También podría gustarte
- Relleno de Poligonos PDFDocumento8 páginasRelleno de Poligonos PDFAndres Arcos VazquezAún no hay calificaciones
- Clasificacion Estandar Ferreteria y Bricolaje PDFDocumento16 páginasClasificacion Estandar Ferreteria y Bricolaje PDFAndres Arcos Vazquez0% (1)
- Relleno de Poligonos PDFDocumento8 páginasRelleno de Poligonos PDFAndres Arcos VazquezAún no hay calificaciones
- Sucursales BoxitoDocumento1 páginaSucursales BoxitoAndres Arcos VazquezAún no hay calificaciones
- Ejercicios SakilaDocumento5 páginasEjercicios Sakilamoszilargi0% (3)
- Examen 04 de Aritmética para Segundo de PrimariaDocumento6 páginasExamen 04 de Aritmética para Segundo de PrimariaSujel RojasAún no hay calificaciones
- Trigonometria 3° - Iii TrimDocumento92 páginasTrigonometria 3° - Iii TrimJorge Felix Rodriguez EulogioAún no hay calificaciones
- Sociales SextosDocumento7 páginasSociales SextosMeneses OlmesAún no hay calificaciones
- Lenguaje y Comunicacion Sexto Básico 2023Documento10 páginasLenguaje y Comunicacion Sexto Básico 2023magaly ortizAún no hay calificaciones
- Tecnicas de CuantificaciónDocumento3 páginasTecnicas de CuantificaciónVladimir López JimenezAún no hay calificaciones
- Habilitaciones para Grado 2019Documento5 páginasHabilitaciones para Grado 2019Chriztian RodiñoAún no hay calificaciones
- Entrevista DirigidaDocumento29 páginasEntrevista DirigidaPaula CarusoAún no hay calificaciones
- Seminario GlaucomaDocumento17 páginasSeminario GlaucomaElsiAún no hay calificaciones
- Geotecnia de Suelos PeruanosDocumento17 páginasGeotecnia de Suelos PeruanosJuan Carlos Gomez VegaAún no hay calificaciones
- Tabla de Semillas AsDocumento17 páginasTabla de Semillas Asimarli59Aún no hay calificaciones
- Mapa de Riesgo de OperacionesDocumento4 páginasMapa de Riesgo de OperacionesJULIO CESAR LOPEZ HUATUCO50% (2)
- Analisis y Produccion, Practica 1Documento4 páginasAnalisis y Produccion, Practica 1Gabriela SantanaAún no hay calificaciones
- Plan Anual de Trabajo 2024Documento20 páginasPlan Anual de Trabajo 2024Dionisio Mamani PilcoAún no hay calificaciones
- Tarea 7 Analisis Economico de La RegionDocumento6 páginasTarea 7 Analisis Economico de La RegionJavier EspañaAún no hay calificaciones
- Funciones de Nivel de ServidorDocumento4 páginasFunciones de Nivel de ServidorMithsuhiro PampañaupaAún no hay calificaciones
- Informe en Cuanto A La Extracion y Reconocimiento de Las Proteinas en La LecheDocumento16 páginasInforme en Cuanto A La Extracion y Reconocimiento de Las Proteinas en La LecheLucía VegaAún no hay calificaciones
- La Lucha Por El Dominio Geovial Del Petróleo.Documento17 páginasLa Lucha Por El Dominio Geovial Del Petróleo.Bruno CapassoAún no hay calificaciones
- Linea Del TiempoDocumento1 páginaLinea Del TiempoYisus Elbárbaro0% (1)
- Programa Anual de Seguridad y Salud en El TrabajoDocumento37 páginasPrograma Anual de Seguridad y Salud en El TrabajoJhonatan Huarca100% (1)
- Fis Mod DDocumento75 páginasFis Mod DValeria SelenaAún no hay calificaciones
- Revolución AgrícolaDocumento4 páginasRevolución AgrícolaLaura Bastías AedoAún no hay calificaciones
- Informe de Muro de Contencion 1Documento23 páginasInforme de Muro de Contencion 1YëyóSalasAún no hay calificaciones
- El Nuevo Paradigma de Seguridad CiudadanaDocumento6 páginasEl Nuevo Paradigma de Seguridad Ciudadanaosmel alvarezAún no hay calificaciones
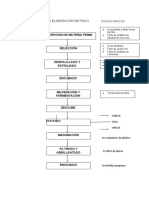
- Diagrama Del PiscoDocumento5 páginasDiagrama Del PiscoDina AntezanaAún no hay calificaciones
- Sitios Turísticos en CasmaDocumento2 páginasSitios Turísticos en CasmaRóger Édgard Antón FabiánAún no hay calificaciones
- Brouchure CedroDocumento14 páginasBrouchure CedroIngrid CamachoAún no hay calificaciones
- Introduccion PEPDocumento45 páginasIntroduccion PEPMatias AlvealAún no hay calificaciones
- Reservorios Convencionales y No Convencionales, de Petróleo y Gas. Particularidades y Diferencias. (Artículo Lasalle)Documento12 páginasReservorios Convencionales y No Convencionales, de Petróleo y Gas. Particularidades y Diferencias. (Artículo Lasalle)Diego D. Lasalle100% (1)
- BTV ElectrónicaDocumento147 páginasBTV Electrónicacdjgp100% (1)