También podría gustarte
- Modulo Tecnologia 5Documento81 páginasModulo Tecnologia 5insprossur villanuevaAún no hay calificaciones
- Confeccion Tablas de Verdad 2014 v2Documento36 páginasConfeccion Tablas de Verdad 2014 v2Juan FernandezAún no hay calificaciones
- Anonimato en El Carding PDFDocumento21 páginasAnonimato en El Carding PDFEsteban Camilo Ortiz ZambranoAún no hay calificaciones
- Los Sonambulos - Arthur KoestlerDocumento522 páginasLos Sonambulos - Arthur KoestlerCarlos Esescritor100% (1)
- Guia de Analisis Matematico CBC PDFDocumento79 páginasGuia de Analisis Matematico CBC PDFzxcvbsAún no hay calificaciones
- Capitulo 3 ACTIVIDADocumento1 páginaCapitulo 3 ACTIVIDAzombexAún no hay calificaciones
- CardinDocumento2 páginasCardinvilma quinoAún no hay calificaciones
- Capitulo 3 ACTIVIDADocumento1 páginaCapitulo 3 ACTIVIDAzombexAún no hay calificaciones
- Número PARy IMPARDocumento1 páginaNúmero PARy IMPARzombexAún no hay calificaciones
- Antic It EraDocumento7 páginasAntic It EraLuisFernandoStoccoAún no hay calificaciones
- ACTIVIDADDocumento1 páginaACTIVIDADzombexAún no hay calificaciones
- ACTIVIDADCap 1Documento1 páginaACTIVIDADCap 1zombexAún no hay calificaciones
- Actividades Resueltas Capítulo 2 PDFDocumento27 páginasActividades Resueltas Capítulo 2 PDFAlejandro VillalbaAún no hay calificaciones
- Carta Inicial PDFDocumento1 páginaCarta Inicial PDFzombexAún no hay calificaciones
- ApuntesDocumento1 páginaApunteszombexAún no hay calificaciones
- Hempel SemmelweisDocumento6 páginasHempel SemmelweisJuan Pablo Martinez MonteroAún no hay calificaciones
- Hempel SemmelweisDocumento6 páginasHempel SemmelweisJuan Pablo Martinez MonteroAún no hay calificaciones
- Subir A Scribd para Desdargar Un Documento y No Me Gjoda MasDocumento8 páginasSubir A Scribd para Desdargar Un Documento y No Me Gjoda MaszombexAún no hay calificaciones
- Dialnet CarlGHempelFilosofiaDeLaCienciaNatural 4378666 PDFDocumento3 páginasDialnet CarlGHempelFilosofiaDeLaCienciaNatural 4378666 PDFbelencaveroAún no hay calificaciones
- Subir A Scribd para Desdargar Un Documento y No Me Gjoda MasDocumento1 páginaSubir A Scribd para Desdargar Un Documento y No Me Gjoda MaszombexAún no hay calificaciones
- Pegoraro. Mara, Zulcovsky Florencia, "Gobierno"Documento1 páginaPegoraro. Mara, Zulcovsky Florencia, "Gobierno"zombexAún no hay calificaciones
- Link La Dicta Dura SubirDocumento1 páginaLink La Dicta Dura SubirzombexAún no hay calificaciones
- Link La Dicta Dura SubirDocumento1 páginaLink La Dicta Dura SubirzombexAún no hay calificaciones
- Ingenieria en SistemasDocumento10 páginasIngenieria en SistemasAndrea Nayeli CárdenasAún no hay calificaciones
- SGMWin EsDocumento21 páginasSGMWin EsPIDS SASAún no hay calificaciones
- H3 - User Manual - ES (LA) - V1.0.0Documento14 páginasH3 - User Manual - ES (LA) - V1.0.0Rosario RoblesAún no hay calificaciones
- Teoría de Seguridad de La InformaciónDocumento4 páginasTeoría de Seguridad de La InformaciónAlexander JoyaAún no hay calificaciones
- Ejercicios Funcion (Y - O) - Excel IntermedioDocumento9 páginasEjercicios Funcion (Y - O) - Excel IntermedioOE Mendoza PerezAún no hay calificaciones
- Cronograma de Contenidos 4Documento10 páginasCronograma de Contenidos 4musicAún no hay calificaciones
- Líneas CMDDocumento2 páginasLíneas CMDLuis PozoAún no hay calificaciones
- Word - Lecccion1-Descripcion de WordDocumento24 páginasWord - Lecccion1-Descripcion de WordKenia LopezAún no hay calificaciones
- CP ST - Práctica 10Documento2 páginasCP ST - Práctica 10Chris A RuedaAún no hay calificaciones
- ChatDocumento1308 páginasChatkeibertsisaAún no hay calificaciones
- Qué Es Visual BasicDocumento30 páginasQué Es Visual BasicWilder Cercado ChuquilnAún no hay calificaciones
- Errores Comunes REPUVEDocumento12 páginasErrores Comunes REPUVEJuan Lopez0% (1)
- Minitab 17-Ava-Sesion 3-Tarea-1.1Documento4 páginasMinitab 17-Ava-Sesion 3-Tarea-1.1Edwin BatallanosAún no hay calificaciones
- 10.anexo GA2 220601501 AA2 EV01Documento3 páginas10.anexo GA2 220601501 AA2 EV01Armandob BaronaAún no hay calificaciones
- Formato de Mapa ConceptualDocumento5 páginasFormato de Mapa ConceptualGina RiveraAún no hay calificaciones
- LISTADO DE LIBROS DIGITALES Carrera de SoftwarsDocumento1 páginaLISTADO DE LIBROS DIGITALES Carrera de SoftwarsLuis MolinaAún no hay calificaciones
- Guía 1 - 3 Colores para Balancear Tus Comidas PDFDocumento2 páginasGuía 1 - 3 Colores para Balancear Tus Comidas PDFNicole Contreras JulioAún no hay calificaciones
- Módulo 3 - El Teclado y Sus PosibilidadesDocumento14 páginasMódulo 3 - El Teclado y Sus Posibilidadesjorge CahuanaAún no hay calificaciones
- Apuntes Metodo SimplexDocumento12 páginasApuntes Metodo SimplexAndrea Meneses SalasAún no hay calificaciones
- Introduccion A Ingenieria WebDocumento6 páginasIntroduccion A Ingenieria WebJhon Eliberto Baquero Casta�edaAún no hay calificaciones
- Clase ObjectDocumento36 páginasClase ObjectLINDA CAROL CALDERON AREVALOAún no hay calificaciones
- Definición de Programación - Qué Es, Significado y ConceptoDocumento3 páginasDefinición de Programación - Qué Es, Significado y ConceptoBrayan ForeroAún no hay calificaciones
- Caso de Prueba CubicajeDocumento5 páginasCaso de Prueba CubicajeCLAUDIA MARCELA STEELE CASTILLOAún no hay calificaciones
- Módulo 4 - Representación Gráfica de ProcesosDocumento91 páginasMódulo 4 - Representación Gráfica de ProcesosFrancisco Maximiliano PerezAún no hay calificaciones
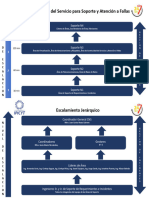
- Escalamiento Del Servicio para Soporte y Atención A Fallas: N I V E L D E E S C A L A C I O NDocumento2 páginasEscalamiento Del Servicio para Soporte y Atención A Fallas: N I V E L D E E S C A L A C I O NCecilia Ixtchel Zapata SanchezAún no hay calificaciones
- Brochure Bim AcpDocumento15 páginasBrochure Bim AcpANA LUCIA HUALLPARIMACHI GARCIAAún no hay calificaciones
- Introducción A La Teoría de Lenguajes Formales 1Documento53 páginasIntroducción A La Teoría de Lenguajes Formales 1Saul GonzalezAún no hay calificaciones
- Intro PHPDocumento9 páginasIntro PHPAndres SalcedoAún no hay calificaciones
- Windows Server 2008-2019Documento2 páginasWindows Server 2008-2019Diego CiancaAún no hay calificaciones