También podría gustarte
- Examen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2De EverandExamen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2Aún no hay calificaciones
- Consultas DistribuidasDocumento7 páginasConsultas DistribuidasArturo RodriguezAún no hay calificaciones
- Manual Final Practicas Base Datos DistribuidasDocumento44 páginasManual Final Practicas Base Datos Distribuidasmanuel0% (1)
- 1 4 Arquitectura de Base de Datos DistribuidasDocumento17 páginas1 4 Arquitectura de Base de Datos DistribuidasMin Eun Lee0% (1)
- Conceptos Basicos MYSQLDocumento12 páginasConceptos Basicos MYSQLMack Jak Grandez FloresAún no hay calificaciones
- SQL Server - Procedimientos AlmacenadosDocumento75 páginasSQL Server - Procedimientos Almacenadoscarmelo_esAún no hay calificaciones
- Estructuras Lógicas de AlmacenamientoDocumento5 páginasEstructuras Lógicas de AlmacenamientoCristian Alejandro Navarro MurilloAún no hay calificaciones
- Administración de sistemas gestores de bases de datosDe EverandAdministración de sistemas gestores de bases de datosAún no hay calificaciones
- Mecanismos de Seguridad Física y LógicaDocumento8 páginasMecanismos de Seguridad Física y LógicaJef JbeanAún no hay calificaciones
- Usuarios, Roles SQL 2008Documento70 páginasUsuarios, Roles SQL 2008kennethAún no hay calificaciones
- SQLServerDocumento26 páginasSQLServerAguiiss Marilican GomezAún no hay calificaciones
- Configuracion y Administracion de Espacio en DiscoDocumento22 páginasConfiguracion y Administracion de Espacio en DiscoRAFAELA FLORES MORALESAún no hay calificaciones
- Diferencia Entre MySQL y SQL Server PDFDocumento5 páginasDiferencia Entre MySQL y SQL Server PDFhugoflgAún no hay calificaciones
- Replicacion de Base de DatosDocumento5 páginasReplicacion de Base de DatosASTRIDAún no hay calificaciones
- Introduccion OracleDocumento27 páginasIntroduccion OracleFO RF100% (1)
- Administracion de Base de DatosDocumento5 páginasAdministracion de Base de Datosdandy100% (1)
- Manual Buenas Prácticas Codificación SQL ServerDocumento8 páginasManual Buenas Prácticas Codificación SQL ServerErick MaxAún no hay calificaciones
- Capitulo4 - BDD - Procesamiento de ConsultasDocumento80 páginasCapitulo4 - BDD - Procesamiento de ConsultasPierre Cadeau DolcéAún no hay calificaciones
- DDBB - Administración de Usuarios y Privilegios en MySQLDocumento6 páginasDDBB - Administración de Usuarios y Privilegios en MySQLtcondes100% (1)
- Manual de Trigger - SQL Server 2012Documento18 páginasManual de Trigger - SQL Server 2012RonaldRoldánSalinas100% (1)
- Replicacion y Cluster de Bases de DatosDocumento231 páginasReplicacion y Cluster de Bases de DatosCastro Rguez67% (3)
- SGBD5 SQLDocumento34 páginasSGBD5 SQLBryanSersoker100% (1)
- Creación de Una Bitácora en MysqlDocumento7 páginasCreación de Una Bitácora en MysqlEder Alexis PerezAún no hay calificaciones
- Usuarios Mysql SQL PDFDocumento7 páginasUsuarios Mysql SQL PDFneoelfeoAún no hay calificaciones
- Administracion de Bases de Datos - Unidad 3Documento17 páginasAdministracion de Bases de Datos - Unidad 3antonioAún no hay calificaciones
- Introducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2De EverandIntroducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2Aún no hay calificaciones
- Cuentas Usuario PDFDocumento13 páginasCuentas Usuario PDFPipe Amú RAún no hay calificaciones
- Roger Caamal Santiago Unidad6 Fundamentos de Base de Datos-.Isc j4Documento31 páginasRoger Caamal Santiago Unidad6 Fundamentos de Base de Datos-.Isc j4Roger CaamalAún no hay calificaciones
- Examen DiagnosticoDocumento5 páginasExamen DiagnosticoSAKURA -Aún no hay calificaciones
- Base de Datos - TriggersDocumento16 páginasBase de Datos - TriggersRonaldRoldánSalinasAún no hay calificaciones
- CUBODocumento23 páginasCUBOMichael Quispe SanchezAún no hay calificaciones
- 1.2. Análisis de Los Manejadores de Bases de DatosDocumento4 páginas1.2. Análisis de Los Manejadores de Bases de DatosMarisol Moreno M100% (1)
- DBD P2. TriggersDocumento11 páginasDBD P2. TriggersAntonio Molina RuizAún no hay calificaciones
- SUBCONSULTAS - Consultas AnidadasDocumento18 páginasSUBCONSULTAS - Consultas AnidadasasirAún no hay calificaciones
- Ejercicios Con Sentencias SQLDocumento15 páginasEjercicios Con Sentencias SQLFrancisco Hernan'Aún no hay calificaciones
- Estructura de Datos ArbolesDocumento26 páginasEstructura de Datos ArbolesPRESEN TAún no hay calificaciones
- Monitoreo en BDDocumento38 páginasMonitoreo en BDBipe Xolot PioAún no hay calificaciones
- Gestión de Usuarios y Permisos en MySQLDocumento16 páginasGestión de Usuarios y Permisos en MySQLDriss EL MokhtaryAún no hay calificaciones
- Unidad 3 Configuracion y Administracion de Espacio enDocumento19 páginasUnidad 3 Configuracion y Administracion de Espacio enRamis Gutiérrez DGAún no hay calificaciones
- Programación Del Lado Del ServidorDocumento40 páginasProgramación Del Lado Del ServidorNymphetamine LenoreAún no hay calificaciones
- Autorización y Permisos en SQL ServerDocumento8 páginasAutorización y Permisos en SQL ServerYair Ulises Sánchez PonceAún no hay calificaciones
- Programación WebDocumento19 páginasProgramación WebEnrique NájeraAún no hay calificaciones
- Practica Base de Datos Parcial IIIDocumento17 páginasPractica Base de Datos Parcial IIIManuel AngelesAún no hay calificaciones
- Crear Un Procedimiento en MySQLDocumento17 páginasCrear Un Procedimiento en MySQLAnonymous GFmbr7Aún no hay calificaciones
- Inserción, Actualización y Eliminación de RegistrosDocumento3 páginasInserción, Actualización y Eliminación de RegistrosJefry MartinezAún no hay calificaciones
- 1.conceptos BasicosDocumento25 páginas1.conceptos BasicosMariferAún no hay calificaciones
- Consultas SQL Sobre Una TablaDocumento27 páginasConsultas SQL Sobre Una TablaChiona ChioAún no hay calificaciones
- Bases de Datos DistribuidasDocumento9 páginasBases de Datos DistribuidasAngel VázquezAún no hay calificaciones
- Charla 2 MysqlDocumento53 páginasCharla 2 Mysqljoelrangel20Aún no hay calificaciones
- Bases de DatosDocumento4 páginasBases de DatosMichi SuhAún no hay calificaciones
- DB2 PDFDocumento18 páginasDB2 PDFds_leonidesAún no hay calificaciones
- Base de Datos DistribuidasDocumento18 páginasBase de Datos DistribuidasJuanCa Navarro VilelaAún no hay calificaciones
- FP U3 - Control de FlujoDocumento41 páginasFP U3 - Control de Flujojose sandovalAún no hay calificaciones
- Practica1 FragmentacionHorizDocumento5 páginasPractica1 FragmentacionHorizDistribuidos100% (1)
- Modelo RelacionalDocumento26 páginasModelo RelacionalOlinto Rodríguez AtencioAún no hay calificaciones
- Servidores Vinculados SQL ServerDocumento19 páginasServidores Vinculados SQL ServerNataly Zamudio LucianoAún no hay calificaciones
- Servidores VinculadosDocumento9 páginasServidores VinculadosJohnny Cotos SullonAún no hay calificaciones
- Controlador de Dominio Sobre MS Windows Server 2016, DNS y DHCP - Ragasys Sistemas PDFDocumento71 páginasControlador de Dominio Sobre MS Windows Server 2016, DNS y DHCP - Ragasys Sistemas PDFSantiago ZetchAún no hay calificaciones
- Servidores Vinculados 2014Documento12 páginasServidores Vinculados 2014Emmanuel Mena CorreaAún no hay calificaciones
- Aa5 - Evi 3-Migracion de Base de DatosDocumento53 páginasAa5 - Evi 3-Migracion de Base de DatosJohn OrregoAún no hay calificaciones
- Factores de ProducciónDocumento6 páginasFactores de Producciónjuancojc100% (1)
- El Primer Día de ClasesDocumento2 páginasEl Primer Día de ClasesEA NCAún no hay calificaciones
- Ejercicio Modulo 9.1Documento2 páginasEjercicio Modulo 9.1danilo arnaldo godoyAún no hay calificaciones
- Culto de ParejasDocumento4 páginasCulto de ParejasAndresAlvarezAún no hay calificaciones
- Tarea 3.1 Primer Avance Proyecto FinalDocumento4 páginasTarea 3.1 Primer Avance Proyecto FinalMayli VasquezAún no hay calificaciones
- Yeso Estuco VolcanDocumento6 páginasYeso Estuco VolcanNelson ColiñirAún no hay calificaciones
- Anisidina Peroxido Ag2283527Documento1 páginaAnisidina Peroxido Ag2283527Henry GuerreroAún no hay calificaciones
- Garcia Hernandez Karen LilianaDocumento5 páginasGarcia Hernandez Karen LilianaJanet MaReAún no hay calificaciones
- 5 Plano de Chimbote en El Contexto ProvincialDocumento1 página5 Plano de Chimbote en El Contexto ProvincialRebeca Cueva100% (1)
- Zonas FriasDocumento7 páginasZonas FriasMarisel Matamala MoralesAún no hay calificaciones
- Precipitación en Siete PasosDocumento5 páginasPrecipitación en Siete PasosNatalia Muñoz GutierrezAún no hay calificaciones
- Planificacion de MatematicasDocumento11 páginasPlanificacion de MatematicasjutiapaparaAún no hay calificaciones
- Tarea de VectoresDocumento7 páginasTarea de VectoresCristhian ChavezAún no hay calificaciones
- Curriculo Gir-Actualizado 1Documento22 páginasCurriculo Gir-Actualizado 1Jhosep ZpAún no hay calificaciones
- Ocupacion Moche Valles LambayequeDocumento26 páginasOcupacion Moche Valles LambayequeGio Vani Vargas PajaresAún no hay calificaciones
- RD 079-2022-Lp-DeDocumento9 páginasRD 079-2022-Lp-Decesar simonAún no hay calificaciones
- Mapa de Vida - TarotDocumento2 páginasMapa de Vida - Tarotmaryjuly860% (1)
- Diseño Digital de SonrisaDocumento8 páginasDiseño Digital de SonrisaLuis RománAún no hay calificaciones
- El Método de La Matriz BCGDocumento3 páginasEl Método de La Matriz BCGBrandon BáezAún no hay calificaciones
- Mezclas Racemicas (Expo) )Documento11 páginasMezclas Racemicas (Expo) )CRISYAISAL50% (2)
- Evidencia 4 Informe Variables Cuantitativas.Documento3 páginasEvidencia 4 Informe Variables Cuantitativas.Laura VargasAún no hay calificaciones
- Heidegger, El Pensar Técnico Como Culminación de La Historia de La Metafísica. Jesus Bravo RodrigoDocumento30 páginasHeidegger, El Pensar Técnico Como Culminación de La Historia de La Metafísica. Jesus Bravo RodrigoJesús BravoAún no hay calificaciones
- Taz PFC 2015 129Documento105 páginasTaz PFC 2015 129Navarro Viera Shary JazmínAún no hay calificaciones
- Fac 004-002-000000219Documento1 páginaFac 004-002-000000219MOOM SublimacionesAún no hay calificaciones
- Juegos de Cartas de La Baraja Tradicionales (Tenerife)Documento2 páginasJuegos de Cartas de La Baraja Tradicionales (Tenerife)Francisco García YanesAún no hay calificaciones
- Sig For Pri 028 Inspeccion Ssoma - Comedor - Es2Documento3 páginasSig For Pri 028 Inspeccion Ssoma - Comedor - Es2Noemi Ayala TacucheAún no hay calificaciones
- Test de La Ansiedad ZUNGDocumento4 páginasTest de La Ansiedad ZUNGPAOLITA83% (6)
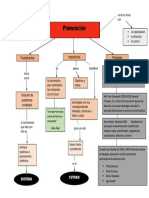
- PlaneaciónDocumento1 páginaPlaneaciónCA LRAún no hay calificaciones
- Métodos Diagnósticos en Hepatitis CDocumento7 páginasMétodos Diagnósticos en Hepatitis CDyanna García FloresAún no hay calificaciones
- I04 Instructivo para Toma de Muestras de AlimentosDocumento42 páginasI04 Instructivo para Toma de Muestras de AlimentosLuís Andelfo Pineda RamírezAún no hay calificaciones