También podría gustarte
- Analisis y Proyeccion de La DemandaDocumento24 páginasAnalisis y Proyeccion de La DemandaLuli PalaciosAún no hay calificaciones
- Guia de Trabajos Practicos Micro 2011 DEEFIDocumento89 páginasGuia de Trabajos Practicos Micro 2011 DEEFIChristián Zurita ZumaránAún no hay calificaciones
- 4 EconometriasDocumento81 páginas4 EconometriaskrisbrickerAún no hay calificaciones
- La Metodología de Vectores Autorregresivos (Var)Documento26 páginasLa Metodología de Vectores Autorregresivos (Var)J Luis ChAún no hay calificaciones
- CAPITULO4 Supuestos de NormalidadDocumento11 páginasCAPITULO4 Supuestos de NormalidadFlor Chura YucraAún no hay calificaciones
- Métodos Cuantitativos II: Análisis de Varianza y RegresiónDocumento132 páginasMétodos Cuantitativos II: Análisis de Varianza y RegresiónDannyGabrielAún no hay calificaciones
- Tablas de Frecuencia para Variables Cuantitativas Discretas y ContinuasDocumento59 páginasTablas de Frecuencia para Variables Cuantitativas Discretas y ContinuasAbelito GF100% (1)
- Rseumen Cap. 2Documento3 páginasRseumen Cap. 2Aiferricorti convoAún no hay calificaciones
- Método SimplexDocumento11 páginasMétodo SimplexLaura Andrade SBAún no hay calificaciones
- Capítulo 14-PanelDocumento10 páginasCapítulo 14-PanelBrian SilvaAún no hay calificaciones
- Estimadores MCODocumento15 páginasEstimadores MCOLina CadenaAún no hay calificaciones
- 2Documento8 páginas2Wilfredo PariAún no hay calificaciones
- Analisis de MarkovDocumento47 páginasAnalisis de MarkovChristian LeónAún no hay calificaciones
- Tarea gestión de ventasDocumento3 páginasTarea gestión de ventashgd2692sqwAún no hay calificaciones
- MulticolineidadDocumento21 páginasMulticolineidadJose PepeAún no hay calificaciones
- Econometría II: Modelos VAR resueltosDocumento14 páginasEconometría II: Modelos VAR resueltosAbelord TaVoAún no hay calificaciones
- Sem III Silabo - Matematica Financiera IDocumento7 páginasSem III Silabo - Matematica Financiera IZegarra RichardAún no hay calificaciones
- Ejercicios Resueltos Guia 1Documento4 páginasEjercicios Resueltos Guia 1PaolaValoz'Aún no hay calificaciones
- Separata 14Documento9 páginasSeparata 14Adrian CassanoAún no hay calificaciones
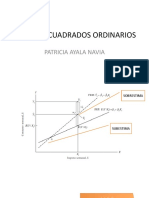
- 4.mínimos Cuadrados OrdinariosDocumento66 páginas4.mínimos Cuadrados Ordinariospatty100% (1)
- Numeros IndicesDocumento37 páginasNumeros IndicesMaría Soledad CarreñoAún no hay calificaciones
- Ecuaciones Diferenciales UNMSMDocumento4 páginasEcuaciones Diferenciales UNMSMXimena AcAún no hay calificaciones
- Preguntas Curso de Extension Universitaria BCRP 2019Documento4 páginasPreguntas Curso de Extension Universitaria BCRP 2019Jennifer IquiapazaAún no hay calificaciones
- Modelos Regresión Lineal para Predecir El Precio de ViviendasDocumento41 páginasModelos Regresión Lineal para Predecir El Precio de ViviendasJuan PerezAún no hay calificaciones
- Auditoría de personal: remuneraciones y cargas socialesDocumento9 páginasAuditoría de personal: remuneraciones y cargas socialesneipAún no hay calificaciones
- Apuntes Docente PDFDocumento52 páginasApuntes Docente PDFXiomara BarónAún no hay calificaciones
- EViews 10 Users Guide II-751-1000Documento250 páginasEViews 10 Users Guide II-751-1000Caqui P. comAún no hay calificaciones
- Logica Matiematica Tarea Virtual 6Documento3 páginasLogica Matiematica Tarea Virtual 6Tutos y Algo más LibraryAún no hay calificaciones
- Unidad II - Funcionamiento Del MercadoDocumento53 páginasUnidad II - Funcionamiento Del MercadoMarco Willam Aburto Rodrìguez0% (1)
- 170 Errores en Valoraciones de Empresas PDFDocumento47 páginas170 Errores en Valoraciones de Empresas PDFAnonymous gnGgs630nAún no hay calificaciones
- Taller Impuesto A La Renta (U2-Clase 17)Documento32 páginasTaller Impuesto A La Renta (U2-Clase 17)fer SalAún no hay calificaciones
- Recopilacion Certamenes 1 IcofiDocumento65 páginasRecopilacion Certamenes 1 IcofiChaparrón BonaparteAún no hay calificaciones
- Microeconometría: Modelos de regresión lineal múltipleDocumento65 páginasMicroeconometría: Modelos de regresión lineal múltiplecarlos sebastianAún no hay calificaciones
- Proyecto Final Estadistica IIDocumento14 páginasProyecto Final Estadistica IIalejandraAún no hay calificaciones
- Indicadores FinancierosDocumento12 páginasIndicadores FinancierosEdwin Checa50% (2)
- Regresión lineal múltiple: introducción al modelo, estimación y predicciónDocumento19 páginasRegresión lineal múltiple: introducción al modelo, estimación y predicciónrogerfernandezhidalgAún no hay calificaciones
- MODELOS REGRESION Logistica PDFDocumento37 páginasMODELOS REGRESION Logistica PDFAllen Martinez100% (1)
- 1.econometría Financiera - Modelo Retorno RiesgoDocumento18 páginas1.econometría Financiera - Modelo Retorno RiesgoJose ZuñigaAún no hay calificaciones
- Ecuaciones HomogéneasDocumento5 páginasEcuaciones HomogéneasJc Miranda Guzman100% (1)
- Matemáticas Financieras Rodríguez, Pierdant, Rodríguez PDFDocumento32 páginasMatemáticas Financieras Rodríguez, Pierdant, Rodríguez PDFKarem Michelle Mondragon VarelaAún no hay calificaciones
- ApuntesDocumento195 páginasApuntesmenriquecAún no hay calificaciones
- Barreras Tecnicas y Legales MonopolioDocumento3 páginasBarreras Tecnicas y Legales Monopoliocecylodvg100% (1)
- Prueba de Jarque-BeraDocumento1 páginaPrueba de Jarque-BeraJose Miguel Avilez BozoAún no hay calificaciones
- Introducción a StataDocumento21 páginasIntroducción a StataMisael Caro RuizAún no hay calificaciones
- Gestión táctica de operaciones: pronósticos y series de tiempoDocumento38 páginasGestión táctica de operaciones: pronósticos y series de tiempoJau Joao CalveraAún no hay calificaciones
- Flores Audante Edgar Jairo Jesus TransmisionDocumento67 páginasFlores Audante Edgar Jairo Jesus TransmisionFranklin Inga GarciaAún no hay calificaciones
- Pronostico Demanda - May 2018Documento99 páginasPronostico Demanda - May 2018Pablo_C1976Aún no hay calificaciones
- Mexder PresentacionDocumento44 páginasMexder PresentacionFAUSTINOESTEBANAún no hay calificaciones
- Macroeconomia I Al 2019Documento97 páginasMacroeconomia I Al 2019Estefany Moreno0% (1)
- Extensiones Regresion LinealDocumento45 páginasExtensiones Regresion LinealPerdomo JoelAún no hay calificaciones
- Análisis de inversiones alternativasEl título resume de manera concisa el contenido del documento, que analiza diferentes alternativas de inversión para un cliente, sin exceder los requeridosDocumento21 páginasAnálisis de inversiones alternativasEl título resume de manera concisa el contenido del documento, que analiza diferentes alternativas de inversión para un cliente, sin exceder los requeridosAleidayaneida SPAún no hay calificaciones
- EconometriaDocumento63 páginasEconometriaIvan Giraldo Cardenas AñascoAún no hay calificaciones
- Analisis Del Equilibrio ParcialDocumento63 páginasAnalisis Del Equilibrio ParcialCess VilcasAún no hay calificaciones
- Act 9 Finanzas para Nuevos NegociosDocumento2 páginasAct 9 Finanzas para Nuevos NegociosMax ManzanarezAún no hay calificaciones
- Método de Mellin para análisis de incertidumbre en sistemas hidráulicosDocumento10 páginasMétodo de Mellin para análisis de incertidumbre en sistemas hidráulicosPedro Anibal Mendoza LuichoAún no hay calificaciones
- Correlacion y Regresion. Contraste de HipotesisDocumento39 páginasCorrelacion y Regresion. Contraste de Hipotesisarianny100% (1)
- Análisis de tablas bidimensionales de frecuencias para variables cuantitativas y cualitativasDocumento21 páginasAnálisis de tablas bidimensionales de frecuencias para variables cuantitativas y cualitativasSmith Tandaypan NavezAún no hay calificaciones
- Bidimensional Correlacion Regresion1461859284124Documento31 páginasBidimensional Correlacion Regresion1461859284124Luis Huapaya FriasAún no hay calificaciones
- Apuntes Estadística 1º Bachillerato Ciencias SocialesDocumento7 páginasApuntes Estadística 1º Bachillerato Ciencias SocialesAlguienTPAún no hay calificaciones
- Wuolah-free-Tema 8 Regresion 2017 18Documento19 páginasWuolah-free-Tema 8 Regresion 2017 18juan navoAún no hay calificaciones
- RIDAA Decreto MOP 752 21.7.03 Anexos PDFDocumento64 páginasRIDAA Decreto MOP 752 21.7.03 Anexos PDFKaren GraceAún no hay calificaciones
- Leyes Sociales para Obras CivilesDocumento3 páginasLeyes Sociales para Obras CivilesCarli NavarroAún no hay calificaciones
- MC - V4 - 2016 Planos de Obras TipoDocumento408 páginasMC - V4 - 2016 Planos de Obras TipoKarina Saras HernandezAún no hay calificaciones
- Especificaciones TécnicasDocumento36 páginasEspecificaciones TécnicasCarli NavarroAún no hay calificaciones
- Amortiguadores SismicosDocumento12 páginasAmortiguadores SismicosCarli NavarroAún no hay calificaciones
- LEED v4 BD+C ESPDocumento153 páginasLEED v4 BD+C ESPAarón Isaac Espíritu RojasAún no hay calificaciones
- Bases Administrativas GeneralesDocumento12 páginasBases Administrativas GeneralesCarli NavarroAún no hay calificaciones
- MC V5 2014Documento685 páginasMC V5 2014Carlos Troncoso SanhuezaAún no hay calificaciones
- Apunte Leyes SocialesDocumento5 páginasApunte Leyes SocialesCarli NavarroAún no hay calificaciones
- Calidad y Mejora Continua INFODocumento2 páginasCalidad y Mejora Continua INFOCarli NavarroAún no hay calificaciones
- CAPITULO 1 Apuntes de Cubicación USACHDocumento20 páginasCAPITULO 1 Apuntes de Cubicación USACHCristian Vega67% (3)
- Capítulo 4: Despacho HidrotérmicoDocumento23 páginasCapítulo 4: Despacho HidrotérmicoCamilo SalamancaAún no hay calificaciones
- Ejercicios Página 70Documento10 páginasEjercicios Página 70Vik Toria20% (5)
- Ejercicio de Trans. Materia en Un BiorreactorDocumento7 páginasEjercicio de Trans. Materia en Un BiorreactorJose CubasAún no hay calificaciones
- Escuela CuantitativaDocumento5 páginasEscuela CuantitativaMirian Huaman ConzaAún no hay calificaciones
- Traducción Del Manual de Catalogación de La FIAFDocumento13 páginasTraducción Del Manual de Catalogación de La FIAFAndrea RodriguezAún no hay calificaciones
- Informe Mto VehiculosDocumento2 páginasInforme Mto VehiculosDairon Alexis RodriguesAún no hay calificaciones
- Hipotesis - InicialDocumento5 páginasHipotesis - InicialfacenunaAún no hay calificaciones
- Proyecto vida dinámica elementos metasDocumento5 páginasProyecto vida dinámica elementos metasCarlos Emmanuel López RuanoAún no hay calificaciones
- SubestacionesDocumento4 páginasSubestacionesEDWIN RICARDO BARRAGAN SALAZARAún no hay calificaciones
- Ejercicios Propuestos - Fase 3 - Programación y PruebasDocumento9 páginasEjercicios Propuestos - Fase 3 - Programación y PruebasReneAún no hay calificaciones
- Final 3Documento3 páginasFinal 3Russell Bryan Salomé ArcosAún no hay calificaciones
- 9 Plan de Contingencia InformáticoDocumento21 páginas9 Plan de Contingencia InformáticoYesenia Acevedo PolackAún no hay calificaciones
- Tesis Alejandro ZylberbergDocumento105 páginasTesis Alejandro ZylberbergElisa RaúlAún no hay calificaciones
- 07-Colecta de Datos-Manual de Instrucciones Estación Total TOPCON GPT 2006Documento22 páginas07-Colecta de Datos-Manual de Instrucciones Estación Total TOPCON GPT 2006Juan PabloAún no hay calificaciones
- Formato Autorizacion Telefonica Monedero ElectronicoDocumento1 páginaFormato Autorizacion Telefonica Monedero ElectronicoJesus BriceñoAún no hay calificaciones
- Historia de La ComputaciónDocumento15 páginasHistoria de La ComputaciónMaries Rubi SAún no hay calificaciones
- TN - Eltek Flatpack v0.1 20181116Documento23 páginasTN - Eltek Flatpack v0.1 20181116Alcides QuijadaAún no hay calificaciones
- La Incorporación de La Lógica Difusa Al Modelo Black - ScholesDocumento20 páginasLa Incorporación de La Lógica Difusa Al Modelo Black - Scholesricosa00Aún no hay calificaciones
- Tutorial Mastercam X5Documento60 páginasTutorial Mastercam X5Daniel Alejandro Gomez75% (4)
- COARDocumento5 páginasCOARHeyler Martinez OrbegosoAún no hay calificaciones
- Qué Es Microsoft ExcelDocumento16 páginasQué Es Microsoft ExcelHeber ValenzuelaAún no hay calificaciones
- Magicq Manual EsDocumento97 páginasMagicq Manual EsDon Bonner100% (1)
- Fusionadora fibra ópticaDocumento15 páginasFusionadora fibra ópticaDieGoOChoaAún no hay calificaciones
- Resumen TrinomioDocumento2 páginasResumen TrinomioRuben CalderonAún no hay calificaciones
- Aliasing y Anti AliasingDocumento13 páginasAliasing y Anti AliasingAlex MonteroAún no hay calificaciones
- Guia RAP3Documento5 páginasGuia RAP3Jhon KrrÑoAún no hay calificaciones
- Tarea03 - ConceptosSistemas - MezaDíazArturoRodrigoDocumento3 páginasTarea03 - ConceptosSistemas - MezaDíazArturoRodrigobk6qcwvwrwAún no hay calificaciones
- Transformada de Fourier en Procesamiento Digital de ImágenesDocumento7 páginasTransformada de Fourier en Procesamiento Digital de ImágenesRonal David Daza DazaAún no hay calificaciones
- OML Manual de Instalación V3Documento18 páginasOML Manual de Instalación V3chernandez_243484Aún no hay calificaciones
- Rcta 13 3Documento137 páginasRcta 13 3Gilberto PerezAún no hay calificaciones