También podría gustarte
- Torres Torres, Camilo Andrés - 2018Documento25 páginasTorres Torres, Camilo Andrés - 2018FelipAún no hay calificaciones
- Tarea1 - Panorámica Del Enfoque de La Teoría Gerencial de SistemasDocumento18 páginasTarea1 - Panorámica Del Enfoque de La Teoría Gerencial de Sistemasdgalindo1Aún no hay calificaciones
- Raul Alonso Calvo PDFDocumento150 páginasRaul Alonso Calvo PDFjcortipaAún no hay calificaciones
- A3. Reporte de InvestigaciónDocumento23 páginasA3. Reporte de InvestigaciónManuel Mayorga (RadioPrimitivo)Aún no hay calificaciones
- Arquitectura de ComputadorasDocumento269 páginasArquitectura de ComputadorasEder Abraham MendozaAún no hay calificaciones
- Sincronizacion, Tolerancia A Fallos y ReplicaciònDocumento58 páginasSincronizacion, Tolerancia A Fallos y Replicaciònedavilag100% (3)
- Tesis de SistemasDocumento104 páginasTesis de SistemasJose Luis Mayo GaleanaAún no hay calificaciones
- Memoria Corelap 01Documento94 páginasMemoria Corelap 01galaxy elastronautaAún no hay calificaciones
- Programación Básica en Matlab para IngenierosDocumento106 páginasProgramación Básica en Matlab para IngenierosJunior Lino Mera Carrasco100% (3)
- López Díaz Ana TSVMDocumento73 páginasLópez Díaz Ana TSVMLuis Eduardo Moran LópezAún no hay calificaciones
- Guia de MatlabDocumento59 páginasGuia de MatlabOscar VargasAún no hay calificaciones
- Sistemas Operativos PDFDocumento926 páginasSistemas Operativos PDFyennysAún no hay calificaciones
- Semaforo Inteligente Con PerceptronDocumento43 páginasSemaforo Inteligente Con PerceptronDaniel PSAún no hay calificaciones
- Simuladores de Redes de Interconexión: Estudio Comparativo y EvaluaciónDocumento83 páginasSimuladores de Redes de Interconexión: Estudio Comparativo y EvaluacióndanielpostigodiazAún no hay calificaciones
- MSc. Lester Guerra-Diseño de Variantes Del Algoritmo para El Descubrimiento Del Modelo Organizacional en Sistemas MultiprocesadoresDocumento82 páginasMSc. Lester Guerra-Diseño de Variantes Del Algoritmo para El Descubrimiento Del Modelo Organizacional en Sistemas Multiprocesadoresdevperate technoAún no hay calificaciones
- Desarrollo de Simulador Integrado de Microredes InteligentesDocumento174 páginasDesarrollo de Simulador Integrado de Microredes InteligentesJuan Alex Arequipa ChecaAún no hay calificaciones
- Computación de Altas Prestaciones - Módulo 4 - Introducción A La Computación DistribuidaDocumento70 páginasComputación de Altas Prestaciones - Módulo 4 - Introducción A La Computación Distribuidajorge ruizAún no hay calificaciones
- AnteproyectoDocumento12 páginasAnteproyectoemanuel chavarria arroyoAún no hay calificaciones
- Algoritmos paralelos: partición, comunicación y modelosDocumento21 páginasAlgoritmos paralelos: partición, comunicación y modelosShanira Lisset RamirezAún no hay calificaciones
- Matlab aplicado a telecomunicacionesDe EverandMatlab aplicado a telecomunicacionesCalificación: 5 de 5 estrellas5/5 (1)
- Introducción A La NeurocomputaciónDocumento110 páginasIntroducción A La Neurocomputacióninfobits100% (1)
- ACT11Documento11 páginasACT11menAún no hay calificaciones
- Programación y desarrollo de algoritmos con C++De EverandProgramación y desarrollo de algoritmos con C++Aún no hay calificaciones
- TesisDanielHernandezVelasccoDocumento120 páginasTesisDanielHernandezVelasccoJohan TorresAún no hay calificaciones
- Memoria PDFDocumento354 páginasMemoria PDFJorge David Torres LlaucaAún no hay calificaciones
- Ma Go Mart FM 0619 MemoryDocumento150 páginasMa Go Mart FM 0619 MemoryPallavi BhartiAún no hay calificaciones
- AicDocumento162 páginasAicCarlosAndrés Villarreal del AguilaAún no hay calificaciones
- RamusioDocumento96 páginasRamusiocarbanquetAún no hay calificaciones
- Notas Optimizacion Ingenieros PDFDocumento75 páginasNotas Optimizacion Ingenieros PDFjamlatinoAún no hay calificaciones
- Analisis Elemento FinitoDocumento394 páginasAnalisis Elemento FinitoMartin JuarezAún no hay calificaciones
- Tesis SVMDocumento4 páginasTesis SVMrmirandac0% (1)
- Maquina de VectoresDocumento24 páginasMaquina de VectoresAngel Alberto Vargas CanoAún no hay calificaciones
- Principios básicos de estática y programación aplicados a casos realesDe EverandPrincipios básicos de estática y programación aplicados a casos realesCalificación: 5 de 5 estrellas5/5 (1)
- Alejandro Fuentes Diaz TESIS TERMINADADocumento128 páginasAlejandro Fuentes Diaz TESIS TERMINADARICARDO VELÁSQUEZAún no hay calificaciones
- Módulo 6. Clúster, Cloud y DevOpsDocumento68 páginasMódulo 6. Clúster, Cloud y DevOpsmarlonjcc1Aún no hay calificaciones
- Desarrollo de Un Simulador de Molienda ClasificaciónDocumento99 páginasDesarrollo de Un Simulador de Molienda ClasificaciónLucio FernandoAún no hay calificaciones
- Virus Hack - Introducción A La NeuroComputaciónDocumento112 páginasVirus Hack - Introducción A La NeuroComputaciónvvctAún no hay calificaciones
- Design and Implementation of A Data Aggregation System For The 5G Network Management PlaneDocumento69 páginasDesign and Implementation of A Data Aggregation System For The 5G Network Management Planejava webAún no hay calificaciones
- Procesamiento Segmentado y VectorialDocumento55 páginasProcesamiento Segmentado y VectorialJhon Argomedo De La CruzAún no hay calificaciones
- Métodos numéricos aplicados a la ingeniería: Casos de estudio en ingeniería de procesos usando MATLAB®De EverandMétodos numéricos aplicados a la ingeniería: Casos de estudio en ingeniería de procesos usando MATLAB®Aún no hay calificaciones
- Diseño e Implementación de Un Simulador de Sala de Máquinas PDFDocumento125 páginasDiseño e Implementación de Un Simulador de Sala de Máquinas PDFAndres TutivenAún no hay calificaciones
- Energy and Performance-Aware Scheduling and Shut-Down Models For Efficient Cloud-Computing Data 2Documento166 páginasEnergy and Performance-Aware Scheduling and Shut-Down Models For Efficient Cloud-Computing Data 2peeter morales cruzAún no hay calificaciones
- Homework 3 - Tesis Nivel PredictivoDocumento99 páginasHomework 3 - Tesis Nivel PredictivoAlexánderAún no hay calificaciones
- Sistemas OperativosDocumento921 páginasSistemas OperativosyazmauAún no hay calificaciones
- Desarrollo de una aplicación de reconocimiento de imágenes utilizando Deep Learning con OpenCVDocumento104 páginasDesarrollo de una aplicación de reconocimiento de imágenes utilizando Deep Learning con OpenCVAlicia LaraAún no hay calificaciones
- TFG Lorza Pascual MikelDocumento106 páginasTFG Lorza Pascual MikelEnrique GarcíaAún no hay calificaciones
- Tutorial ns-3 simulación algoritmos ruteo redesDocumento65 páginasTutorial ns-3 simulación algoritmos ruteo redesLuisAún no hay calificaciones
- Reportes gerenciales con NodeJSDocumento135 páginasReportes gerenciales con NodeJSMilagros MelendezAún no hay calificaciones
- Fundamentos de Algoritmos Monografia BorradorDocumento113 páginasFundamentos de Algoritmos Monografia BorradorKene Reyna Rojas100% (2)
- Apuntes MATLABDocumento202 páginasApuntes MATLABvickoAún no hay calificaciones
- Programaci On en MatlabDocumento202 páginasProgramaci On en MatlabVICTOR DANILO NARVAEZ MERCADOAún no hay calificaciones
- Predicción y optimización de emisiores y consumo mediante redes neuronales en motores diéselDe EverandPredicción y optimización de emisiores y consumo mediante redes neuronales en motores diéselAún no hay calificaciones
- Servicios en Red (GRADO MEDIO): Internet: obras generalesDe EverandServicios en Red (GRADO MEDIO): Internet: obras generalesAún no hay calificaciones
- Sea Por Siempre Ensalzado El Santo Nombre Del Supremo CreadorDocumento2 páginasSea Por Siempre Ensalzado El Santo Nombre Del Supremo Creadorluis naranjo100% (1)
- CANALETA Circular, Rectangular y TrapezoidalDocumento11 páginasCANALETA Circular, Rectangular y TrapezoidalWendy RamírezAún no hay calificaciones
- Manual Limpieza y Desinfeccion de Planta Fisica y Personal.Documento10 páginasManual Limpieza y Desinfeccion de Planta Fisica y Personal.beatriz cecilia maldonado vAún no hay calificaciones
- Examen VelocDocumento5 páginasExamen VelocCarmen Ramirez CavagnolaAún no hay calificaciones
- Tric I Taxi MetroDocumento24 páginasTric I Taxi MetroDaniel Alexander Moo CihAún no hay calificaciones
- Preguntas de III Parcial de QQ-OO Con Respuestas. v.2Documento7 páginasPreguntas de III Parcial de QQ-OO Con Respuestas. v.2huribibiAún no hay calificaciones
- Cómo hacer slime - Práctica de polímero no newtonianoDocumento3 páginasCómo hacer slime - Práctica de polímero no newtonianoMaria Jara50% (2)
- Sin Título 1Documento40 páginasSin Título 1David BanerAún no hay calificaciones
- Presentacion Pisos de Madera CrisDocumento108 páginasPresentacion Pisos de Madera CrisGean Pierre RiosAún no hay calificaciones
- Analisis de Falla de Una Brida de Acero Al CarnonoDocumento10 páginasAnalisis de Falla de Una Brida de Acero Al CarnonoSAún no hay calificaciones
- Luis Barragán-Matiana González SilvaDocumento38 páginasLuis Barragán-Matiana González SilvaKaren Aguilar100% (3)
- DiseñoOrificioPlacaDocumento5 páginasDiseñoOrificioPlacaGudo TajaloAún no hay calificaciones
- Como Se Desarrolla o Formula La InvestigaciónDocumento4 páginasComo Se Desarrolla o Formula La Investigaciónmayra rodasAún no hay calificaciones
- Practica 3 NectarDocumento6 páginasPractica 3 NectarLuz MariaAún no hay calificaciones
- Cocina Basica CortesDocumento14 páginasCocina Basica CortesCarolina Gomez RestrepoAún no hay calificaciones
- Ley de Ohm: Medición de resistencias y comprobación de la leyDocumento6 páginasLey de Ohm: Medición de resistencias y comprobación de la leyNgl Salvador PalaAún no hay calificaciones
- Viscosidad de Caida de Una EsferaDocumento5 páginasViscosidad de Caida de Una EsferaRaul JesusAún no hay calificaciones
- Yeldy Vidal ControlS4Documento5 páginasYeldy Vidal ControlS4orianaAún no hay calificaciones
- NootrópicosDocumento13 páginasNootrópicosOsukaru Kuro Neko100% (1)
- Ensayo Salud y Seguridad.Documento3 páginasEnsayo Salud y Seguridad.Mr AkkunAún no hay calificaciones
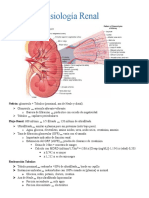
- Fisiología renal: nefrón, flujo renal, ultrafiltrado, reabsorción tubular y regulación hormonalDocumento5 páginasFisiología renal: nefrón, flujo renal, ultrafiltrado, reabsorción tubular y regulación hormonalJean Claudio Miranda ParraAún no hay calificaciones
- Clase Libertad Financiera. 1 Basico.Documento6 páginasClase Libertad Financiera. 1 Basico.marwincardonaAún no hay calificaciones
- Canciones de TunaDocumento147 páginasCanciones de TunaMerche100% (1)
- Porta maceta de acero fabricado con soldaduraDocumento5 páginasPorta maceta de acero fabricado con soldaduraAlberth Fredi M. ZuañaAún no hay calificaciones
- Colocar Tacómetro A Fiat PalioDocumento4 páginasColocar Tacómetro A Fiat PalioJulio NuñezAún no hay calificaciones
- ISEB20 empleos impactoDocumento15 páginasISEB20 empleos impactoAlfredoAún no hay calificaciones
- Producto AcademicoDocumento31 páginasProducto AcademicoAnto PMontoyaAún no hay calificaciones
- SP FICHA-AmarokDocumento4 páginasSP FICHA-AmarokRaul BandaAún no hay calificaciones
- IA ReporteFINALDocumento6 páginasIA ReporteFINALZeero' Sioux PageAún no hay calificaciones
- Aislamiento - Prueba 794ACDocumento9 páginasAislamiento - Prueba 794ACnicolasAún no hay calificaciones