También podría gustarte
- Base de datos UNIVERSIDAD para hacer seguimiento de estudiantesDocumento3 páginasBase de datos UNIVERSIDAD para hacer seguimiento de estudiantesJUAN DAVID OVALLE CASTELLANOS100% (1)
- Taller MipsDocumento8 páginasTaller MipsOrlando AlcalaAún no hay calificaciones
- ELO311 Tarea 02Documento14 páginasELO311 Tarea 02Susana RebellónAún no hay calificaciones
- Metodo FeldmannDocumento31 páginasMetodo FeldmannDaniela Brevis83% (6)
- Ejercicios de Lenguaje C (Cap2)Documento23 páginasEjercicios de Lenguaje C (Cap2)Carlos Rivadeneira100% (2)
- Informe Lab04Documento8 páginasInforme Lab04Juan MetaleroAún no hay calificaciones
- Informe Caso 2 FINALDocumento48 páginasInforme Caso 2 FINALBrandon Muñoz Leiva100% (1)
- Practica 2 Simulacion de Restador de 4 BitsDocumento12 páginasPractica 2 Simulacion de Restador de 4 BitskorinaAún no hay calificaciones
- Taller 1 - MIPSDocumento2 páginasTaller 1 - MIPSNatalia Geraldin Alvarado SierraAún no hay calificaciones
- Programacion Lenguaje Assembly MIPSDocumento29 páginasProgramacion Lenguaje Assembly MIPSAbraham MontoyaAún no hay calificaciones
- Taller MIPSDocumento4 páginasTaller MIPSNatalia Geraldin Alvarado SierraAún no hay calificaciones
- MIPS Registros InstruccionesDocumento3 páginasMIPS Registros Instruccionesnahuel castilloAún no hay calificaciones
- Taller 1 - MIPSDocumento2 páginasTaller 1 - MIPSAndres Felipe Herrera RodriguezAún no hay calificaciones
- Practica 2.2Documento5 páginasPractica 2.2Mauricio Alejandro Pozo UribeAún no hay calificaciones
- Cert 01 SolDocumento4 páginasCert 01 SolSusana RebellónAún no hay calificaciones
- Programación en Ensamblador Ejercicios Resueltos: Ejercicio 1. Dado El Siguiente Fragmento de Programa en EnsambladorDocumento42 páginasProgramación en Ensamblador Ejercicios Resueltos: Ejercicio 1. Dado El Siguiente Fragmento de Programa en EnsambladorMarcelo YévenesAún no hay calificaciones
- Ejercicios Res Tema 3Documento23 páginasEjercicios Res Tema 3Arinzon Valbuena CasaliniAún no hay calificaciones
- Quizz 01 SolDocumento2 páginasQuizz 01 SolSusana RebellónAún no hay calificaciones
- Tema 04Documento61 páginasTema 04Alex ValentinAún no hay calificaciones
- PA02 ArqComp Rogelio Barcena CheccaDocumento14 páginasPA02 ArqComp Rogelio Barcena CheccaSTEFANY VANESSA VELASCO BRAVOAún no hay calificaciones
- Proyecto MipsDocumento14 páginasProyecto Mipspacho5Aún no hay calificaciones
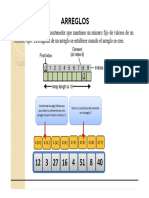
- Arreglos (Modo de Compatibilidad)Documento50 páginasArreglos (Modo de Compatibilidad)Edgardo JoséAún no hay calificaciones
- Programas en EnsambladorDocumento14 páginasProgramas en EnsambladorMatsudaAún no hay calificaciones
- Tema04 Ampliacion OptimizacionDocumento10 páginasTema04 Ampliacion OptimizacionAlex ValentinAún no hay calificaciones
- Manual Resuelto de MIPSDocumento4 páginasManual Resuelto de MIPSVictor Humberto McAún no hay calificaciones
- Tema ArreglosDocumento29 páginasTema ArreglosESplay YTAún no hay calificaciones
- Guía de CompiladoresDocumento4 páginasGuía de CompiladoresTimmiton OrtegaAún no hay calificaciones
- Teoria de MipsDocumento3 páginasTeoria de Mipskatty GómezAún no hay calificaciones
- Banco de Pregunta para Java - OdtDocumento13 páginasBanco de Pregunta para Java - OdtAbraham Franklin SmithAún no hay calificaciones
- Reforzamiento PooDocumento6 páginasReforzamiento PooPIERO ALDO SIMBRON SANCHEZAún no hay calificaciones
- Ejercicios Resueltos C++ (Programacion EstructuradaDocumento23 páginasEjercicios Resueltos C++ (Programacion EstructuradaEsteban Laime GonzalesAún no hay calificaciones
- Sol Lab Dirg 7Documento6 páginasSol Lab Dirg 7uAún no hay calificaciones
- ArquitecturaDocumento3 páginasArquitecturaNILSON ALDAIR RODRIGUEZ QUISPEAún no hay calificaciones
- Tema05 GICDocumento61 páginasTema05 GICjapeninAún no hay calificaciones
- Capitulo 2 Evelio GranizoDocumento8 páginasCapitulo 2 Evelio GranizoKarina LisbethAún no hay calificaciones
- Amplificadores operacionales clase 12Documento22 páginasAmplificadores operacionales clase 12isaac vargasAún no hay calificaciones
- Actividad 4 y 5Documento20 páginasActividad 4 y 5Rodrigo CasanaAún no hay calificaciones
- ENSAMBLADORDocumento6 páginasENSAMBLADORJose Javier Atilano VargasAún no hay calificaciones
- Unit 2 Part 3Documento14 páginasUnit 2 Part 3Keviin SanchezAún no hay calificaciones
- Guía 2.Documento3 páginasGuía 2.iverAún no hay calificaciones
- Conjuntos Numéricos y Operaciones BásicasDocumento8 páginasConjuntos Numéricos y Operaciones BásicasMilton Paredes AvalosAún no hay calificaciones
- Números Enteros y Coordenadas en El PlanoDocumento4 páginasNúmeros Enteros y Coordenadas en El PlanoAMPUERO100% (1)
- Guia 1 Matematica 7 Nellffy M.Documento4 páginasGuia 1 Matematica 7 Nellffy M.NoriDa RoseroAún no hay calificaciones
- EsdatDocumento13 páginasEsdatJeanDeLaCruzAún no hay calificaciones
- Clase 17 Listas Strings TablasDocumento12 páginasClase 17 Listas Strings Tablasbayron.huenchualAún no hay calificaciones
- FC pp0Documento4 páginasFC pp0Hector Nuñez FernandezAún no hay calificaciones
- Parcial III-Arq-Comp-jonathan Vega-2021114040Documento2 páginasParcial III-Arq-Comp-jonathan Vega-2021114040Elieb MolaAún no hay calificaciones
- Dos Problema de Programacion Lineal-ProlinDocumento29 páginasDos Problema de Programacion Lineal-ProlinLuis Bruno100% (3)
- Título conciso y optimizado para del documento sobre operaciones algebraicas con números enterosDocumento3 páginasTítulo conciso y optimizado para del documento sobre operaciones algebraicas con números enterosAlberto DextreAún no hay calificaciones
- Conjuntos y números realesDocumento4 páginasConjuntos y números realesKenia Mili YoonAún no hay calificaciones
- Cap 6Documento24 páginasCap 6Santiago RodriguezAún no hay calificaciones
- Ejercicios de Programación - Examenes - Aux 0.7 PDFDocumento124 páginasEjercicios de Programación - Examenes - Aux 0.7 PDFJesus Tapia AlcocerAún no hay calificaciones
- Ejemplos de Dev C ++Documento6 páginasEjemplos de Dev C ++Jonathan Arley Torres CastañedaAún no hay calificaciones
- 02 - Variables y Tipos de Datos en PythonDocumento20 páginas02 - Variables y Tipos de Datos en PythonDaniel AlmanzaAún no hay calificaciones
- Ejemplos PythonDocumento4 páginasEjemplos PythonJuan David Ocaña0% (1)
- Examen 1Documento6 páginasExamen 1j.a.v.i.m.a.d.r.i.d.9.8Aún no hay calificaciones
- Practica#1 2210 AuxDocumento4 páginasPractica#1 2210 AuxsandroAún no hay calificaciones
- Entrega Final TecDocumento21 páginasEntrega Final Tecapi-544328200Aún no hay calificaciones
- Tarea 5. Matriz InversaDocumento9 páginasTarea 5. Matriz InversaMariana VazquezAún no hay calificaciones
- Practica 2.9-Problemas Varios Con DiagramacionDocumento11 páginasPractica 2.9-Problemas Varios Con DiagramacionVanwar VanAún no hay calificaciones
- Ejercicios PrograDocumento12 páginasEjercicios PrograHenry AAún no hay calificaciones
- Sistemas Digitales. Principios, análisis y diseñoDe EverandSistemas Digitales. Principios, análisis y diseñoAún no hay calificaciones
- Volt I MetroDocumento3 páginasVolt I MetroJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Presentacion Proyecto de AulaDocumento7 páginasPresentacion Proyecto de AulaJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Speaking Exam Basic 4 (Primer Corte)Documento1 páginaSpeaking Exam Basic 4 (Primer Corte)JUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial1 20211Documento1 páginaParcial1 20211JUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- TallerDocumento10 páginasTallerJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Speaking Exam Basic 4 (Primer Corte)Documento1 páginaSpeaking Exam Basic 4 (Primer Corte)JUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- 2001-Agents For Microprocessor Evolution - En.esDocumento7 páginas2001-Agents For Microprocessor Evolution - En.esJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Documentacion Proyecto de AulaDocumento2 páginasDocumentacion Proyecto de AulaJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Documentacion Proyecto de AulaDocumento2 páginasDocumentacion Proyecto de AulaJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial 1 WebDocumento1 páginaParcial 1 WebJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial 1 WebDocumento1 páginaParcial 1 WebJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- DocumentoDocumento1 páginaDocumentoJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- 2001-Agents For Microprocessor Evolution - En.esDocumento7 páginas2001-Agents For Microprocessor Evolution - En.esJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Presentacion Proyecto de AulaDocumento7 páginasPresentacion Proyecto de AulaJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Volt I MetroDocumento3 páginasVolt I MetroJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- PArcial3 PDFDocumento2 páginasPArcial3 PDFJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial1 20211Documento1 páginaParcial1 20211JUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial Desarrollo Web PDFDocumento2 páginasParcial Desarrollo Web PDFJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Parcial S.O 2020-2 1er CorteDocumento2 páginasParcial S.O 2020-2 1er CorteJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Proyecto de Aula - Calculo 3 2do CorteDocumento6 páginasProyecto de Aula - Calculo 3 2do CorteJeferson Fonseca SantosAún no hay calificaciones
- Maestria en Ingenieria de SistemasDocumento1 páginaMaestria en Ingenieria de SistemasPaco MayaAún no hay calificaciones
- ObjetivosDocumento1 páginaObjetivosJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- PArcial3 PDFDocumento2 páginasPArcial3 PDFJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- TacometroDocumento4 páginasTacometroAcarapi AcarapiAún no hay calificaciones
- Taller Cultura AmbientalDocumento6 páginasTaller Cultura AmbientalJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Taller Cultura AmbientalDocumento6 páginasTaller Cultura AmbientalJUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Laboratorio Calculo3Documento7 páginasLaboratorio Calculo3JUAN DAVID OVALLE CASTELLANOSAún no hay calificaciones
- Proyecto de Aula - Calculo 3 2do CorteDocumento6 páginasProyecto de Aula - Calculo 3 2do CorteJeferson Fonseca SantosAún no hay calificaciones
- ProgramaDocumento7 páginasProgramaAlejandro LedezmaAún no hay calificaciones
- Actividad 1 Tec 2Documento3 páginasActividad 1 Tec 2Paula NuñezAún no hay calificaciones
- CAPA 4-Capa de TransporteDocumento17 páginasCAPA 4-Capa de TransporteValéria ValverdeAún no hay calificaciones
- Laboratorio 6 - ReplicacionDocumento9 páginasLaboratorio 6 - ReplicacionHarry HallerAún no hay calificaciones
- Linea de Tiempo Historiade Las MicrocomputadorasDocumento23 páginasLinea de Tiempo Historiade Las MicrocomputadorasAntonio Ochoa SotecAún no hay calificaciones
- Protocolos Capa SuperiorDocumento11 páginasProtocolos Capa SuperiorAndy ComaAún no hay calificaciones
- Diseño de Un Sumador RestadorDocumento7 páginasDiseño de Un Sumador RestadorNERY CRISTINA0% (1)
- Tutorial - Instalar Windows Desde USB Pen Drives - Netbooknews - Netbooks, Comentarios Netbook, Smartbooks y MásDocumento9 páginasTutorial - Instalar Windows Desde USB Pen Drives - Netbooknews - Netbooks, Comentarios Netbook, Smartbooks y Másastro_versache_74696Aún no hay calificaciones
- Panel de ControlDocumento59 páginasPanel de ControlANDRY HERNÁNDEZAún no hay calificaciones
- Primera Practica Packet TraceDocumento20 páginasPrimera Practica Packet Tracesdfasdfasdf123Aún no hay calificaciones
- Taller MPLSDocumento4 páginasTaller MPLSjhoana mejiaAún no hay calificaciones
- Capitulo 9 de Fundamentos Del ComputadorDocumento27 páginasCapitulo 9 de Fundamentos Del ComputadorKenny BaezAún no hay calificaciones
- Windows Explorer: Administrador de archivos de WindowsDocumento2 páginasWindows Explorer: Administrador de archivos de Windowsfelipe_david88Aún no hay calificaciones
- Workshop - Operaciones Con Linux y Windows en EC2Documento17 páginasWorkshop - Operaciones Con Linux y Windows en EC2Jose VasquezAún no hay calificaciones
- Medios almacenamiento archivos digitalesDocumento3 páginasMedios almacenamiento archivos digitalesJuanse HernandezAún no hay calificaciones
- Teoria RaulDocumento8 páginasTeoria RaulMiguel Angel GarciaAún no hay calificaciones
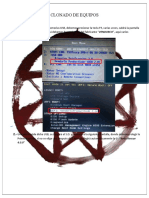
- Clonado de EquiposDocumento6 páginasClonado de EquiposFrancisco León CortezAún no hay calificaciones
- Qué Es Una Red de Punto A PuntoDocumento3 páginasQué Es Una Red de Punto A PuntoDaniel OmarAún no hay calificaciones
- Glab S03 G022 01Documento6 páginasGlab S03 G022 01Javier Marquez UgazAún no hay calificaciones
- Acade Lvs MemoriaDocumento190 páginasAcade Lvs Memoriainfobits100% (4)
- Bios Arranque ErrorDocumento106 páginasBios Arranque Erroralexa borgesAún no hay calificaciones
- Cuaderno de Redes 1Documento5 páginasCuaderno de Redes 1Miguel Angel Medina LievanoAún no hay calificaciones
- wrt54gx Guia PracticaDocumento31 páginaswrt54gx Guia Practicamoon02Aún no hay calificaciones
- Infografía de Línea de Tiempo Timeline Con Años Fechas Multicolor ModernoDocumento1 páginaInfografía de Línea de Tiempo Timeline Con Años Fechas Multicolor ModernoGuisella ArcosAún no hay calificaciones
- WORDDocumento6 páginasWORDCarla Romina HerreraAún no hay calificaciones
- Comandos LinuxDocumento25 páginasComandos LinuxGiancarlo DlhAún no hay calificaciones
- Crear Cliente SOAP Java v2Documento10 páginasCrear Cliente SOAP Java v2m4k_infoAún no hay calificaciones
- Datasheet Librestream Onsight WorkspaceDocumento2 páginasDatasheet Librestream Onsight WorkspacefakesasoAún no hay calificaciones