También podría gustarte
- Realidad Aumentada - Rol Del Docente y Modelos Pedagógicos en El Proceso Educativo - Rodrigo ZamoraDocumento10 páginasRealidad Aumentada - Rol Del Docente y Modelos Pedagógicos en El Proceso Educativo - Rodrigo ZamoraXavier ZamoraAún no hay calificaciones
- Las Tic y La Educación Inclusiva Nuevos Desafíos - 25 Agosto ZamoraDocumento3 páginasLas Tic y La Educación Inclusiva Nuevos Desafíos - 25 Agosto ZamoraXavier ZamoraAún no hay calificaciones
- Realidad Aumentada - Rol Del Docente y Modelos Pedagógicos en El Proceso Educativo - Rodrigo ZamoraDocumento12 páginasRealidad Aumentada - Rol Del Docente y Modelos Pedagógicos en El Proceso Educativo - Rodrigo ZamoraXavier ZamoraAún no hay calificaciones
- Evolución de los formatos de MotherboardDocumento1 páginaEvolución de los formatos de MotherboardXavier ZamoraAún no hay calificaciones
- Entornos de Aprendizaje Ubicuo Con La Realidad Aumentada para Estimular El AprendizajeDocumento2 páginasEntornos de Aprendizaje Ubicuo Con La Realidad Aumentada para Estimular El AprendizajeXavier ZamoraAún no hay calificaciones
- EstadisticaDocumento13 páginasEstadisticaXavier ZamoraAún no hay calificaciones
- A Educacion o EducacionDocumento213 páginasA Educacion o EducacionalfnohayproblemAún no hay calificaciones
- Ideas Que Cambiarán El MundoDocumento7 páginasIdeas Que Cambiarán El MundoXavier ZamoraAún no hay calificaciones
- Elaboracion ProyectoDocumento10 páginasElaboracion ProyectoJorge SantaCruzAún no hay calificaciones
- Ariel Vercelli - Aprender La LibertadDocumento113 páginasAriel Vercelli - Aprender La LibertadLorem IpsumAún no hay calificaciones
- Pensamiento Computacional. Habilidades y TécnicasDocumento27 páginasPensamiento Computacional. Habilidades y TécnicasXavier ZamoraAún no hay calificaciones
- Guia Resuelta LogicaDocumento46 páginasGuia Resuelta LogicaPaulo Andres Vivallo88% (8)
- Proyecto Ricardo Mod Igual Al EnvDocumento50 páginasProyecto Ricardo Mod Igual Al EnvXavier ZamoraAún no hay calificaciones
- 1.3ficha de DatosDocumento4 páginas1.3ficha de DatosXavier ZamoraAún no hay calificaciones
- NEUROCIENCIAS Y NEE - Exposicion ZamoraDocumento3 páginasNEUROCIENCIAS Y NEE - Exposicion ZamoraXavier ZamoraAún no hay calificaciones
- Que Es Un Texto Cientifico GrupalDocumento32 páginasQue Es Un Texto Cientifico GrupalXavier ZamoraAún no hay calificaciones
- Proyecto de Aula de Sociedad y Cultura FilosofiaDocumento5 páginasProyecto de Aula de Sociedad y Cultura FilosofiaXavier ZamoraAún no hay calificaciones
- Maravillas Del MundoDocumento2 páginasMaravillas Del MundoXavier ZamoraAún no hay calificaciones
- CIM Tema 1 05 Teoria de ConjuntosDocumento6 páginasCIM Tema 1 05 Teoria de ConjuntosMarco BenitesAún no hay calificaciones
- Guia Resuelta LogicaDocumento46 páginasGuia Resuelta LogicaPaulo Andres Vivallo88% (8)
- Principales Articulos Del Estatuto de La UgDocumento13 páginasPrincipales Articulos Del Estatuto de La UgXavier ZamoraAún no hay calificaciones
- Proyecto Felipe GabyDocumento2 páginasProyecto Felipe GabyXavier ZamoraAún no hay calificaciones
- Inti RaymiDocumento2 páginasInti RaymiXavier ZamoraAún no hay calificaciones
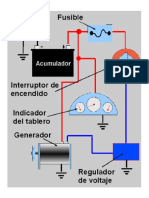
- Guia ElectricidadDocumento1 páginaGuia ElectricidadXavier ZamoraAún no hay calificaciones
- Taller # 1 Lenguaje Unidad 1Documento4 páginasTaller # 1 Lenguaje Unidad 1Xavier ZamoraAún no hay calificaciones
- Principales Articulos Del Estatuto de La UgDocumento13 páginasPrincipales Articulos Del Estatuto de La UgXavier ZamoraAún no hay calificaciones
- Hawking Libro 1Documento25 páginasHawking Libro 1Xavier ZamoraAún no hay calificaciones
- Ensenando para Cambiar Vidas HendricksDocumento179 páginasEnsenando para Cambiar Vidas HendricksXavier Zamora100% (1)
- Calendario Mundialrusia 2018 PDFDocumento1 páginaCalendario Mundialrusia 2018 PDFRommelAún no hay calificaciones
- El debate entre el empirismo y el racionalismoDocumento5 páginasEl debate entre el empirismo y el racionalismoALEXANDRAAún no hay calificaciones
- Etnias en El EcuadorDocumento23 páginasEtnias en El EcuadorVíctor Andrés Alcívar QuimísAún no hay calificaciones
- Azúcar, La Droga Del Siglo XXIDocumento5 páginasAzúcar, La Droga Del Siglo XXINatalia CabreraAún no hay calificaciones
- ServuccionDocumento2 páginasServuccionYorman YepezAún no hay calificaciones
- Acta de Incomparecencia Del AcusadoDocumento1 páginaActa de Incomparecencia Del AcusadoMilen GutierrezAún no hay calificaciones
- Reage, Pauline - Historia de ODocumento75 páginasReage, Pauline - Historia de OLed_Guevara100% (6)
- Cirugía UnguealDocumento14 páginasCirugía UnguealÓscar Reza Auhing100% (1)
- Catecismo 478Documento4 páginasCatecismo 478dulceAún no hay calificaciones
- 2 Taller Salud Mental - D'angelo ClavijoDocumento3 páginas2 Taller Salud Mental - D'angelo ClavijokwdjqwokdjqwkdjAún no hay calificaciones
- Ensayo-Importancia de Le Legislación EducativaDocumento3 páginasEnsayo-Importancia de Le Legislación Educativaalexangelf54% (13)
- 01 Diego HolsteinDocumento14 páginas01 Diego HolsteinMatías nicolasAún no hay calificaciones
- Los cuatro dones de Dios al hombreDocumento45 páginasLos cuatro dones de Dios al hombreyessica zarante100% (1)
- ACUMULATIVA DE ESPAÑOL TERCER PERIODODocumento3 páginasACUMULATIVA DE ESPAÑOL TERCER PERIODOSILVIA DANIELA BURITICA JEREZAún no hay calificaciones
- Resumen Ejecutivo Auditoria Interna ZeniaDocumento9 páginasResumen Ejecutivo Auditoria Interna ZeniaZenia Alvarez HornaAún no hay calificaciones
- SciFi #09Documento128 páginasSciFi #09CarlosACAún no hay calificaciones
- Lecturas Olvidadas (Lectura+Actividades)Documento3 páginasLecturas Olvidadas (Lectura+Actividades)LACLASEDEELEAún no hay calificaciones
- No Hay Lugar Mas AltoDocumento3 páginasNo Hay Lugar Mas AltoIsrael Joel Muñoz RodriguezAún no hay calificaciones
- TF Pea 3Documento25 páginasTF Pea 3Diego Bolaños VainsteinAún no hay calificaciones
- Cartilla Etica ContableDocumento7 páginasCartilla Etica ContableSherazade Beltran IncerAún no hay calificaciones
- Instalar Motor Trifásico Con Conmutación Estrella TriánguloDocumento9 páginasInstalar Motor Trifásico Con Conmutación Estrella TriánguloMiguel Angel MayorgaAún no hay calificaciones
- Sistemas Información GerencialDocumento79 páginasSistemas Información Gerencialandreapach23Aún no hay calificaciones
- Tema 10 El Cristal RealDocumento41 páginasTema 10 El Cristal RealgabrielAún no hay calificaciones
- Estudio TopograficoDocumento26 páginasEstudio TopograficoEdgar Saenz LizarbeAún no hay calificaciones
- Variables aleatorias problemas resueltosDocumento18 páginasVariables aleatorias problemas resueltosSakura RaAún no hay calificaciones
- Fichas AdDocumento17 páginasFichas AdHans Albert Gandulias VillanuevaAún no hay calificaciones
- Plan Estrategico de Desarrollo Juvenil para El Municipio de EnvigadoDocumento169 páginasPlan Estrategico de Desarrollo Juvenil para El Municipio de EnvigadoyycristinaAún no hay calificaciones
- Primeros AuxiliosDocumento2 páginasPrimeros AuxiliosCARLOSAún no hay calificaciones
- Arquitectura Gotica-GlosarioDocumento7 páginasArquitectura Gotica-GlosarioLuis Fernando Paulino FloresAún no hay calificaciones
- Brugger Ilse M de - Los Romanticos AlemanesDocumento99 páginasBrugger Ilse M de - Los Romanticos AlemanesClaudio Sanhueza100% (2)
- El Hombre Más Rico de Asia Te Enseña Cómo Invertir Tu Salario en Solo 5 PasosDocumento5 páginasEl Hombre Más Rico de Asia Te Enseña Cómo Invertir Tu Salario en Solo 5 PasosCarlos Amaya Arellano100% (1)