funciones y procedimientos almacenados. También incluye un ejemplo de procedimiento almacenado para reasignar clientes y eliminar un vendedor.
Cargado por
Miguel Garcia OchoaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como DOCX, PDF, TXT o lee en línea desde Scribd