También podría gustarte
- Sistemas VirtualizadosDocumento16 páginasSistemas VirtualizadosM N Klvn AndsAún no hay calificaciones
- 34.TM-1875 AVEVA Everything3D™ (2.1) Schematic 3D Integrator Administration - En.esDocumento76 páginas34.TM-1875 AVEVA Everything3D™ (2.1) Schematic 3D Integrator Administration - En.eskaren Joya100% (1)
- Liop2 - U1 - A1 - LuplDocumento6 páginasLiop2 - U1 - A1 - LuplHomEgaAún no hay calificaciones
- Cloud ComputingDocumento9 páginasCloud ComputingFeni_X13dbzAún no hay calificaciones
- Open StackDocumento3 páginasOpen StackAxell Badillo CuevasAún no hay calificaciones
- En Pocas Palabras - ¿Cómo Funciona OpenStack - Victoria Martínez de La CruzDocumento8 páginasEn Pocas Palabras - ¿Cómo Funciona OpenStack - Victoria Martínez de La CruzManuel Alvarez-Ossorio GarciaAún no hay calificaciones
- Unidad 4 - Plataformas Cloud ComputingDocumento12 páginasUnidad 4 - Plataformas Cloud ComputingSchneyder AnilloAún no hay calificaciones
- Herramientas Comp - NubeDocumento21 páginasHerramientas Comp - NubeALBERTO GABRIEL PAREDES FERNANDEZAún no hay calificaciones
- Openstack InformeDocumento18 páginasOpenstack InformeChanna De La Cruz MendozaAún no hay calificaciones
- Qué Son Los Contenedores de LinuxDocumento9 páginasQué Son Los Contenedores de LinuxHector MataAún no hay calificaciones
- Kubernetes o k8sDocumento7 páginasKubernetes o k8sHector MataAún no hay calificaciones
- Open StackDocumento3 páginasOpen StackByron CayoAún no hay calificaciones
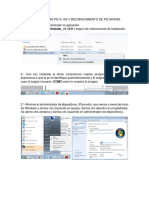
- Instalacion Open StackDocumento6 páginasInstalacion Open StackDiego YandunAún no hay calificaciones
- Compendio OpenStack para LACNICDocumento9 páginasCompendio OpenStack para LACNICJose NapoliAún no hay calificaciones
- DEVOPSDocumento2 páginasDEVOPSalexander3prieto3chaAún no hay calificaciones
- Trabajo de InvestigaciónDocumento5 páginasTrabajo de InvestigaciónABEL LEVI MIRANDA LAURELAún no hay calificaciones
- Evaluación práctica de SFC con OpenStackDocumento123 páginasEvaluación práctica de SFC con OpenStackAnderson ValderramaAún no hay calificaciones
- CuadroSinopticoHerramientaNube MelanyLópezPorrasDocumento1 páginaCuadroSinopticoHerramientaNube MelanyLópezPorrasmelanylopezporras08Aún no hay calificaciones
- Características Hyper V WINDOWS SERVERDocumento10 páginasCaracterísticas Hyper V WINDOWS SERVERMüller VillaAún no hay calificaciones
- Kubernetes y computo en la nubeDocumento16 páginasKubernetes y computo en la nubeAlan J Mast SantAún no hay calificaciones
- Tema 5 Virtualizacion y ConsolidacionDocumento10 páginasTema 5 Virtualizacion y Consolidacionzoesl2002Aún no hay calificaciones
- Tutorial Kubernetes en Español - Parte 1Documento6 páginasTutorial Kubernetes en Español - Parte 1Alberto Quintana HerasAún no hay calificaciones
- Servicios de NubeDocumento6 páginasServicios de Nubeosantias2Aún no hay calificaciones
- Articulo Contenedores Linux PDFDocumento3 páginasArticulo Contenedores Linux PDFCESAR DAVID VASQUEZ ROMEROAún no hay calificaciones
- Open Vswitch PDFDocumento9 páginasOpen Vswitch PDFHerlan VillanuevaAún no hay calificaciones
- VIRTUALIZACIONDocumento16 páginasVIRTUALIZACIONAlejandroAún no hay calificaciones
- OPENSTACKDocumento18 páginasOPENSTACKKaren MujicaAún no hay calificaciones
- Brochure - CourseSpecialistProxmox7.2 - Virtualization - Clusters - HighAvailability (2022-01)Documento13 páginasBrochure - CourseSpecialistProxmox7.2 - Virtualization - Clusters - HighAvailability (2022-01)arnold VicenteAún no hay calificaciones
- Evaluación Infra Oficial de TI PanamáDocumento4 páginasEvaluación Infra Oficial de TI PanamáCésar SandovalAún no hay calificaciones
- Módulo2 Unidad01 Principios 2021 EHDocumento32 páginasMódulo2 Unidad01 Principios 2021 EHGonzalo RodriguezAún no hay calificaciones
- Investigacion Computacion UbicuaDocumento10 páginasInvestigacion Computacion UbicuaPsy Chriz MwAún no hay calificaciones
- Sistemas DistribuidosDocumento12 páginasSistemas DistribuidosJhonatan A LRAún no hay calificaciones
- Informe MulticloudDocumento4 páginasInforme Multicloudjose daniel gonzalesAún no hay calificaciones
- 0. OpenStack Introduccion al IASSDocumento33 páginas0. OpenStack Introduccion al IASSErika Apaza VilcaAún no hay calificaciones
- JN 00200Documento4 páginasJN 00200Luis SolanoAún no hay calificaciones
- G#2 - Red Had OpenshiftDocumento12 páginasG#2 - Red Had OpenshiftDavid MoralesAún no hay calificaciones
- Introducción a Express y Node: ¿Qué son y cómo funcionanDocumento19 páginasIntroducción a Express y Node: ¿Qué son y cómo funcionanpehhhAún no hay calificaciones
- PEC1Documento6 páginasPEC1marioAún no hay calificaciones
- Contenedor Linux y Docker - ResumenDocumento6 páginasContenedor Linux y Docker - ResumenGustavo IribarrenAún no hay calificaciones
- CL Openshift and Kubernetes Ebook f25170wg 202010 A4 EsDocumento20 páginasCL Openshift and Kubernetes Ebook f25170wg 202010 A4 EsORLANDO CHAMORROAún no hay calificaciones
- Openstack - Modulo IDocumento32 páginasOpenstack - Modulo IAnonymous px6Tz9KPAún no hay calificaciones
- Instalación Cluster HA servidor web y VMsDocumento91 páginasInstalación Cluster HA servidor web y VMsAlan Rafael GaribayAún no hay calificaciones
- Sistemas operativos en la nubeDocumento10 páginasSistemas operativos en la nubeolga avelinoAún no hay calificaciones
- Presentacion - OpenSourceDocumento94 páginasPresentacion - OpenSourcemacv7304Aún no hay calificaciones
- Copia de Proxmox y XenserverDocumento7 páginasCopia de Proxmox y XenserverMelina AponteAún no hay calificaciones
- Proxmox VeDocumento5 páginasProxmox VebaironmeridaAún no hay calificaciones
- Docker: el entorno de desarrollo perfectoDocumento23 páginasDocker: el entorno de desarrollo perfectoDaniel NuñezAún no hay calificaciones
- Tema 6Documento24 páginasTema 6holajajaAún no hay calificaciones
- Guía completa de Novell NetwareDocumento12 páginasGuía completa de Novell Netwareronlei2014Aún no hay calificaciones
- MarcosDeDesarrolloI 03Documento38 páginasMarcosDeDesarrolloI 03Josue BarreraAún no hay calificaciones
- Ebook Openstack en 3 Sencillos PasosDocumento37 páginasEbook Openstack en 3 Sencillos PasosmarcosgarnicaAún no hay calificaciones
- Servidores WebDocumento60 páginasServidores WebAharon Alexander Aguas NavarroAún no hay calificaciones
- 1 ActividadDocumento4 páginas1 ActividadBrayan GalindoAún no hay calificaciones
- TALLER 1 - Resuelto - Claudia LozanoDocumento35 páginasTALLER 1 - Resuelto - Claudia LozanoDiego LakeAún no hay calificaciones
- Contenedor Linux y Docker - ResumenDocumento6 páginasContenedor Linux y Docker - ResumenGustavo IribarrenAún no hay calificaciones
- Informe de VirtualizacionDocumento9 páginasInforme de VirtualizacionCrawler 15Aún no hay calificaciones
- Instalacion NSXDocumento142 páginasInstalacion NSXFrancis CalderonAún no hay calificaciones
- Qué es la virtualización de redDocumento22 páginasQué es la virtualización de redCristhian OyolaAún no hay calificaciones
- VirtualizaciónDocumento54 páginasVirtualizaciónJairo E Márquez D100% (2)
- Instalación y configuración del software de servidor web. IFCT0509De EverandInstalación y configuración del software de servidor web. IFCT0509Aún no hay calificaciones
- Comparacion Entre Linux y FreeBSDDocumento32 páginasComparacion Entre Linux y FreeBSDJose NapoliAún no hay calificaciones
- CockpitDocumento3 páginasCockpitJose NapoliAún no hay calificaciones
- FreeBSD - Primeros PasosDocumento1 páginaFreeBSD - Primeros PasosJose NapoliAún no hay calificaciones
- Free RADIUSDocumento1 páginaFree RADIUSJose NapoliAún no hay calificaciones
- Comparativa Soluciones Opensource NetflowDocumento41 páginasComparativa Soluciones Opensource NetflowJose NapoliAún no hay calificaciones
- Usos de NextCloudDocumento38 páginasUsos de NextCloudJose NapoliAún no hay calificaciones
- A Tener en CuentaDocumento11 páginasA Tener en CuentaJose NapoliAún no hay calificaciones
- Iciv 1201 EfDocumento5 páginasIciv 1201 Efchicho silva manriqueAún no hay calificaciones
- 13.2.3.7 Lab - Bitlocker and Bitlocker To GoDocumento3 páginas13.2.3.7 Lab - Bitlocker and Bitlocker To GoRicardo TPM0% (1)
- Acceso A Instalaciones de Vodafone y TowerCo Con Llaves BluetoothDocumento10 páginasAcceso A Instalaciones de Vodafone y TowerCo Con Llaves BluetoothDani ArenasAún no hay calificaciones
- Sesion 2Documento22 páginasSesion 2alexanderrubio13Aún no hay calificaciones
- Cuestionario de Ciberseguridad 20201104 INTERSISADocumento4 páginasCuestionario de Ciberseguridad 20201104 INTERSISAIntersisa sistemasAún no hay calificaciones
- Sesion 19Documento12 páginasSesion 19Raksasa RepulsiveAún no hay calificaciones
- Prima Legal de ServiciosDocumento27 páginasPrima Legal de ServiciosCAMILO VALENCIAAún no hay calificaciones
- Licencias antivirus EAV By TutosBDocumento1 páginaLicencias antivirus EAV By TutosBJhordy Alexis Q DAún no hay calificaciones
- P - Unidad 2 CondicionalesDocumento45 páginasP - Unidad 2 CondicionalesdavidddgdsAún no hay calificaciones
- Esquema Cliente ServidorDocumento7 páginasEsquema Cliente ServidorCarlos PerezAún no hay calificaciones
- Integrales Pi-Áureas - GaussianosDocumento8 páginasIntegrales Pi-Áureas - GaussianosDiana VillalbaAún no hay calificaciones
- Caso 8 Registro de Compra de ProductosDocumento5 páginasCaso 8 Registro de Compra de Productoscarolina silva manriqueAún no hay calificaciones
- Impresora de Transferencia Térmica THERMOMARK ROLLDocumento39 páginasImpresora de Transferencia Térmica THERMOMARK ROLLElmer Huayra Huanhuayo100% (1)
- Unidad 6 Pensamiento ComputacionalDocumento18 páginasUnidad 6 Pensamiento Computacionaljohannaaguilarcondori2006Aún no hay calificaciones
- Libro Completo Introduccion A La ProgramacionDocumento342 páginasLibro Completo Introduccion A La ProgramacionAgus tomassetti100% (1)
- Ensayo Inteligencia MilitarDocumento7 páginasEnsayo Inteligencia Militarrivera jonathanAún no hay calificaciones
- Amazon Ec2Documento3 páginasAmazon Ec2Tatiana Sisiliano RivasAún no hay calificaciones
- Caso Apple Vs SamsungDocumento4 páginasCaso Apple Vs SamsungRonald SteveAún no hay calificaciones
- Ventas de Carlos VasquezDocumento80 páginasVentas de Carlos VasquezThomas Aquino Flores100% (1)
- Procedimientos Practica Rdci-6Documento17 páginasProcedimientos Practica Rdci-6Guillermo VallejoAún no hay calificaciones
- Guia-Navegación PLS 2021Documento20 páginasGuia-Navegación PLS 2021Isai LopezAún no hay calificaciones
- Guia de Instalacion Pic K-150Documento8 páginasGuia de Instalacion Pic K-150TazAún no hay calificaciones
- LayouttDocumento3 páginasLayouttFernando JuarezAún no hay calificaciones
- Guia 2 Tecnología Grado 10Documento6 páginasGuia 2 Tecnología Grado 10Tatys Mosquera TamayoAún no hay calificaciones
- Manual de Ajustes e InstalaciónDocumento112 páginasManual de Ajustes e Instalacióndegemule100% (1)
- Modelo C-S y MiddlewareDocumento21 páginasModelo C-S y MiddlewareBryan AlemanAún no hay calificaciones
- MapasDocumento4 páginasMapasThaily Arias MayAún no hay calificaciones
- Programacion 5Documento4 páginasProgramacion 5Antonio LorenteAún no hay calificaciones