También podría gustarte
- PNODocumento3 páginasPNOofito165306Aún no hay calificaciones
- F.F. No EsterilesDocumento21 páginasF.F. No Esterilesofito165306Aún no hay calificaciones
- DERMATOLOGIA (VoBo)Documento13 páginasDERMATOLOGIA (VoBo)jcballutp100% (1)
- Cromatografia Liquida de Alta EficaciaDocumento57 páginasCromatografia Liquida de Alta EficaciaAlfredo de la CruzAún no hay calificaciones
- Instituto PolitÉcnico NacionalDocumento6 páginasInstituto PolitÉcnico Nacionalofito165306Aún no hay calificaciones
- Utilizacion de Crbohidratos y Acidos Organicos 2Documento37 páginasUtilizacion de Crbohidratos y Acidos Organicos 2ofito165306Aún no hay calificaciones
- Convocatoria SEP2011Documento10 páginasConvocatoria SEP2011ofito165306Aún no hay calificaciones
- Extracción LíquidoDocumento2 páginasExtracción Líquidoofito165306Aún no hay calificaciones
- Bioquimica MicrobianaDocumento6 páginasBioquimica Microbianaofito165306Aún no hay calificaciones
- Calculo DieteticoDocumento8 páginasCalculo Dieteticoofito165306Aún no hay calificaciones
- BPM Validacion ProcesosDocumento155 páginasBPM Validacion Procesosalex_m1000100% (4)
- Practica 1 Actividad 1 - Adriana - OrtizDocumento11 páginasPractica 1 Actividad 1 - Adriana - OrtizFernando Gasca CampilloAún no hay calificaciones
- Informe de Electroforesis Del Gel Agarosa Utilizando El Programa SnpgeneDocumento20 páginasInforme de Electroforesis Del Gel Agarosa Utilizando El Programa SnpgeneJoshy Alarcon M.100% (1)
- Practica 06 A) Regulacion Hormonal de Glicemia & B) Determinacion Del Perfil LipidicoDocumento11 páginasPractica 06 A) Regulacion Hormonal de Glicemia & B) Determinacion Del Perfil LipidicoGina MarceloAún no hay calificaciones
- Poster Deportes FuerzaDocumento4 páginasPoster Deportes FuerzaSebastian RiveraAún no hay calificaciones
- BIOMOLECULASDocumento46 páginasBIOMOLECULASLuz Marina Ccallo FloresAún no hay calificaciones
- La BibliaDocumento4 páginasLa BibliaDanelly Norell Vargas PachecoAún no hay calificaciones
- INFORME Actividad Enzimática de HidrolasasDocumento6 páginasINFORME Actividad Enzimática de HidrolasasJeaneFatAún no hay calificaciones
- Metabolismo Del Calcio y FosforoDocumento9 páginasMetabolismo Del Calcio y FosforoAnatomiaud100% (1)
- Procesos Energeticos TripticoDocumento3 páginasProcesos Energeticos Tripticolilibeth lunaAún no hay calificaciones
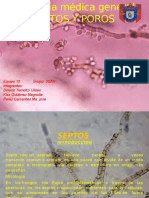
- Micología Médica GeneralDocumento9 páginasMicología Médica GeneralLiAún no hay calificaciones
- Biochemistry TestDocumento6 páginasBiochemistry TestMaJe MirEnAún no hay calificaciones
- Metodo de Formulacion Cuadrado PearsonDocumento11 páginasMetodo de Formulacion Cuadrado PearsonYul geronimo pardo berasteinAún no hay calificaciones
- CITOLOGÍADocumento15 páginasCITOLOGÍARene Andrade DelgadoAún no hay calificaciones
- Informe MitosisDocumento10 páginasInforme MitosisAidaa SerinAún no hay calificaciones
- Caso Clinico ...Documento6 páginasCaso Clinico ...Jesus GuerreroAún no hay calificaciones
- Resúmenes StryerDocumento2 páginasResúmenes StryerMaría Macías100% (1)
- Libro Fisiologia Rafael Alonso SolísDocumento134 páginasLibro Fisiologia Rafael Alonso SolísFeer IzanAún no hay calificaciones
- Factores Que Modifican El Efecto de Las Drogas 2014Documento24 páginasFactores Que Modifican El Efecto de Las Drogas 2014VanessaMargothAún no hay calificaciones
- Seminario de Mioglobina y Hemoglobina-Mesa 1 (Grupo Lunes) - FinalDocumento36 páginasSeminario de Mioglobina y Hemoglobina-Mesa 1 (Grupo Lunes) - FinalEdson Garamendez Castillo0% (2)
- Celula VegetalDocumento9 páginasCelula VegetalFernandoAún no hay calificaciones
- ENDOCRINOLOGIADocumento4 páginasENDOCRINOLOGIAJeison Brayan Carranza BecerraAún no hay calificaciones
- Afiches FrutasDocumento6 páginasAfiches FrutasSIG OBRASINAún no hay calificaciones
- Bio Qui MicaDocumento16 páginasBio Qui Micamia beyliceAún no hay calificaciones
- AminoácidosDocumento17 páginasAminoácidosSeba PeñaAún no hay calificaciones
- Metabolismo Del GlucogenoDocumento47 páginasMetabolismo Del GlucogenoBelén Chamorro SevillaAún no hay calificaciones
- Informe Practicas 1Documento6 páginasInforme Practicas 1Tatan Varela100% (1)
- Práctica de Laboratorio de Biologia Ufps #10Documento12 páginasPráctica de Laboratorio de Biologia Ufps #10YerssonCarrillo100% (1)
- MU159 20221 BioEstructural PEC4Documento11 páginasMU159 20221 BioEstructural PEC4gabiAún no hay calificaciones
- Informe Biologia Acción de Una Enzima de Tejidos Vegetales y AnimalesDocumento12 páginasInforme Biologia Acción de Una Enzima de Tejidos Vegetales y AnimalesJuan Camilo Crespo Duque100% (1)
- 1 - Casos y Controles 2012Documento102 páginas1 - Casos y Controles 2012Martin CouohAún no hay calificaciones