También podría gustarte
- Familia y Terapia Familiar MinuchinDocumento177 páginasFamilia y Terapia Familiar Minuchinveronica_aranda100% (42)
- Análisis de Antecedentes y Justificación Del ProductoDocumento21 páginasAnálisis de Antecedentes y Justificación Del ProductoRobert CooperAún no hay calificaciones
- Ciencias Físico MatemáticasDocumento4 páginasCiencias Físico MatemáticasDiana VfAún no hay calificaciones
- La Furia y La TristezaDocumento3 páginasLa Furia y La TristezaDiana VfAún no hay calificaciones
- PROGRAMA Practica Clinica UdGDocumento3 páginasPROGRAMA Practica Clinica UdGDiana VfAún no hay calificaciones
- Hacia El Diálogo en El Salón - Comunidad de IndagacionDocumento19 páginasHacia El Diálogo en El Salón - Comunidad de IndagacionNereyda RamírezAún no hay calificaciones
- Salud y Bienestar EstudiantilDocumento2 páginasSalud y Bienestar EstudiantilDiana VfAún no hay calificaciones
- Tipos de RedDocumento7 páginasTipos de RedDiana VfAún no hay calificaciones
- SistemicoDocumento1 páginaSistemicoDiana VfAún no hay calificaciones
- Conciliacion BancariaDocumento4 páginasConciliacion BancariaDiana VfAún no hay calificaciones
- Tipos de EncuestaDocumento2 páginasTipos de Encuestakevin herrera anayaAún no hay calificaciones
- Casos de Aplicación Semana 4Documento2 páginasCasos de Aplicación Semana 4Carlos Enrique Monsefu AlvarezAún no hay calificaciones
- Guia de Investigación Aplicada SchwarzDocumento48 páginasGuia de Investigación Aplicada SchwarzMax Schwarz100% (2)
- Kubr, Milan, "La Consultoría de Empresas: Guía para La Profesión", Limusa S.A de C.V., 3 Edición, México, 2005Documento2 páginasKubr, Milan, "La Consultoría de Empresas: Guía para La Profesión", Limusa S.A de C.V., 3 Edición, México, 2005Miller Cruz MejiaAún no hay calificaciones
- Escala de Motivación Situacional Académica para EstudiantesDocumento16 páginasEscala de Motivación Situacional Académica para EstudiantesPrincipito NegroAún no hay calificaciones
- S03.s1 U1 - ENFOQUE ISHIKAWA, ENFOQUE TAGUCHI Y ENFOQUE FEINGABURNDocumento24 páginasS03.s1 U1 - ENFOQUE ISHIKAWA, ENFOQUE TAGUCHI Y ENFOQUE FEINGABURNMarcos Geller SilvaAún no hay calificaciones
- Matriz de ConsistenciaDocumento4 páginasMatriz de ConsistenciaAnthony Brayan CuroAún no hay calificaciones
- AUDITORÍA FORENSE Libro Fabian Delgado Loor 1-10-2017Documento86 páginasAUDITORÍA FORENSE Libro Fabian Delgado Loor 1-10-2017Caye Cuesta100% (1)
- Trabajo de Investigación-AnemiaDocumento50 páginasTrabajo de Investigación-AnemiaClaudia XimenaAún no hay calificaciones
- Silabo - 09502Documento7 páginasSilabo - 09502Eliud TOMAS SOTOAún no hay calificaciones
- Lectura 1. Tipos de EstudiosDocumento11 páginasLectura 1. Tipos de EstudiosRicardo FaustinoAún no hay calificaciones
- José Caraballo 7839900 (Anteproyecto)Documento10 páginasJosé Caraballo 7839900 (Anteproyecto)robelis henriquezAún no hay calificaciones
- Manual PMF y Cuestionario CAPI (1) - 1-10Documento10 páginasManual PMF y Cuestionario CAPI (1) - 1-10Catalina Volpi BurgosAún no hay calificaciones
- Desarrollo de La Psicologia Clinica Como ProfesionDocumento9 páginasDesarrollo de La Psicologia Clinica Como ProfesionCamilo TorresAún no hay calificaciones
- Intervencion Del Trabajador Social Sector SaludDocumento126 páginasIntervencion Del Trabajador Social Sector SaludJuan Coasaca PortalAún no hay calificaciones
- Elegir y Delimitar Un Tema, Planteamiento y FormulacionDocumento12 páginasElegir y Delimitar Un Tema, Planteamiento y FormulacionEli MorenoAún no hay calificaciones
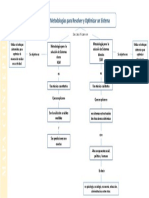
- Mapa Conceptual Metodologías para Resolver y Optimizar Un SistemaDocumento1 páginaMapa Conceptual Metodologías para Resolver y Optimizar Un SistemaBeatriz0% (1)
- Serie de Ejercicio Prueba de Hipotesis - Ares Jair Pichardo GarcíaDocumento4 páginasSerie de Ejercicio Prueba de Hipotesis - Ares Jair Pichardo GarcíaAnonymous 4wo3B2RCCAún no hay calificaciones
- Tesis de Habilidades SocialesDocumento164 páginasTesis de Habilidades Socialescaitlyn100% (2)
- Informe Final Murales EcovistaDocumento45 páginasInforme Final Murales EcovistaJonathan MurilloAún no hay calificaciones
- Solucion Del Primer Parcial D Io 2015-I Umng Grupo ADocumento3 páginasSolucion Del Primer Parcial D Io 2015-I Umng Grupo AJonathanAún no hay calificaciones
- Tema 2 - Sociología Como CienciaDocumento4 páginasTema 2 - Sociología Como CienciaPiero Franchesco Arroyo TorresAún no hay calificaciones
- Métodos Clásicos de EstimaciónDocumento9 páginasMétodos Clásicos de EstimaciónSantos Josue Romero OchoaAún no hay calificaciones
- Tesis AvanceDocumento9 páginasTesis AvancedianaAún no hay calificaciones
- Medidas Descriptivas Datos AgrupadosDocumento3 páginasMedidas Descriptivas Datos AgrupadosJoseph GuerreroAún no hay calificaciones
- CAP 10 Estadistica InferencialDocumento5 páginasCAP 10 Estadistica InferencialbadhuniAún no hay calificaciones
- Tarea 4 - EstadisticaDocumento6 páginasTarea 4 - Estadisticalamp araAún no hay calificaciones
- Dick Carey y Carey 2001Documento18 páginasDick Carey y Carey 2001yumeyacevedo@yahoo.com100% (1)
- Formulario 2Documento3 páginasFormulario 2Karina AvelarAún no hay calificaciones