También podría gustarte
- Eia Sapallanga UltimoDocumento88 páginasEia Sapallanga UltimoHarry David Bello Palacios0% (1)
- Tf-G4-Caso de NegocioDocumento25 páginasTf-G4-Caso de NegocioMarco Antonio Chambilla LlerenaAún no hay calificaciones
- La IA - El Superyo Del Siglo 21Documento8 páginasLa IA - El Superyo Del Siglo 21lazaro maiz100% (1)
- Gille, Bertrand - Introduccion A La Historia de Las Tecnicas-1Documento103 páginasGille, Bertrand - Introduccion A La Historia de Las Tecnicas-1perebausa100% (1)
- Res. 016 15Documento51 páginasRes. 016 15emily_manceboAún no hay calificaciones
- D Ind Itc Ind HBK 2011 PDF SDocumento154 páginasD Ind Itc Ind HBK 2011 PDF Slazaro maizAún no hay calificaciones
- FP Rev2013 SDocumento2 páginasFP Rev2013 Slazaro maizAún no hay calificaciones
- Manual Regulatorio ASIET - Act 12 - 2017Documento74 páginasManual Regulatorio ASIET - Act 12 - 2017lazaro maizAún no hay calificaciones
- Norma Iso 9000-2000 SGC PDFDocumento7 páginasNorma Iso 9000-2000 SGC PDFALCON56YUIAún no hay calificaciones
- Conceptos ISO 9000-2005Documento21 páginasConceptos ISO 9000-2005ivan1ivan2100% (6)
- Fraud Analytics Using Data Mining - En.esDocumento11 páginasFraud Analytics Using Data Mining - En.eslazaro maizAún no hay calificaciones
- Herramientas de Minería de DatosDocumento9 páginasHerramientas de Minería de DatosSaul HermanoAún no hay calificaciones
- Implementación de Técnicas de MD en Aplicaciones Web Con BDDocumento6 páginasImplementación de Técnicas de MD en Aplicaciones Web Con BDlazaro maizAún no hay calificaciones
- Hacia Un Nuevo Proceso de Minería de Datos Centrado en El UsuarioDocumento20 páginasHacia Un Nuevo Proceso de Minería de Datos Centrado en El Usuariolazaro maizAún no hay calificaciones
- El Uso de Herramientas Tecnológicas de Minería de Datos en El Análisis de Datos ClimatológicosDocumento18 páginasEl Uso de Herramientas Tecnológicas de Minería de Datos en El Análisis de Datos Climatológicoslazaro maizAún no hay calificaciones
- Mineria de Datos en La Web - c19Documento46 páginasMineria de Datos en La Web - c19lazaro maizAún no hay calificaciones
- El Futuro Cognitivo en Las TelcomDocumento24 páginasEl Futuro Cognitivo en Las Telcomlazaro maizAún no hay calificaciones
- Cuadro Comparativo Conceptos DM y OtrosDocumento4 páginasCuadro Comparativo Conceptos DM y Otroslazaro maizAún no hay calificaciones
- Análisis de La Calidad de Servicio en Las Telecom y Impacto en Indicador Mundial de Las TIC PDFDocumento112 páginasAnálisis de La Calidad de Servicio en Las Telecom y Impacto en Indicador Mundial de Las TIC PDFlazaro maizAún no hay calificaciones
- Aplicacion de La Mineria de Datos Sobre BasesDocumento9 páginasAplicacion de La Mineria de Datos Sobre Baseslazaro maizAún no hay calificaciones
- Dossier de Prensa 2016Documento33 páginasDossier de Prensa 2016lazaro maizAún no hay calificaciones
- BI Generalidades y DMDocumento63 páginasBI Generalidades y DMlazaro maizAún no hay calificaciones
- Estrategía para La Recepción de Pedidos Apoyada en Predicciones de Negocio Con Business Intelligence PDFDocumento13 páginasEstrategía para La Recepción de Pedidos Apoyada en Predicciones de Negocio Con Business Intelligence PDFlazaro maizAún no hay calificaciones
- Funcionalidades de La Mineria de DatosDocumento10 páginasFuncionalidades de La Mineria de Datoslazaro maizAún no hay calificaciones
- Res. 016 15Documento51 páginasRes. 016 15emily_manceboAún no hay calificaciones
- BI Generalidades y DMDocumento63 páginasBI Generalidades y DMlazaro maizAún no hay calificaciones
- Aplicacion de La Mineria de Datos Sobre BasesDocumento9 páginasAplicacion de La Mineria de Datos Sobre Baseslazaro maizAún no hay calificaciones
- Crispdm 12636302549091 Phpapp02Documento57 páginasCrispdm 12636302549091 Phpapp02lazaro maizAún no hay calificaciones
- Crispdm 12636302549091 Phpapp02Documento5 páginasCrispdm 12636302549091 Phpapp02Ericking Wilches TrujilloAún no hay calificaciones
- T REC M.3050 200405 I!Sup3!PDF S PDFDocumento84 páginasT REC M.3050 200405 I!Sup3!PDF S PDFlazaro maizAún no hay calificaciones
- T Rec M.3050.1 200406 S!!PDF SDocumento60 páginasT Rec M.3050.1 200406 S!!PDF Slazaro maizAún no hay calificaciones
- Modelo Informatica Subtel 091203Documento66 páginasModelo Informatica Subtel 091203lazaro maizAún no hay calificaciones
- Mi CuerpoDocumento30 páginasMi CuerpoDarly Yohana50% (2)
- Tesis Impresion CeramicaDocumento92 páginasTesis Impresion CeramicaVictor TufinioAún no hay calificaciones
- ST24001.950.221013 Formato Calibración y Verificación Instrumentación Switchs FlujoDocumento2 páginasST24001.950.221013 Formato Calibración y Verificación Instrumentación Switchs FlujoInstrumentación IndustrialAún no hay calificaciones
- Calculo de EdadDocumento4 páginasCalculo de EdadMarcelo RamosAún no hay calificaciones
- Contrato de Prestamo: 1. Información Del AcreedorDocumento6 páginasContrato de Prestamo: 1. Información Del AcreedorJorge GonzalezAún no hay calificaciones
- Reporte Ciclo Combinado M.ADocumento3 páginasReporte Ciclo Combinado M.AMario AndradeAún no hay calificaciones
- Laboratorio Gel para CabelloDocumento2 páginasLaboratorio Gel para CabelloMauricio Quintero100% (1)
- Practica Dirigida 4Documento3 páginasPractica Dirigida 4Fernando Valdez CarpioAún no hay calificaciones
- Ejercicios Sobre Estructuras RepetitivasDocumento1 páginaEjercicios Sobre Estructuras RepetitivasAlvaro HernandezAún no hay calificaciones
- Descriptor de Cargo - Camión Aljibe Gastón MuñozDocumento3 páginasDescriptor de Cargo - Camión Aljibe Gastón MuñozJonathan Philip O'Brien RamirezAún no hay calificaciones
- Mecanismos para OrientarseDocumento5 páginasMecanismos para OrientarseBiblioteca elcopey-cesar.gov.coAún no hay calificaciones
- ¿Quién Era El Joven Que Seguía Desnudo A Jesús Blog de Francisco Díaz SJDocumento4 páginas¿Quién Era El Joven Que Seguía Desnudo A Jesús Blog de Francisco Díaz SJHARVEY ALEXANDER SUAREZ MARTINEZAún no hay calificaciones
- Logros de La CruzDocumento4 páginasLogros de La Cruzgabriel adarveAún no hay calificaciones
- Ingenieria CivilDocumento1 páginaIngenieria CivilDaniel CaychoAún no hay calificaciones
- Pecado de Omisión - Ana María MatuteDocumento2 páginasPecado de Omisión - Ana María MatuteCeleste Velázquez100% (2)
- Clasificacion Del Gasto PublicoDocumento6 páginasClasificacion Del Gasto PublicoEyeline Aguilar100% (1)
- Libro Chile Valladolid PDFDocumento130 páginasLibro Chile Valladolid PDFJose AguayoAún no hay calificaciones
- Memoria Descriptiva - ArquitecturaDocumento3 páginasMemoria Descriptiva - Arquitecturalucho champi quispeAún no hay calificaciones
- Ebook La Risa en Las Experiencias de AprendizajeDocumento10 páginasEbook La Risa en Las Experiencias de AprendizajebarazarteernestoAún no hay calificaciones
- Sistema Operativo IDocumento34 páginasSistema Operativo IRenato RamirezAún no hay calificaciones
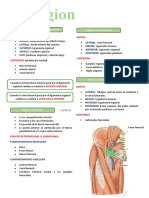
- Región CruralDocumento4 páginasRegión CruralNicole RomeroAún no hay calificaciones
- Clases Mataderos 1 ParteDocumento24 páginasClases Mataderos 1 ParteDiego Tomas Corradine Mora0% (1)
- Bases Conceptuales Acerca Lenguaje Unificado Modelado UML y Patrones DiseñoDocumento8 páginasBases Conceptuales Acerca Lenguaje Unificado Modelado UML y Patrones DiseñoEdwin Alexander Ospina PennaAún no hay calificaciones
- Disepser FT-VHC-VPCDocumento2 páginasDisepser FT-VHC-VPCjesusAún no hay calificaciones
- Evaporímetro de La SombraDocumento12 páginasEvaporímetro de La Sombraanthony gonzalezAún no hay calificaciones
- Ensayo Industria 4.0Documento1 páginaEnsayo Industria 4.0Pagigi LoloAún no hay calificaciones
- Tarea Algebra N 6Documento1 páginaTarea Algebra N 6Henry Condori HuallpaAún no hay calificaciones