También podría gustarte
- Documento de Apoyo 1 Cs 2021Documento6 páginasDocumento de Apoyo 1 Cs 2021bessieolivaAún no hay calificaciones
- Tabla de Pesos Fórmula 2021Documento2 páginasTabla de Pesos Fórmula 2021bessieoliva100% (1)
- Documento de Apoyo 2 MCD 2021Documento6 páginasDocumento de Apoyo 2 MCD 2021bessieolivaAún no hay calificaciones
- UNIDAD II, Parte 1 2017 Análisis TitrimétricoDocumento14 páginasUNIDAD II, Parte 1 2017 Análisis TitrimétricobessieolivaAún no hay calificaciones
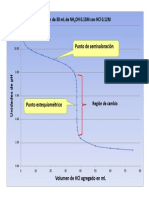
- Curva Nh4oh - HCLDocumento1 páginaCurva Nh4oh - HCLbessieolivaAún no hay calificaciones
- Tablas de IonizaciónDocumento2 páginasTablas de IonizaciónbessieolivaAún no hay calificaciones
- UNIDAD II Parte 6 Métodos Con YodoDocumento19 páginasUNIDAD II Parte 6 Métodos Con Yodobessieoliva100% (1)
- Unidad 3 Parte 3 ExtracciónDocumento43 páginasUnidad 3 Parte 3 ExtracciónbessieolivaAún no hay calificaciones
- Tablas de IonizaciónDocumento2 páginasTablas de IonizaciónbessieolivaAún no hay calificaciones
- UNIDAD I Parte 1 2017 (Equilibrio Químico Homogéneo Parte II)Documento20 páginasUNIDAD I Parte 1 2017 (Equilibrio Químico Homogéneo Parte II)bessieolivaAún no hay calificaciones
- Tabla de Pesos FórmulaDocumento2 páginasTabla de Pesos FórmulaFiorePGAún no hay calificaciones
- HT5Documento4 páginasHT5bessieoliva67% (3)
- Volumetría de PrecipitaciónDocumento6 páginasVolumetría de Precipitaciónbessieoliva0% (3)
- Curva de neutralización AB-BFDocumento6 páginasCurva de neutralización AB-BFbessieolivaAún no hay calificaciones
- Equilibrio Homogéneo en Disolución AcuosaDocumento29 páginasEquilibrio Homogéneo en Disolución AcuosabessieolivaAún no hay calificaciones
- Equilibrio Químico HeterogéneoDocumento31 páginasEquilibrio Químico HeterogéneobessieolivaAún no hay calificaciones
- VOLUMETRIA DE NEUTRALIZACIÓN - EstudiantesDocumento8 páginasVOLUMETRIA DE NEUTRALIZACIÓN - EstudiantesbessieolivaAún no hay calificaciones
- Hoja de Trabajo No. 3Documento2 páginasHoja de Trabajo No. 3bessieoliva75% (4)
- Tabla de Pesos FórmulaDocumento2 páginasTabla de Pesos FórmulabessieolivaAún no hay calificaciones
- Ejercicio 9, Guía Estudio PermanganimetríaDocumento1 páginaEjercicio 9, Guía Estudio Permanganimetríabessieoliva100% (3)
- Hoja de Trabajo No. 1: Escuela de Química Departamento de Análisis InorgánicoDocumento1 páginaHoja de Trabajo No. 1: Escuela de Química Departamento de Análisis InorgánicobessieolivaAún no hay calificaciones
- Hoja de Trabajo No. 2Documento1 páginaHoja de Trabajo No. 2bessieolivaAún no hay calificaciones
- Escuela de Química Departamento de Análisis InorgánicoDocumento2 páginasEscuela de Química Departamento de Análisis Inorgánicobessieoliva0% (1)
- Primer Parcial UPS Quito Herramientas Control Produccion 20211120 ELIASDocumento9 páginasPrimer Parcial UPS Quito Herramientas Control Produccion 20211120 ELIASElias CuasquerAún no hay calificaciones
- Consultas SNPDocumento16 páginasConsultas SNPreyescruztania.biolAún no hay calificaciones
- Actividad 2 Diseño Del Producto - Aguilar Jannely If-731 TMDocumento7 páginasActividad 2 Diseño Del Producto - Aguilar Jannely If-731 TMjannelyAún no hay calificaciones
- Ejercicios de Estadistica 1 Febrero 2,014Documento3 páginasEjercicios de Estadistica 1 Febrero 2,014yalide50% (2)
- Ejemplos Distribuciones Continuas y Números ÍndicesDocumento17 páginasEjemplos Distribuciones Continuas y Números ÍndicesEsme MartinezAún no hay calificaciones
- Actividad Taller 4.3Documento19 páginasActividad Taller 4.3Stephanie PulecioAún no hay calificaciones
- Compendio Guias Evaluacion SICEVAES-1Documento297 páginasCompendio Guias Evaluacion SICEVAES-1Luz G.0% (1)
- Proyecto Metodologia Casi FinalDocumento18 páginasProyecto Metodologia Casi FinalCarlos PupoAún no hay calificaciones
- CAPITULO 7 y 8 RESUMENDocumento5 páginasCAPITULO 7 y 8 RESUMENMia Karen PazAún no hay calificaciones
- ISO 9000 educaciónDocumento13 páginasISO 9000 educaciónAdrian Garcia100% (1)
- La Combinación de Estilos en Las Artes PlásticasDocumento2 páginasLa Combinación de Estilos en Las Artes PlásticasYazmin ReneroAún no hay calificaciones
- Articulo TecnicoDocumento3 páginasArticulo TecnicoGABRIELA ALEXANDRA GAITAN TUSELLAún no hay calificaciones
- 8 - Presentación CTE Octava SesiónDocumento31 páginas8 - Presentación CTE Octava SesiónJuan St. DovalAún no hay calificaciones
- Unidad-4 Taller 2019Documento31 páginasUnidad-4 Taller 2019David Banzer SalazarAún no hay calificaciones
- Taller EstadísticaDocumento34 páginasTaller EstadísticaViviana DuquinoAún no hay calificaciones
- De La Ciudad Vista A La Ciudad ImaginadaDocumento268 páginasDe La Ciudad Vista A La Ciudad ImaginadaPaula AndreaAún no hay calificaciones
- MK para Emprendedores Parte 1Documento11 páginasMK para Emprendedores Parte 1Jonathan AlajoAún no hay calificaciones
- Laboratorio 2Documento4 páginasLaboratorio 2Natalia CortesAún no hay calificaciones
- Taller 1Documento5 páginasTaller 1Jesus ZambranoAún no hay calificaciones
- Ejercicio - 2. - Bondad - de - Ajuste - Normal Diana Aurora Elizalde RiosDocumento4 páginasEjercicio - 2. - Bondad - de - Ajuste - Normal Diana Aurora Elizalde RiosDiana ElizaldeAún no hay calificaciones
- Altagracia Martínez Tesis de GradoDocumento94 páginasAltagracia Martínez Tesis de GradoAriel AlcántaraAún no hay calificaciones
- Nueva Segunda SerieDocumento2 páginasNueva Segunda SerieElizabeth ChavanaAún no hay calificaciones
- Diseño Informe1 PDFDocumento11 páginasDiseño Informe1 PDFjanetAún no hay calificaciones
- Neurociencia social y comportamiento humanoDocumento6 páginasNeurociencia social y comportamiento humanoMuñoz Landivar IreneAún no hay calificaciones
- SwalqolDocumento5 páginasSwalqolPaula Fernanda GonzálezAún no hay calificaciones
- Historia de La EstadisticaDocumento3 páginasHistoria de La EstadisticaRODOLFO ESTUARDO MIRANDA ARGUETAAún no hay calificaciones
- Laboratorio 1 - AjmcDocumento8 páginasLaboratorio 1 - AjmcJoss CastroAún no hay calificaciones
- La InteligenciaDocumento7 páginasLa InteligenciaDILENIA HERNANDEZ RAMIREZAún no hay calificaciones
- Prueba Escrita de Conocimientos 3 Dioses McoDocumento20 páginasPrueba Escrita de Conocimientos 3 Dioses McoAMERICA MICHELLE DEL ANGEL TORRESAún no hay calificaciones
- Análisis de Un Diseño de Medidas Repetidas - MinitabDocumento3 páginasAnálisis de Un Diseño de Medidas Repetidas - MinitabPatricio SaucedaAún no hay calificaciones