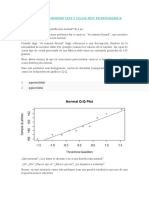
También podría gustarte
- Guía Manual del Amazon Echo : Los 30 Principales Jaqueos y Secretos Para Principiantes del Master Amazon & AlexaDe EverandGuía Manual del Amazon Echo : Los 30 Principales Jaqueos y Secretos Para Principiantes del Master Amazon & AlexaAún no hay calificaciones
- Practicas y Ejercicios Con WEKADocumento17 páginasPracticas y Ejercicios Con WEKALalo TorresAún no hay calificaciones
- Para MetrosDocumento9 páginasPara MetrosGABRIEL GRIMALDO QUISPE HUALLPAAún no hay calificaciones
- TRABAJOS LIBERADOS Caso de UsoDocumento25 páginasTRABAJOS LIBERADOS Caso de UsoJonathan Vaz EstAún no hay calificaciones
- Sistemas Basados en Reglas: Introducción y ArquitecturaDocumento31 páginasSistemas Basados en Reglas: Introducción y ArquitecturaLeybit Abel Hernandez BautistaAún no hay calificaciones
- Fundamentos del Hardware (GRADO SUP.): HARDWARE (O SOPORTE FÍSICO DEL ORDENADOR)De EverandFundamentos del Hardware (GRADO SUP.): HARDWARE (O SOPORTE FÍSICO DEL ORDENADOR)Aún no hay calificaciones
- Aplicaciones Con JGAPDocumento14 páginasAplicaciones Con JGAPRose GuamanAún no hay calificaciones
- Mordiscos Bayesianos: Descifrando los Enigmas de la Vida con un Juego de ProbabilidadDe EverandMordiscos Bayesianos: Descifrando los Enigmas de la Vida con un Juego de ProbabilidadAún no hay calificaciones
- Clase-11 1Documento31 páginasClase-11 1asdabnmmmAún no hay calificaciones
- Práctica de Minería de Datos Intro Al Weka - J. Hernandez, C. Ferri - 1edDocumento18 páginasPráctica de Minería de Datos Intro Al Weka - J. Hernandez, C. Ferri - 1edNoemi SancAún no hay calificaciones
- "El plan de negocios perfecto: que se gana el corazón de los inversionistas!"De Everand"El plan de negocios perfecto: que se gana el corazón de los inversionistas!"Calificación: 4.5 de 5 estrellas4.5/5 (3)
- Insertion Sort: Análisis del algoritmo de ordenamiento por inserciónDocumento11 páginasInsertion Sort: Análisis del algoritmo de ordenamiento por inserciónDario CondoriAún no hay calificaciones
- Sistemas Expertos Basado en ReglasDocumento55 páginasSistemas Expertos Basado en ReglasEdson Huerta GamarraAún no hay calificaciones
- Normalidad en El Programa RDocumento3 páginasNormalidad en El Programa RRAUL YAJAHUANCA HUANCASAún no hay calificaciones
- Redes neuronales para la toma de decisionesDocumento49 páginasRedes neuronales para la toma de decisionesjose luis perales cornejoAún no hay calificaciones
- Manual Python PDFDocumento10 páginasManual Python PDFFranklin Quispe Arpi100% (1)
- TEMA2Documento58 páginasTEMA2kamilzar1993Aún no hay calificaciones
- Practica 11Documento19 páginasPractica 11RenzoRiveroAún no hay calificaciones
- Instalacion de Odi 12cDocumento44 páginasInstalacion de Odi 12cPamela LopezAún no hay calificaciones
- SESION 5Documento10 páginasSESION 5jhotsycordovanavarroAún no hay calificaciones
- Co Pid Grupo10Documento15 páginasCo Pid Grupo10nooamooroosAún no hay calificaciones
- Reglas de AsociaciónDocumento24 páginasReglas de AsociaciónRA OseasAún no hay calificaciones
- Análisis climático en Australia con Minería de DatosDocumento8 páginasAnálisis climático en Australia con Minería de Datosjulio fraileAún no hay calificaciones
- Modelo de Toma de DesicionesDocumento16 páginasModelo de Toma de DesicionesFranz R MontesAún no hay calificaciones
- Manual ClementineDocumento9 páginasManual ClementineJunior Freddy Janampa HuamanAún no hay calificaciones
- Clase 6 - Librerías y Resolución de Problemas HONDURASDocumento11 páginasClase 6 - Librerías y Resolución de Problemas HONDURAScrisAún no hay calificaciones
- a00919271 Calculo Los Intervalos de Confianza de Los Rendimientos de AccionesDocumento4 páginasa00919271 Calculo Los Intervalos de Confianza de Los Rendimientos de AccionesPaola Treviño de BortoniAún no hay calificaciones
- Cap 07Documento18 páginasCap 07Brayan David Ballesteros HerreraAún no hay calificaciones
- Perdido Con PascalDocumento35 páginasPerdido Con Pascaldigital_ecAún no hay calificaciones
- ProgramacionDocumento35 páginasProgramacionFernando ValdezAún no hay calificaciones
- ATD - Sesion 15-16 Supervised Models - NEW FormatDocumento51 páginasATD - Sesion 15-16 Supervised Models - NEW FormatTommy ViteAún no hay calificaciones
- 5 Branch and BoundDocumento27 páginas5 Branch and BoundReidy DarwinAún no hay calificaciones
- AlgoritmosDocumento15 páginasAlgoritmosIsaura Maria Suarez NovoaAún no hay calificaciones
- Lenguaje de ComandosDocumento46 páginasLenguaje de ComandosRafaelAún no hay calificaciones
- Clase 6Documento8 páginasClase 6Bahamondes OscarAún no hay calificaciones
- Desviacion Tipica en EstadisticaDocumento5 páginasDesviacion Tipica en EstadisticaMireya GomezAún no hay calificaciones
- Administración Del Riesgo OperacionalDocumento6 páginasAdministración Del Riesgo OperacionalMarcela AgudeloAún no hay calificaciones
- 1.6 Àrboles de DecisionesDocumento3 páginas1.6 Àrboles de DecisionesGerardo SaiiCkhee Juárez MartínezAún no hay calificaciones
- Clase6 DGDocumento24 páginasClase6 DGmagonzalezAún no hay calificaciones
- Presentacion Teoria de DecisionDocumento33 páginasPresentacion Teoria de DecisionMarlene Santiago AcostaAún no hay calificaciones
- Crear Una Instalacion Desatendida de Windows XPDocumento26 páginasCrear Una Instalacion Desatendida de Windows XPsergiAún no hay calificaciones
- Final Respuestas de Tarea 1Documento16 páginasFinal Respuestas de Tarea 1Gabriel RamosAún no hay calificaciones
- Pseudocodigo-2 0Documento14 páginasPseudocodigo-2 0hc9580Aún no hay calificaciones
- Java Poo - ApuntesDocumento13 páginasJava Poo - ApuntesDavid VerdesotoAún no hay calificaciones
- Ejercicio Intervalos de Confianza - Jose VerdugoDocumento6 páginasEjercicio Intervalos de Confianza - Jose VerdugoJose Carlos VerdugoAún no hay calificaciones
- Si ResumenDocumento5 páginasSi ResumenManu AmestoyAún no hay calificaciones
- Promedio de notas de estudiantes con PseintDocumento10 páginasPromedio de notas de estudiantes con PseintFisio VitalAún no hay calificaciones
- Árbol de DecisiónDocumento18 páginasÁrbol de DecisiónglendyscarolinaAún no hay calificaciones
- Algoritmo TerminadoDocumento20 páginasAlgoritmo Terminadoandrey ramirezAún no hay calificaciones
- Técnica del árbol decisiónDocumento7 páginasTécnica del árbol decisiónSaraiLópezAún no hay calificaciones
- Cálculo de Incertidumbre - Caso EjemploDocumento5 páginasCálculo de Incertidumbre - Caso EjemploChristiam PabonAún no hay calificaciones
- Manual Práctico para La Elaboración de Diagramas de Causa y Efecto, Varianza y Gráficas de Control NP PDFDocumento31 páginasManual Práctico para La Elaboración de Diagramas de Causa y Efecto, Varianza y Gráficas de Control NP PDFIng.OmargmtzAún no hay calificaciones
- PROGRAMACIONDocumento22 páginasPROGRAMACIONUnidad Educativa Víctor Manuel GuzmánAún no hay calificaciones
- PRACTICA PROBABILIDADES Carlo CordovaDocumento8 páginasPRACTICA PROBABILIDADES Carlo CordovaCarlo Renato Cordova100% (3)
- Tarea FundamentosDocumento18 páginasTarea FundamentosArony BanegasAún no hay calificaciones
- Manual FbackupDocumento18 páginasManual FbackupBrayan Davian Flórez GarcíaAún no hay calificaciones
- Diapositiva de Recursos Humanos 1Documento1 páginaDiapositiva de Recursos Humanos 1Yerson Cristobal VicenteAún no hay calificaciones
- Delitos InformáticosDocumento8 páginasDelitos InformáticosYERSON CRISTOBAL VICENTEAún no hay calificaciones
- 5G en PerúDocumento2 páginas5G en PerúYERSON CRISTOBAL VICENTEAún no hay calificaciones
- Taller de EmprendimientoDocumento2 páginasTaller de EmprendimientoYerson Cristobal VicenteAún no hay calificaciones
- Modeler ApplicationsDocumento352 páginasModeler ApplicationsYerson Cristobal VicenteAún no hay calificaciones
- Educación SecundariaDocumento4 páginasEducación SecundariaYerson Cristobal VicenteAún no hay calificaciones
- Dichos Plantean Varios Inconvenientes JurídicosDocumento2 páginasDichos Plantean Varios Inconvenientes JurídicosYerson Cristobal VicenteAún no hay calificaciones
- Delitos InformáticosDocumento8 páginasDelitos InformáticosYERSON CRISTOBAL VICENTEAún no hay calificaciones
- MetodologíasDocumento40 páginasMetodologíasYerson Cristobal VicenteAún no hay calificaciones
- IndicadoresDocumento3 páginasIndicadoresYerson Cristobal VicenteAún no hay calificaciones
- Aplicación Estrategia BPM (Telemonitoreo-Essalud)Documento57 páginasAplicación Estrategia BPM (Telemonitoreo-Essalud)Yerson Cristobal VicenteAún no hay calificaciones
- Nombrar 4 Títulos de Tesis sobre BPM y ITILDocumento6 páginasNombrar 4 Títulos de Tesis sobre BPM y ITILYerson Cristobal VicenteAún no hay calificaciones
- OCP Objetivos de Corto Plazo Nombre Del Indicador Descripción Del Indicador Unidad Medida Perspectiva FinancieraDocumento2 páginasOCP Objetivos de Corto Plazo Nombre Del Indicador Descripción Del Indicador Unidad Medida Perspectiva FinancieraYerson Cristobal VicenteAún no hay calificaciones
- TRINIDocumento2 páginasTRINIYerson Cristobal VicenteAún no hay calificaciones
- Benchmarking en la Universidad Nacional Daniel Alcides CarriónDocumento36 páginasBenchmarking en la Universidad Nacional Daniel Alcides CarriónYerson Cristobal VicenteAún no hay calificaciones
- FORMATO No.1Documento5 páginasFORMATO No.1Yerson Cristobal VicenteAún no hay calificaciones
- Cuestionario de Ataques DdosDocumento2 páginasCuestionario de Ataques DdosYerson Cristobal VicenteAún no hay calificaciones
- Ensayo PPPDocumento13 páginasEnsayo PPPYerson Cristobal VicenteAún no hay calificaciones
- Autoevaluacion Retrospectiva Personal (CRISTOBAL VICENTE, Yerson Leoncio)Documento3 páginasAutoevaluacion Retrospectiva Personal (CRISTOBAL VICENTE, Yerson Leoncio)Yerson Cristobal VicenteAún no hay calificaciones
- Proceso citas telemedicina optimizadoDocumento7 páginasProceso citas telemedicina optimizadoYerson Cristobal VicenteAún no hay calificaciones
- Ensayo sobre liderazgo y tipos de líderDocumento10 páginasEnsayo sobre liderazgo y tipos de líderYerson Cristobal VicenteAún no hay calificaciones
- Examen Parcial Ati - Iv UnidadDocumento1 páginaExamen Parcial Ati - Iv UnidadYerson Cristobal VicenteAún no hay calificaciones
- Blanco y Azul Simple Autobiografía Portada de LibroDocumento1 páginaBlanco y Azul Simple Autobiografía Portada de LibroYerson Cristobal VicenteAún no hay calificaciones
- Matriz de Consistencia Municipalidad Distrital de AtuncollaDocumento1 páginaMatriz de Consistencia Municipalidad Distrital de AtuncollaALFRED HCAún no hay calificaciones
- Tarea Domiciliaria 1feb21Documento1 páginaTarea Domiciliaria 1feb21Yerson Cristobal VicenteAún no hay calificaciones
- Ficha de Aplicacion AudiovisualDocumento2 páginasFicha de Aplicacion AudiovisualYerson Cristobal VicenteAún no hay calificaciones
- Blanco y Azul Simple Autobiografía Portada de LibroDocumento1 páginaBlanco y Azul Simple Autobiografía Portada de LibroYerson Cristobal VicenteAún no hay calificaciones
- CURSO LaboratorioDocumento2 páginasCURSO LaboratorioYerson Cristobal VicenteAún no hay calificaciones
- 18 La Ciudad Inteligente Smart City IntrodcucciónDocumento25 páginas18 La Ciudad Inteligente Smart City IntrodcucciónYerson Cristobal VicenteAún no hay calificaciones
- Estándar IEEE STD 1063Documento9 páginasEstándar IEEE STD 1063imeflzv100% (3)
- PSP ENTREGA No 2 Semana 3Documento14 páginasPSP ENTREGA No 2 Semana 3jonathanAún no hay calificaciones
- Cómo funcionan las promesas en JavaScriptDocumento14 páginasCómo funcionan las promesas en JavaScriptWilmaAún no hay calificaciones
- Informe AlgoritmosDocumento6 páginasInforme AlgoritmosKevin TulcánAún no hay calificaciones
- Estilos Arquitectónicos de SoftwareDocumento40 páginasEstilos Arquitectónicos de SoftwaremiguelAún no hay calificaciones
- Programacion SecuencialDocumento14 páginasProgramacion Secuencialsilvia fiorellaAún no hay calificaciones
- Algoritmos y PSeInt para resolver problemasDocumento6 páginasAlgoritmos y PSeInt para resolver problemasMayli FaustinoAún no hay calificaciones
- JordhyRojas (22210349) - Lista ViajesDocumento5 páginasJordhyRojas (22210349) - Lista ViajesJORDHY JAIR ROJAS OSUNAAún no hay calificaciones
- Ofimatica 1Documento9 páginasOfimatica 1Duvan PetrooAún no hay calificaciones
- Lenguaje Unificado UmlDocumento108 páginasLenguaje Unificado UmlKAB1510Aún no hay calificaciones
- Dsop U2 A1 JebrDocumento16 páginasDsop U2 A1 JebrBeard ManAún no hay calificaciones
- Trimble Access - AccessSyncDocumento26 páginasTrimble Access - AccessSyncPatricio VegaAún no hay calificaciones
- Requisitos software formación SENADocumento52 páginasRequisitos software formación SENAAlejandro Romero TovarAún no hay calificaciones
- 2.2 Casos de PruebaDocumento7 páginas2.2 Casos de PruebaCelina SanchezAún no hay calificaciones
- Diagrama de FlujoDocumento5 páginasDiagrama de FlujoSalvador Diaz RomeroAún no hay calificaciones
- TICB2 - Estrategias Determinacion RequerimientosDocumento34 páginasTICB2 - Estrategias Determinacion RequerimientosAlfredo Márquez100% (2)
- Servicios de Transformación de DatosDocumento16 páginasServicios de Transformación de DatosMartha GuerraAún no hay calificaciones
- 19714-Modulo - Exportacion A3ecoDocumento48 páginas19714-Modulo - Exportacion A3ecoMoraManAún no hay calificaciones
- Manual de Mantenimiento Control de AccesoDocumento4 páginasManual de Mantenimiento Control de AccesoRicarditisAún no hay calificaciones
- L4 - Programacion de Dispositivos Iot 2023 - 2v2-1Documento10 páginasL4 - Programacion de Dispositivos Iot 2023 - 2v2-1retosanchezevelynmelisaAún no hay calificaciones
- Presentacion: (CITATION Joa14 /L 10250)Documento9 páginasPresentacion: (CITATION Joa14 /L 10250)Ismael OswaldoAún no hay calificaciones
- Capitulo 1 MS Project IntroduccionDocumento15 páginasCapitulo 1 MS Project IntroduccionNairobi HernandezAún no hay calificaciones
- SQL para No InformáticosDocumento6 páginasSQL para No InformáticosMarcia MéndezAún no hay calificaciones
- Mapa MentalDocumento1 páginaMapa MentalFERNANDEZ ORDOÑEZ KAREN VIANEAún no hay calificaciones
- Estandares de Diseño Web - 223Documento3 páginasEstandares de Diseño Web - 223Dariel MartesAún no hay calificaciones
- Code Review Como Un Paso Más para Asegurar La Calidad Del SoftwareDocumento13 páginasCode Review Como Un Paso Más para Asegurar La Calidad Del SoftwareAnonymous hiCnEIAún no hay calificaciones
- PL/SQLDocumento27 páginasPL/SQLBily VasquezAún no hay calificaciones
- Practica1 JAVA RMI Modelo InformeDocumento2 páginasPractica1 JAVA RMI Modelo InformeJosé LanzaAún no hay calificaciones
- Lista EntregablesDocumento11 páginasLista EntregablesKamilo RodriguezAún no hay calificaciones
- Practica 5 Select 1Documento3 páginasPractica 5 Select 1FranciscodlxAún no hay calificaciones
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (117)
- LAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.De EverandLAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.Calificación: 4.5 de 5 estrellas4.5/5 (54)
- Excel 2021 y 365 Paso a Paso: Paso a PasoDe EverandExcel 2021 y 365 Paso a Paso: Paso a PasoCalificación: 5 de 5 estrellas5/5 (12)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- Machine Learning y Deep Learning: Usando Python, Scikit y KerasDe EverandMachine Learning y Deep Learning: Usando Python, Scikit y KerasAún no hay calificaciones
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- ¿Cómo piensan las máquinas?: Inteligencia artificial para humanosDe Everand¿Cómo piensan las máquinas?: Inteligencia artificial para humanosCalificación: 5 de 5 estrellas5/5 (1)
- Lógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosDe EverandLógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosCalificación: 3.5 de 5 estrellas3.5/5 (7)
- Guía de cálculo y diseño de conductos para ventilación y climatizaciónDe EverandGuía de cálculo y diseño de conductos para ventilación y climatizaciónCalificación: 5 de 5 estrellas5/5 (1)
- Manual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasDe EverandManual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasCalificación: 4.5 de 5 estrellas4.5/5 (14)
- El mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosDe EverandEl mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosCalificación: 5 de 5 estrellas5/5 (2)
- Design Thinking para principiantes: La innovación como factor para el éxito empresarialDe EverandDesign Thinking para principiantes: La innovación como factor para el éxito empresarialCalificación: 4.5 de 5 estrellas4.5/5 (10)
- Metodología básica de instrumentación industrial y electrónicaDe EverandMetodología básica de instrumentación industrial y electrónicaCalificación: 4 de 5 estrellas4/5 (12)
- UF0349: ATENCIÓN AL CLIENTE EN EL PROCESO COMERCIAL (ADGG0208) (ADGD0308)De EverandUF0349: ATENCIÓN AL CLIENTE EN EL PROCESO COMERCIAL (ADGG0208) (ADGD0308)Calificación: 2 de 5 estrellas2/5 (1)
- EL PLAN DE NEGOCIOS DE UNA FORMA SENCILLA. La guía práctica que ayuda a poner en marcha nuevos proyectos e ideas empresariales.De EverandEL PLAN DE NEGOCIOS DE UNA FORMA SENCILLA. La guía práctica que ayuda a poner en marcha nuevos proyectos e ideas empresariales.Calificación: 4 de 5 estrellas4/5 (20)
- Investigación de mercados: Un enfoque gerencialDe EverandInvestigación de mercados: Un enfoque gerencialCalificación: 3.5 de 5 estrellas3.5/5 (9)
- Arduino. Guía práctica de fundamentos y simulación: RobóticaDe EverandArduino. Guía práctica de fundamentos y simulación: RobóticaCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Ciberseguridad: Una Simple Guía para Principiantes sobre Ciberseguridad, Redes Informáticas y Cómo Protegerse del Hacking en Forma de Phishing, Malware, Ransomware e Ingeniería SocialDe EverandCiberseguridad: Una Simple Guía para Principiantes sobre Ciberseguridad, Redes Informáticas y Cómo Protegerse del Hacking en Forma de Phishing, Malware, Ransomware e Ingeniería SocialCalificación: 4.5 de 5 estrellas4.5/5 (11)
- El dilema humano: Del Homo sapiens al Homo techDe EverandEl dilema humano: Del Homo sapiens al Homo techCalificación: 4 de 5 estrellas4/5 (1)
- Marketing digital que funciona: Planifica tu estrategia e invierte con cabezaDe EverandMarketing digital que funciona: Planifica tu estrategia e invierte con cabezaCalificación: 4.5 de 5 estrellas4.5/5 (7)
- Cómo ser un Ninja Social: Supera el miedo a hablar con desconocidos, crea conexiones con cualquiera y se la persona más interesante del lugarDe EverandCómo ser un Ninja Social: Supera el miedo a hablar con desconocidos, crea conexiones con cualquiera y se la persona más interesante del lugarCalificación: 4.5 de 5 estrellas4.5/5 (4)