Documentos de Académico
Documentos de Profesional
Documentos de Cultura
Tutorial de SQL Server 2005 Express
Tutorial de SQL Server 2005 Express
Cargado por
Rafael Neftaly Becerra Zepeda0 calificaciones0% encontró este documento útil (0 votos)
13 vistas109 páginasTutorial de SQL
Derechos de autor
© © All Rights Reserved
Formatos disponibles
PDF, TXT o lea en línea desde Scribd
Compartir este documento
Compartir o incrustar documentos
¿Le pareció útil este documento?
¿Este contenido es inapropiado?
Denunciar este documentoTutorial de SQL
Copyright:
© All Rights Reserved
Formatos disponibles
Descargue como PDF, TXT o lea en línea desde Scribd
0 calificaciones0% encontró este documento útil (0 votos)
13 vistas109 páginasTutorial de SQL Server 2005 Express
Tutorial de SQL Server 2005 Express
Cargado por
Rafael Neftaly Becerra ZepedaTutorial de SQL
Copyright:
© All Rights Reserved
Formatos disponibles
Descargue como PDF, TXT o lea en línea desde Scribd
Está en la página 1de 109
1
Tutorial de SQL Server 2005 Express
En este tutorial, aprender los fundamentos para desarrollar aplicaciones con la versin Express
de SQL Server 2005. El objetivo del tutorial no es cubrir en gran detalle todos los aspectos de SQL
Server 2005 Express, pero si aportar una idea general del producto y su integracin con el resto
de herramientas Express (Visual Basic Express, Visual C# Express, y Visual J# Express
El tutorial cubrir los siguientes puntos:
Mdulo 1: Introduccin a SQL Server Express
Requisitos del sistema, instalacin del producto, y descripcin de sus componentes.
Integracin del producto con otras versiones Express; durante el tutorial se trabajar con la
versin Express de Visual Basic; sin embargo todos los ejemplos y demostraciones usados son
aplicables a Visual C#, y J#.
Proceso de despliegue de aplicaciones desarrolladas con Visual Basic Express. Conceptos
XCOPY, instancias de usuario no-administrador, y duplicacin de datos.
Proveedores de acceso a datos disponibles. A la hora de conectar a un servidor de base de
datos como SQL Server 2005 Express, el nexo de comunicacin entre el servidor y la
aplicacin cliente, es el proveedor de acceso a datos; se hablar e introducir brevemente los
proveedores de acceso a datos disponibles.
Mdulo 2: Creacin de bases de datos con Visual Studio
Objetos bsicos del sistema. Conocer aspectos de la base de datos como su creacin tipos de
datos disponibles en SQL Server 2005, crear tablas, restricciones (constraints), relaciones, y
teora relativa a la creacin de ndices, y su idoneidad.
Conocer como realizar consultas a las tablas de la base de datos, clusulas de las sentencias,
agrupaciones, joins, etc. Tambin conocer una nueva caracterstica del producto que son las
expresiones de tablas comunes (CTE). Adems aprender a hacer sentencias de insercin,
actualizacin, y borrado.
Mdulo 3: Programacin de base de datos
Procedimientos almacenados. Conocers los fundamentos para crear procedimientos
almacenados en la base de datos.
Triggers. Introduccin al uso de triggers en SQL Server 2005 Express; veremos los triggers
"tradicionales" (llamados DML, los que se activan por modificaciones de datos), y tambin
veremos los nuevos triggers que se activan por cambio en el esquema de base de datos
(DDL).
Funciones definidas de usuario. Veremos como crear UDFs, y los tipos de funciones definidas
de usuario que existen.
Mdulo 4: Conceptos avanzados
Conceptos de seguridad de objetos, esquemas, y credenciales de inicio de sesin. Se
introducir el nuevo paradigma de seguridad basado en esquemas.
2
Trasaccionalidad y niveles de aislamiento. Se cubrirn los niveles de aislamiento y cmo SQL
Server 2005 garantiza la atomicidad, consistencia, integridad, y durabilidad de las
transacciones.
Soporte Nativo XML. Conocer en qu consiste el soporte nativo de XML, uso de las columnas
tipo XML, indexacin, y consultas XQuery.
Integracin del CLR. Conocer la nueva posibilidad de crear objetos en la base de datos
usando cualquier lenguaje .NET como VB.NET, o C#.
Aunque el tutorial no est escrito para un tipo de audiencia determinada, es recomendable que el
alumno tenga conceptos de desarrollo de aplicaciones cliente-servidor, y fundamentos de bases
de datos que aunque durante el curso se irn cubriendo en mayor o menor profundidad, ayudarn
al alumno a una rpida comprensin de las lecciones.
En la introduccin del tutorial, se ver cmo instalar el producto y los diferentes proveedores de
acceso a datos que se pueden utilizar. En el segundo mdulo, se ver cmo aprovechar la
integracin entre las herramientas de desarrollo de Visual Basic Express con el motor relacional de
SQL Server 2005 Express para crear bases de datos, tablas, vistas, y otros objetos. En el tercer
mdulo, aprender conceptos bsicos sobre procedimientos almacenados, triggers, y UDFs, y para
finalizar el tutorial, aprender otros conceptos relacionados con seguridad, transacciones, y
niveles de aislamiento. A su vez, conocer nuevas funcionalidades del producto como soporte
nativo XML, y la integracin del CLR en el motor relacional de SQL Server 2005.
Recuerde que si quiere poner en prctica este curso tiene disponibles una versin sin limitaciones
de Visual Basic 2005 Express, que incluye la base de datos SQL Server 2005 Express.
Que disfrutes del curso!
Solid Quality Learning University http://www.sqlu.com
Solid Quality Learning Iberoamericana http://www.SolidQualityLearning.com
Diseado, y editado por los siguientes mentores de Solid Quality Learning:
http://www.SolidQualityLearning.com/aboutUs.aspx:
Miguel Egea (megea@sqlu.com)
MVP SQL Server
Director de Servicios Corporativos
Eladio Rincn (erincon@sqlu.com)
MVP SQL Server
Director de Tecnologas de Bases de Datos
Eugenio Serrano (eserrano@sqlu.com)
MVP ASP/ASP.NET
Antonio Soto (asoto@sqlu.com)
MCT, Director de Formacin
Agradecimientos
Queremos agradecer a Alfonso Rodrguez, David Carmona, y Lus Mazario de Microsoft Ibrica
su soporte y colaboracin durante las fases de diseo y desarrollo de este curso.
Muchas gracias!!!
3
1. Introduccin a SQL Server 2005 Express
Durante el mdulo, ver cuales los requisitos hardware/software necesarios para instalar SQL
Server 2005 Express, y cmo realizar la instalacin del producto. Se introducir al alumno
brevemente los componentes del producto, enfocado en las necesidades del desarrollador de
software. A su vez se ver cmo se integra SQL Server 2005 Express con las herramientas de
desarrollo de las ediciones Express. Para finalizar se presentarn los drivers de acceso a datos que
se usarn para conectar a SQL Server 2005 Express.
1.1. Instalacin de SQL Server 2005 Express y sus componentes
En esta leccin, conocer los requisitos para instalar SQL Server 2005 Express; adems, ver las
diferentes opciones disponibles durante la instalacin asistida. A continuacin se le introducir los
componentes instalados, explicndose su funcionalidad. Para finalizar la leccin se hablar de
otros componentes disponibles con el producto como cdigo y bases de datos de ejemplo, y
documentacin del producto (Libros en pantalla).
1.1.1. Requisitos del sistema
La instalacin del SQL Server 2005 Express tiene los siguientes requerimientos:
- Requisitos
previos de
software
- Microsoft .NET Framework
- SP1 de Microsoft Internet Explorer 6.0 o posterior
- RAM
- Mnimo: 192 MB
- Recomendado: 512 MB o ms
- Espacio en el
disco duro
- 600 MB de espacio libre
- Procesador
- Compatible con Pentium III o superior
- Mnimo: 500 MHz
- Recomendado: 1 GHz o ms
- Sistema
operativo
- Windows Server 2003 Standard Edition, Enterprise Edition,
Datacenter Edition
- Windows XP Professional, Home Edition (SP2 o posterior)
- Windows 2000 Professional, Server, Advanced Server, Datacenter
Server (SP4 o posterior)
1.1.2. Proceso de instalacin
La instalacin de SQL Server 2005 Express se puede realizar de dos formas:
1.1.2.1. Como parte de la instalacin de algn producto Express.
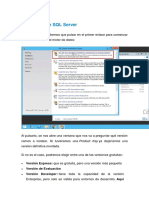
Si se instala como parte de la instalacin de algn producto Express (por ejemplo Visual
Basic Express), el proceso de instalacin le pedir si desea incluir SQL Server 2005 Express
en la instalacin: en la imagen puede ver la ventana en la que se le solicita la opcin (la
instalacin por defecto no incluye instalar SQL Server 2005 Express).
4
5
1.1.2.2. Como instalacin independiente.
Si se instala de forma independiente, el proceso de instalacin requiere los siguientes
pasos:
El primer paso de la instalacin consiste en instalar Microsoft .NET Framework 2.0 que es
uno de los requisitos de la instalacin; si ya est instalado previo al proceso de instalacin,
este paso ser omitido. La actualizacin desde versiones anteriores de .NET Framework
est soportada hasta la versin 1.1, en caso de haber instalado una versin posterior,
deber desinstalarla antes de instalar SQL Server 2005 Express; en otras palabras, la
actualizacin se puede realizar slo desde versiones soportadas de .NET Framework.
6
Ventana de condiciones de EULA; aceptar los trminos de la licencia y condiciones y pulsar
Siguiente.
7
Ventana de bienvenida de instalacin de los prerrequisitos necesarios para SQL Server
2005 Express; pulsar Instalar.
8
Ventana de finalizacin de instalacin de los prerrequisitos; pulsar Siguiente.
9
Ventana de bienvenida al asistente de instalacin de SQL Server 2005 Express; pulsar
Siguiente.
10
Ventana de comprobacin de requerimientos del sistema; si la comprobacin ha sido
satisfactoria, todas las opciones aparecern con la opcin de verificacin en color verde, en
caso de haber algn requerimiento no severo, aparecer en color amarillo; si hay algn
requerimiento crtico que no se cumple, aparecer en color rojo y no podr seguirse con el
proceso de instalacin. Pulsando en el botn Report, podr ver cuales son los requisitos no
cumplidos para poder preparar al sistema para cumplirlos; por ejemplo, si no se cumplen
los requerimientos de ASP.NET, podr salir de la instalacin, actualizar ASP.NET, y volver a
realizar la instalacin. Si la comprobacin ha sido satisfactoria, pulse Siguiente.
11
Introduzca la informacin de registro, desmarque la opcin Ocultar opciones avanzadas de
configuracin, y pulse Siguiente.
12
Seleccione los componentes que desea instalar; en ste caso, seleccione instalar todos los
componentes y pulse Siguiente.
13
Seleccione el nombre de la instancia de SQL Server 2005 Express (por defecto
SQLExpress), y pulse Siguiente.
14
Seleccione el nombre de la cuenta que arrancar el servidor de SQL Server 2005 Express
(Network Service por defecto), y habilite que el servicio de SQL Server se arranque al
finalizar la instalacin; a continuacin pulse Siguiente.
15
Seleccione el modo de autenticacin (por defecto autenticacin integrada de Windows), y
pulse Siguiente.
16
Seleccione el collation de la instancia de SQL Server. Como es una instalacin nueva, y no
se va a trabajar con bases de datos de versiones anteriores de SQL Server, se seleccionar
Latin1_General, en caso de migraciones o posibilidad de trabajar con bases de datos
importadas de SQL Server 2000 (o MSDE 2000), considere la opcin por defecto (SQL
Collations, Dictionary-order, case insensitive, for use with 1252 Character Set); a
continuacin pulse Siguiente.
17
Seleccionar la opcin de configuracin de la instancia de SQL Server sobre la posibilidad de
permitir a usuarios no-administradores de crear instancias. Por defecto habilitado; durante
las siguientes lecciones se hablar de ello, habiltelo y pulse Siguiente.
18
Opciones para informar a Microsoft sobre los errores no esperados sucedidos en la
aplicacin, y para enviar automticamente informacin sobre las caractersticas usadas del
producto; por defecto estn deshabilitadas, pero se recomienda habilitarla para mejorar el
producto enviando automticamente informacin del uso que se hace del producto; a
continuacin se pulsa en Siguiente.
19
Comienza el proceso de instalacin informando de las caractersticas que se van instalando.
20
Finalizacin del proceso de instalacin con estado de casa funcionalidad instalada; en caso
de haber algn error durante la instalacin, aparecern botones en color Rojo indicando el
error; pulsando en la casilla correspondiente de la columna Status, podr ver informacin
del error producido; pulse Siguiente.
21
Informe final de la instalacin de SQL Server en el que se podr ver todas las
caractersticas instaladas, y un fichero de resumen con cada paso realizado durante la
instalacin. Pulse Finalizar, y ya est preparado para poder utilizar SQL Server 2005
Express.
22
1.1.3. Componentes instalados
Para acceder a los componentes instalados en SQL Server 2005 Express, deber hacer click en
Inicio, Todos los Programas, Microsoft SQL Server 2005, Herramientas de
configuracin como ve en la siguiente imagen:
23
Las opciones disponibles son las siguientes:
1.1.3.1. Administrador de configuracin
Componente basado en Microsoft Management Console (MMC), con el que se puede
administrar la configuracin de los servicios SQL Server, protocolos de red utilizados, y
configurar el cliente nativo de acceso a SQL Server. Es una herramienta que realiza todas
las modificaciones haciendo uso de las nuevas APIs de administracin SMO (sustituto de
SQL-DMO). El hecho de usar tales APIs nos da la posibilidad de poder crear aplicaciones
personalizadas para configurar el servidor; por ejemplo, se podra crear una aplicacin
basada en SMO que implemente o extienda las funcionalidades expuestas a travs de la
aplicacin MMC. La aplicacin tiene la siguiente apariencia:
24
Al igual que desde el administrador de servicios del sistema operativo, se pueden cambiar
las propiedades del servicio; la gran diferencia, es que mientras las llamadas de la
aplicacin MMC de los servicios realiza llamadas a las APIs del Kernel de Windows, el
Administrador de Configuracin, realiza las llamadas a travs de las APIs de SMO.
25
Se pueden configurar, habilitar o deshabilitar protocolos; configurar, o modificar puertos
TCP/IP como se ve en la imagen:
26
As como establecer el orden de los protocolos de Red; en el siguiente ejemplo, estn
habilitados los protocolos Shared Memory, TCP/IP, y Named Pipes, mientras que el
protocolo VIA est deshabilitado:
Nota: Recuerde que la mayora de estos cambios no tendrn efecto hasta que el servicio
de SQL Server haya sido reiniciado.
27
1.1.3.2. Informes de uso y errores de SQL Server
La utilidad permite modificar las opciones de configuracin relativas al feedback que se
enva a Microsoft en cuanto al uso de las caractersticas del producto, e informe de errores
no esperados. El nivel de detalle llega hasta el nivel de instancia, es decir, podemos decidir
qu instancias envan informacin sobre los errores no esperados, o sobre el uso de las
funcionalidades del producto:
28
1.1.3.3. Configuracin de superficie de SQL Server
El aplicativo configuracin de superficie de SQL Server es un asistente que ayuda a
configurar cuales son las partes de SQL Server que se encuentran expuestas a
interactuacin desde el exterior. La filosofa del aplicativo es ayudar a configurar de manera
sencilla y rpida los puntos de acceso al servidor. El aplicativo expone al usuario
funcionalidades tales como configuracin de servicios, y configuracin de caractersticas de
SQL Server; por ejemplo, CLR habilitado o no, soporte HTTP habilitado o no, endpoints
configurados en el servidor, etc.
29
El aplicativo permite modificar la configuracin del servicio de SQL Server.
30
Tambin permite configurar el tipo de conexiones permitida sobre el servidor. Por ejemplo,
SQL Server 2005 Express permite por defecto slo conexiones locales; esto quiere decir
que no se pueden realizar conexiones desde equipos externos a menos que se configure de
servidor para permitirlo. Desde la aplicacin, se podr habilitar la posibilidad de conexiones
de equipos remotos, y los protocolos de conexin permitidos.
En cuanto a las opciones de configuracin de funcionalidades del motor de base de datos,
se incluyen:
Posibilidad de habilitar o deshabilitar la ejecucin de consultas con OPENROWSET y
OPENDATASOURCE: lo que estas funciones permiten es realizar consultas a servidores
remotos (servidores expuestos a travs de un origen de datos del que se provea drivers
de acceso como ODBC, OLEDB, etc.) sin la necesidad de tener que crear un servidor
vinculado.
Habilitar el soporte del CLR: creacin de objetos de base de datos con cualquier
lenguaje .NET Framework.
Habilitar el soporte nativo de Servicios Web: opcin slo disponible en la versin
Enterprise de SQL Server 2005 que permite exponer SQL Server 2005 sin necesidad de
implementar Servicios Web expuestos por IIS.
Habilitar el uso de Automatizacin OLE con sentencias T-SQL: posibilidad de realizar
llamadas a objetos COM desde Transact-SQL con los procedimientos almacenados de
31
sistema sp_OACreate, sp_OAGetProperty, sp_OASetProperty, sp_OAMethod,
sp_OAStop, y sp_OADestroy. Automatizacin OLE entrar en desuso debido a la
integracin del CLR y su consiguiente facilidad para implementarlo mediante .NET
Framework en lugar de objetos COM.
Habilitar el uso del procedimiento almacenado de sistema xp_cmdshell que permite
ejecutar comandos de sistema en el servidor (tales como DIR, DELETE, COPY, etc.)
Habilitar el uso de endpoints de Service Broker.
1.1.3.4. SQLCMD
SQL Server 2005 Express no incluye la herramienta SQL Server Management Studio como
el resto de versiones de SQL Server 2005. Para poder conectarse a SQL Server, el producto
incluye una utilidad de lnea de comando que permite conectarse a una instancia de SQL
Server y realizar operaciones de manera similar a las herramientas grficas.
Evidentemente, la funcionalidad que nos proveen Management Studio no puede ser
alcanzada con la utilidad de lnea de comando, pero si provee lo necesario para conectarse
e interactuar con la instancia. Tpicamente esta utilidad suele ser utilizada para realizar
tareas administrativas bsicas. Por ejemplo, un ISV que desarrolla una aplicacin y
necesita ejecutar un script contra la instancia de SQL Server; imagnese que el ISV no ha
desarrollado sus propias herramientas para ejecutar consultas ad-hoc contra el servidor; en
este caso, puede utilizar SQLCMD para conectarse a la instancia de SQL Server y ejecutar
el script deseado. Incluso, el ISV tiene la posibilidad de crear el script con SQL Server
32
Management Studio en sus equipos de desarrollo porque Management Studio incorpora la
posibilidad de ejecutar scripts en modo SQLCMD.
La documentacin del SQLCMD la puede encontrar en los Libros en Pantalla en "SQL Server
2005 Express Edition", "Working with SQL Server Express", "Using the sqlcmd Utility (SQL
Server Express)".
La funcionalidad ms novedosa implementada en SQLCMD es la posibilidad de utilizar
variables a la hora de ejecutar scripts; por ejemplo:
Dado el siguiente script llamado copia.sql:
BACKUP DATABASE $(db) TO DISK = "$(path)\$(db).bak" WITH INIT
donde $(db) es una variable que referenciar a un nombre de base de datos, y $(path) la
ruta donde se guardar la copia.
Si se ejecuta desde lnea de comando
SQLCMD -ic:\copia.sql -vdb="AdventureWorks" path="c:\data"
lo que SQLCMD ejecutar ser:
BACKUP DATABASE AdventureWorks TO DISK = "c:\data\AdventureWorks.bak"
WITH INIT
lo cual quera decir que con un script de copia de seguridad, se podran reutilizar con
bastante facilidad distintas estrategias de copia de seguridad. Esto est muy bien, pero se
limita la capacidad a la instancia en uso. Sin embargo, SQLCMD tambin permite cambiar
de conexin tras haber conectado a un servidor con la palabra clave :connect; por ejemplo:
desde lnea de comando, se conecta a una instancia de la siguiente manera:
SQLCMD -E -S(local)\SQLEXPRESS
A continuacin aparece el prompt, y puede ejecutar lo siguiente:
:connect (local)\SQLEXPRESS_2
que conectara a una segunda instancia de SQL Server 2005. Otras opciones disponibles
son :r para ejecutar un script, y :setvar para definir variables, por lo que el ejemplo
anterior del backup se podra ejecutar de la siguiente forma:
SQLCMD -E -S(local)\SQLEXPRESS
:setvar db AdventureWorks
:setvar path c:\data
:r c:\copia.sql
GO
1.1.4. Componentes opcionales
Las bases de datos de ejemplo y el cdigo de ejemplo son un buen comienzo para conocer las
nuevas funcionalidades del producto. La base de datos AdventureWorks se ha creado para
sustituir a las anteriores Northwind, y Pubs que pecaban de ser bases de datos poco reales en
cuanto a volumen de datos. Se ha tenido ms cuidado en el diseo relacional de la base de
datos AdventureWorks, y se ha aprovechado para incluir nuevas funcionalidades como soporte
XML, novedades Transact-SQL, nuevos tipos de datos, etc.
La otra fuente de conocimiento a mencionar son los Libros en Pantalla (BOL): la versin
incluida en SQL Server 2005 Express es una versin "reducida" de la versin completa, pero
en todo momento, da acceso a la Web de Microsoft para acceder a documentacin y ayuda
incluida en la versin completa de los Libros en Pantalla. A su vez, los Libros en Pantalla,
incluyen la posibilidad de acceder directamente a los grupos de noticias para obtener
33
respuesta a casos concretos, y tambin realizar bsquedas en sitios de la comunidad como
CodeZone, ElGuille.info, GotDotNet.com, SSUG.com, SQLIS.com, etc.
1.2. Integracin con versiones Express
En esta leccin, conocer cmo se integran la versin Express de SQL Server con Visual Studio, y
cmo ayuda la versin Express de SQL Server en el proceso de despliegue de aplicaciones de
bases de datos. Se le introducir a nuevos conceptos como instancias de nombre para no-
administradores, y se le ensear a desplegar aplicaciones de bases de datos con la versin
Express de SQL Server 2005.
Uno de los objetivos de la versin Express de SQL Server 2005, es simplificar el proceso de
despliegue de aplicaciones de bases de datos; a diferencia del resto de versiones de SQL Server
(Workgroup, Standard, Enterprise) en el que las bases de datos se cambian de lugar poco o casi
nunca, la versin Express est pensada para aplicaciones de bases de datos que requieren en
cierto modo que los ficheros de base de datos sean dinmicos. Esta movilidad de los ficheros se
consigue durante la fase de despliegue.
En qu ayuda al despliegue la versin Express? Los Vendedores de Software Independientes
(ISVs) generalmente desarrollan aplicaciones comerciales que requieren de un instalable, y a su
vez requieren instalar una base de datos; La versin Express viene a solucionar los problemas que
surgan en el proceso de instalacin en este tipo de aplicaciones.
1.2.1. Compatibilidad con versiones "mayores" de SQL Server
La versin Express de SQL Server se pone en la lnea de las versiones MSDE de anteriores
versiones de SQL Server; esto quiere decir que una base de datos de SQL Server 2005 para la
versin Express, es totalmente compatible con el resto de versiones de SQL Server
(Workgroup, Standard, Enterprise). El proceso de migracin entre versiones es tan sencillo
como hacer una restauracin de la copia de seguridad de la base de datos (comando
RESTORE, o usando las herramientas grficas), o usando la opcin de adjuntar bases de datos
(comando sp_attach_db, o con las herramientas grficas).
1.2.2. Instancias de nombre para usuarios no-administradores
Uno de los problemas que tienen los ISVs que distribuyen aplicaciones con MSDE es que el
usuario que realiza la instalacin de la aplicacin debe pertenecer al rol de administradores de
SQL Server. Este es un requisito que en la versin Express de SQL Server 2005 se elimina con
la aparicin de las instancias de usuario.
El objetivo de las instancias de usuario, es acercar a SQL Server al concepto de base de datos
de escritorio; es una base de datos que slo admite conexiones locales a travs del protocolo
de red "named pipes", no se pueden realizar conexiones a travs de la red. El concepto de las
instancias de usuario es similar al modelo de las bases de datos Access: una vez conectado al
fichero de base de datos, el usuario tiene derechos administrativos sobre la base de datos, sin
necesidad de la intervencin de un usuario administrador.
1.2.2.1. Cmo funciona?
En primer lugar, para habilitar el uso de instancias de usuario, en la cadena de conexin de
la aplicacin cliente debers aadir la cadena "User Instance=true". De esta forma se
indica a SQL Server Express, que la conexin se realizar sobre una instancia de usuario.
En caso de que no existiera la instancia de usuario, SQL Server automticamente, crear la
instancia de usuario; consiste en crear una nueva instancia de SQL Server para el usuario
requerido, en el que:
Se copiarn las bases de datos de sistema de la instancia por defecto de SQL Server
2005 Express, y
34
Se iniciar otra "copia" del servicio de SQL Server Express; el nombre de la instancia es
un valor aleatorio, por ejemplo (2E67C75A-1693-4D), y se debe considerar a la nueva
instancia hija de la instancia principal de SQL Server Express.
Nota: Conectndose a la instancia \SQLEXPRESS, con la vista sys.dm_os_child_instances
se pueden consultar cuales son las instancias de usuario activas.
La diferencia fundamental con las instancias tradicionales es que a la instancia de
usuario solamente puede conectar el usuario para el que se ha creado la instancia.
Adems, por diseo, slo se puede conectar mediante canalizacin por nombres, y no se
puede conectar a la instancia de forma remota.
Despus de crear o iniciar la instancia de SQL Server Express, automticamente, el proceso
de conexin se encargar de adjuntar la base de datos que se ha especificado en la cadena
de conexin a la instancia recin creada.
A su vez, cuando la aplicacin cliente cierra conexin con la base de datos, la base de datos
se "desadjunta" de la instancia de SQL Server. En realidad, SQL Server tiene configurado
un tiempo de espera antes de desadjuntar la base de datos de la instancia porque en caso
contrario, el proceso de adjuntar/ desadjuntar podra causar problemas de rendimiento en
la aplicacin.
Un ejemplo de cadena de conexin que deber usarse para trabajar con instancias de
usuario podra ser el siguiente:
conn string =
"Data Source=.\\SQLExpress;" +
"Integrated Security=true;" +
"attachdbfilename=|DataDirectory|\\mi_bd.mdf;" +
"User Instance=true;"
En .NET 2.0, aparece la palabra clave |DataDirectory|, que representa un path relativo a
la instalacin de la aplicacin; por ejemplo, distribuimos una aplicacin que admite
personalizar la ruta de instalacin, con |DataDirectory| podemos especificar rutas relativas.
A su vez, tambin se puede especificar el valor de DataDirectory de la siguiente manera:
AppDomain.CurrentDomain.setData(DataDirectory,C:\ruta_por_defecto\);
1.2.3. Consideraciones
Como la instancia de usuario es hija de la instancia SQLEXPRESS, si la instancia
SQLEXPRESS no est arrancada, la instancia de usuario no arrancar.
Un usuario slo puede tener una instancia de usuario.
Las bases de datos de la instancia de usuario se crean en la ruta: \Documents and
Settings\nombre_usuario\Local Settings\Application Data\Microsoft\Microsoft SQL
Server Data\SQLEXPRESS
La rplica se deshabilita.
La instancia de usuario no admite Autenticacin de SQL Server. Slo se admite la
Autenticacin de Windows.
La compatibilidad de protocolo de red con las instancias de usuario slo es posible
mediante canalizaciones con nombre locales.
La instancia de usuario comparte las entradas de registro de la instancia primaria.
No se admiten instancias de usuario con cdigo nativo. Esta caracterstica slo se
admite con ADO .NET.
35
1.2.4. Despliegue de la aplicacin
El objetivo principal de las instancias de usuario, es disponer de un fichero de base de datos,
que se utiliza en una instancia cuando el usuario necesita acceder a la base de datos. Cuando
no se est usando, la base de datos se desadjunta. Qu se consigue con esto? Acercar la base
de datos al concepto de base de datos de escritorio (como si fuera Access). De esta forma, el
despliegue de la aplicacin relacionada con la base de datos consistir en:
Copiar los binarios de la aplicacin.
Copiar el fichero de base de datos.
Nota. Fjate que slo hay que copiar el fichero de base de datos; no se necesita adjuntar la
base de datos a ninguna instancia de SQL Server, porque la propia aplicacin se encarga de
hacerlo por nosotros.
Por lo tanto, para desplegar la aplicacin deberemos incluir en la distribucin la copia de la
base de datos de la aplicacin. Para ello lo podremos hacer de dos formas:
Usar el concepto de XCOPY copiando el contenido del directorio \bin\release de la
aplicacin generada en el directorio destino.
Usar la nueva tecnologa ClickOnce, cuyo objetivo es facilitar el despliegue de la aplicacin,
y a su vez, gestionar las actualizaciones; en el proceso de instalacin, adems de la
realizar la propia instalacin, se podr configurar la aplicacin para actualizar
automticamente la aplicacin cuando existan nuevas versiones.
1.3. Acceso a datos
Sin lugar a dudas uno de los mbitos ms importantes de un lenguaje o entorno de programacin
es su capacidad de acceso a datos. Prcticamente todas las aplicaciones conllevan la realizacin
de accesos a datos.
Le gustar saber que la plataforma .NET, y por lo tanto ASP.NET, ofrecen un potente modelo de
acceso a fuentes de datos. Se le conoce con el nombre genrico de ADO.NET.
Nota: No se deje engaar por el nombre: ADO.NET no tiene casi nada que ver con el anterior
ADO utilizado en los tiempos de ActiveX y COM. S, dispone de conexiones, comandos e incluso
una clase que recuerda a los Recordset, pero crame cuando le digo que es mejor que se olvide
para siempre de todos ellos. Tanto la filosofa de trabajo como la tecnologa son diferentes por
completo y es mejor que utilice una estrategia de "ojos limpios" para acercarse correctamente a la
nueva tecnologa.
Los conocimientos adquiridos en este mdulo le servirn para cualquier tipo de desarrollo con
.NET, no slo para aplicaciones Web. Los conceptos explicados son vlidos tambin para cualquier
versin de .NET no slo para la 2.0.
1.3.1. Introduccin a ADO.NET
Como cualquier otro modelo de acceso a datos, ADO.NET es un conjunto de clases
relacionadas entre s que estn especializadas en ofrecer toda la funcionalidad que un
programador necesita para realizar acceso a datos y manejarlos una vez los ha obtenido.
Las clases genricas expuestas por ADO.NET se encuentran bajo el espacio de nombres
System.Data. Este espacio de nombres define clases genricas de acceso a datos que
posteriormente son extendidas para ofrecer caractersticas y funciones especficas de cada
proveedor.
El objeto ms importante a la hora de trabajar con el nuevo modelo de acceso a datos es el
DataSet. Sin exagerar demasiado podramos calificarlo casi como un motor de datos
36
relacionales en memoria. Aunque hay quien lo asimila a los clsicos Recordsets su
funcionalidad va mucho ms all como se ver en breve.
1.3.1.1. Arquitectura de ADO.NET
El concepto ms importante que hay que tener claro sobre ADO.NET es su modo de
funcionar, que se revela claramente al analizar su arquitectura:
Figura 4.1.- Arquitectura de ADO.NET
Existen dos capas fundamentales dentro de su arquitectura: la capa conectada y la
desconectada
1.3.1.2. La capa conectada
La capa conectada de ADO.NET contiene objetos especializados en la conexin con los
orgenes de datos. As, la clase genrica Connection se utiliza para establecer conexiones
a los orgenes de datos. La clase Command se encarga de enviar comandos de toda ndole
al origen de datos. Por fin la clase DataReader est especializada en leer los resultados de
los comandos.
La clase DataAdapter hace uso de las tres anteriores para actuar de puente entre la capa
conectada y la desconectada como veremos despus.
Estas clases son abstractas, es decir, no tienen una implementacin real de la que se
pueda hacer uso directamente. Es en este punto en donde entran en juego los
proveedores de datos. Cada origen de datos tiene un modo especial de comunicarse con
los programas que los utilizan, adems de otras particularidades que se deben contemplar.
Un proveedor de datos de ADO.NET es una implementacin concreta de las clases
conectadas abstractas que hemos visto, que hereda de stas y que tiene en cuenta ya
todas las particularidades del origen de datos en cuestin.
As, por ejemplo, las clases especficas para acceder a SQL Server se llaman
SqlConnection, SqlCommand, SqlDataReader y SqlDataAdapter y se encuentran bajo
el espacio de nombres System.Data.SqlClient. Es decir, al contrario que en ADO clsico
no hay una nica clase Connection o Command que se use en cada caso, si no que existen
37
clases especializadas para conectarse y recuperar informacin de cada tipo de origen de
datos.
Nota: El hecho de utilizar clases concretas para acceso a las fuentes de datos no significa
que no sea posible escribir cdigo independiente del origen de datos. Todo lo contrario. La
plataforma .NET ofrece facilidades de escritura de cdigo genrico basadas en el uso de
herencia e implementacin de interfaces. De hecho la versin 2.0 de .NET ofrece grandes
novedades especficamente en este mbito.
Existen proveedores nativos, que son los que se comunican directamente con el origen
de datos (por ejemplo el de SQL Server o el de Oracle), y proveedores "puente", que se
utilizan para acceder a travs de ODBC u OLEDB cuando no existe un proveedor nativo
para un determinado origen de datos.
Nota: Estos proveedores puente, si bien muy tiles en determinadas circunstancias,
ofrecen un rendimiento menor debido a la capa intermedia que estn utilizando (ODBC u
OLEDB). Un programador novel puede sentir la tentacin de utilizar siempre el proveedor
puente para OLEDB y as escribir cdigo compatible con diversos gestores de datos de
forma muy sencilla. Se trata de un error y siempre que sea posible es mejor utilizar un
proveedor nativo.
La plataforma .NET proporciona "de serie" los siguientes proveedores de acceso a datos.
Proveedor Espacio de nombres Descripcin
ODBC .NET Data
Provider
System.Data.Odbc
Permite conectar nuestras
aplicaciones a fuentes de datos a
travs de ODBC.
OLE DB .NET Data
Provider
System.Data.OleDb
Realiza la conexin utilizando un
proveedor OLEDB, al igual que el
ADO clsico.
Oracle Client .NET
Data Provider
System.Data.OracleClient
Proveedor de datos para acceder a
Oracle.
SQL Server .NET
Data Provider
System.Data.SqlClient
Permite la conexin optimizada a
SQL Server 7.0 o posterior,
incluyenbdo la ltima versin SQL
Server 2005.
Los proveedores de acceso a datos que distribuye Microsoft en ADO.NET y algunos
desarrollados por otras empresas o terceros, contienen los mismos objetos, aunque los
nombres de stos, sus propiedades y mtodos, pueden ser diferentes.
Existen, por supuesto, proveedores para tipos de orgenes de datos de cualquier gestor de
datos existente en el mercado. stos los desarrolla normalmente la empresa responsable
del producto. Si bien stos optimizan el acceso a estos orgenes de datos nosotros siempre
podremos realizarlo mediante ODBC u OLEDB si tenemos necesidad.
En resumen: con la capa conectada de ADO.NET realizamos la conexin y comunicacin
con los orgenes de datos. Cada proveedor de datos implementa su propia versin de las
clases Connection, Command, DataReader y DataAdapter (entre otras).
Las clases derivadas de Connection se utilizan para realizar la conexin y enviar y
recibir informacin.
Las clases derivadas de Command permiten ejecutar sentencias SQL y procedimientos
almacenados en el gestor de datos.
38
Las clases derivadas de DataReader se emplean para obtener los posibles resultados de
un comando utilizando para ello el conducto de comunicacin establecido por
Connection.
1.3.1.3. La capa desconectada
Una vez que ya se han recuperado los datos desde un origen de datos la conexin a ste ya
no es necesaria. Sin embargo sigue siendo necesario trabajar con los datos obtenidos de
una manera flexible. Es aqu cuando la capa de datos desconectada entra en juego.
Adems, en muchas ocasiones es necesario tratar con datos que no han sido obtenidos
desde un origen de datos relacional con el que se requiera una conexin. A veces
nicamente necesitamos un almacn de datos temporal pero que ofrezca caractersticas
avanzadas de gestin y acceso a la informacin.
Por otra parte las conexiones con las bases de datos son uno de los recursos ms escasos
con los que contamos al desarrollar. Su mala utilizacin es la causa ms frecuente de
cuellos de botella en las aplicaciones y de que stas no escalen como es debido. Esta
afirmacin es especialmente importante en las aplicaciones Web en las que se pueden
recibir muchas solicitudes simultneas de cualquier parte del mundo.
Finalmente otro motivo por el que es importante el uso de los datos desconectado de su
origen es la transferencia de informacin entre capas de una aplicacin. stas
pueden encontrarse distribuidas por diferentes equipos, e incluso en diferentes lugares del
mundo gracias a Internet. Por ello es necesario disponer de algn modo genrico y
eficiente de poder transportar los datos entre diferentes lugares, utilizarlos en cualquiera
de ellos y posteriormente tener la capacidad de conciliar los cambios realizados sobre ellos
con el origen de datos del que proceden. Todo esto y mucho ms es lo que nos otorga el
uso de los objetos DataSet, ncleo central de la capa desconectada de ADO.NET.
Nota: Otra interesante caracterstica de los DataSet es que permiten gestionar
simultneamente diversas tablas (relaciones) de datos, cada una de un origen diferente si
es necesario, teniendo en cuenta las restricciones y las relaciones existentes entre ellas.
Los DataSet, como cualquier otra clase no sellada de .NET, se pueden extender mediante
herencia. Ello facilita una tcnica avanzada que consiste en crear tipos nuevos de DataSet
especializados en la gestin de una informacin concreta (por ejemplo un conjunto de
tablas relacionadas). Estas nuevas tipos clases se denominan genricamente DataSet
Tipados, y permiten el acceso mucho ms cmodo a los datos que representan,
verificando reglas de negocio, y validaciones de tipos de datos ms estrictas.
Los objetos DataSet no dependen de proveedor de datos alguno y su funcionamiento es
independiente de cmo hayan sido obtenidos los datos que contienen. Este es el concepto
ms importante que debemos recordar.
El proceso general de trabajo de ADO.NET para acceder a un gestor de datos (SQL Server,
por ejemplo) es casi siempre el mismo: se abre una conexin (clase Connection), se lanza
una consulta SQL o procedimiento almacenado mediante un objeto de la clase Command, y
se almacenan en memoria los resultados dentro de un objeto DataSet, cerrando la
conexin.
Nota: Aunque este es el comportamiento habitual de una aplicacin de datos existen casos
en los que no es recomendable almacenar en memoria (en un DataSet) todos los
resultados de una consulta, bien por ser muchos registros o por contener datos muy
grandes. En este tipo de casos se puede usar u objeto DataReader directamente para leer
la informacin, tratarla y no almacenarla en lugar alguno. De todos modos lo ms frecuente
es realizar el proceso descrito.
39
1.3.1.3.1. Unin entre capa conectada y desconectada
La clase DataAdapter se ha incluido anteriormente en la capa conectada por que est
implementada por cada proveedor de un modo diferente. En realidad es una clase que
pone sus pies en ambos mundos (conectado y sin conexin) y sirve de nexo entre ellos.
Un DataAdapter sabe como manejar correctamente los objetos proporcionados por su
proveedor especfico (fundamentalmente los vistos: Connection, Command y
DataReader) y proporciona mtodos para trasegar informacin desde el servidor a
DataSets desconectados y viceversa haciendo uso de dichos objetos especficos del
proveedor.
As, por ejemplo, el mtodo Fill de un DataSet se utiliza para introducir los resultados
de una consulta dentro de un DataSet para luego trabajar con ellos sin preocuparnos de
su origen. Del mismo modo su mtodo Update se utiliza para conciliar
automticamente con el origen de datos los datos modificados en un DataSet mientras
no haba conexin.
1.3.1.3.2. Otras clases dependientes de DataSet
Como hemos dicho antes un DataSet podra asimilarse a un pequeo gestor de datos en
memoria. Como tal un DataSet permite mantener diversas tablas as como las
relaciones entre ellas, incluso forzando que se cumplan restricciones de creacin y
actualizacin, como en una base de datos "real". Para ello se apoya en el uso de otras
clases especializadas que son las siguientes:
DataTable: representa una tabla o relacin de datos. Se puede asimilar a una tabla
de un gestor de datos. Los datos obtenidos de una consulta de tipo SELECT de SQL
se almacenan en un objeto de esta clase.
DataColumn: ofrece informacin sobre cada uno de los campos de los registros
almacenados en un DataTable, como su nombre o su tipo.
DataRow: representa un registro de la tabla virtual definida por el DataTable.
Contiene tantos elementos como campos tiene la tabla, cada uno del tipo definido
por el objeto DataColumn correspondiente.
Constraint: las clases Constraint se emplean para definir restricciones en los tipos
de datos contenidos en un DataTable. Por ejemplo se puede usar un objeto de esta
clase para indicar que un determinado campo debe ser nico o que se trata de una
clave externa que debe ser tenida en cuenta en actualizaciones o borrados en
cascada.
DataRelations: define la relacin existente entre dos objetos DataTable.
Normalmente se suelen utilizar un identificador comn a ambas tablas aunque
pueden ser combinaciones de ms de uno de ellos. De este modo se sabe cmo
obtener informacin de una tabla a partir de informacin en otra. Por ejemplo el
identificador de una factura (su nmero, por ejemplo) puede servir para relacionar
su registro con los registros de detalle de factura que estn contenidos en otra tabla.
DataView: representa una vista concreta de un DataTable. Normalmente se trata
de ordenaciones o filtros sobre los datos originales. Todas las tablas disponen de
una vista por defecto (propiedad DefaultView) que ofrece los datos tal y como se
han introducido en sta y es la vista que se usa habitualmente.
1.3.1.4. Vinculacin de datos a controles Web
Otra caracterstica fundamental de ASP.NET que lo convierte en una herramienta ventajosa
para el desarrollo de aplicaciones Web es la capacidad de vincular datos a controles Web.
40
La mayor parte de los controles que podemos arrastrar sobre una pgina ASPX se pueden
vincular a los objetos DataSet, DataTable y DataReader o a informaciones concretas
contenidas en stos.
Ello facilita mucho el trabajo con datos desde la interfaz de usuario ya que no hay que
molestarse en generar tablas con ellos, escribir JavaScript o proporcionar complejos medios
propios para permitir su edicin o navegacin si hacemos un uso adecuado de la
vinculacin y los controles disponibles.
Todo ello, gracias a ASP.NET y Visual Studio, equipara en muchos aspectos el desarrollo
Web al clsico desarrollo de aplicaciones de escritorio donde este tipo de facilidades han
estado disponibles desde hace aos. Sin embargo en una aplicacin Web donde no existe
una conexin permanente disponible entre la visualizacin (navegador) y el lugar en el que
se ejecuta el cdigo no es algo fcil de conseguir. El uso de un modelo consistente como
ADO.NET (idntico en Web, escritorio y otros entornos) junto con las capacidades nativas
de ASP.NET para abstraernos de estas dificultades (ViewState, Postback...) consiguen el
"milagro".
En este mdulo veremos tambin lo sencillo que resulta crear interfaces para explotar los
datos desde una pgina Web.
1.3.2. Acceso a datos manual
Tras haber aprendido un poco de teora sobre ADO.NET a continuacin explicaremos cmo se
utilizan las clases de acceso datos para escribir cdigo de acceso a datos de manera manual.
Si bien es un tema algo rido y adems en un gran porcentaje de los casos utilizaremos
herramientas que nos faciliten la creacin automtica de cdigo, es fundamental conocer la
forma de trabajar sin ayuda para entender el funcionamiento real de los objetos de datos.
1.3.2.1. Escritura manual de cdigo
En este apartado vamos a analizar cmo es el cdigo necesario para recuperar y actualizar
datos con ADO.NET. Posteriormente veremos como sacar partido a las facilidades del
entorno de desarrollo Visual Studio 2005 para no tener que escribir el cdigo a mano. Sin
embargo es til aprender a hacerlo de esta manera para entender bien su funcionamiento.
1.3.2.1.1. Comandos de seleccin simples
La mayor parte de las consultas que se lanzan contra una base de datos suelen
utilizarse para obtener un conjunto de registros para tratar. Este tipo de consultas
suelen ser expresiones SQL de tipo SELECT. El siguiente fragmento de cdigo muestra
los pasos necesarios para mostrar en una pgina los registros resultantes de una
consulta:
41
No se trata de un cdigo optimizado (es ms bien burdo) pero nos ayudar a entender
perfectamente el proceso. Los datos los obtendremos de la conocida base de datos de
ejemplo Northwind (que viene con todas las versiones de SQL Server).
Nota: Para poder escribir cdigo de acceso a datos en nuestro mdulo debemos
agregar referencias a los espacios de nombres que contienen las clases que vamos a
utilizar. Para ello usamos las dos sentencias Imports siguientes:
La primera de ellas agrega las clases genricas de acceso a datos (como DataSet) y la
siguiente las especficas de SQL Server. Si no lo hacemos recibiremos un error.
Lo primero que se debe hacer es instanciar un objeto que represente la conexin a la
base de datos. Dado que nos estamos conectando a SQL Server esta conexin ser del
tipo SqlConnection. Es lo que se hace en la primera lnea del cdigo anterior. La
conexin debe realizarse con un servidor de datos y un esquema de datos concreto.
Esto se indica mediante la cadena de conexin (al igual que se haca en ADO
tradicional). En este caso la cadena de conexin es la tpica de SQL Server. Cada gestor
de datos tiene la suya y hay que construirla de manera adecuada. El entorno de
desarrollo Visual Studio 2005 nos ayuda a crearlas como veremos luego.
Una vez creado el objeto con el que nos conectaremos hay que definir el comando a
lanzar a la base de datos. Para ello se utiliza un objeto SqlCommand. Las propiedades
bsicas que hay que establecer para ste son la consulta que se lanzar (propiedad
CommandText) y la conexin que se emplear para lanzarla (propiedad Connection)
que es lo que se refleja en las lneas 6 y 7.
Ahora que ya sabemos cmo nos conectaremos y qu queremos obtener debemos
lanzar la consulta y recoger el resultado de alguna manera.
La clase Command dispone de diversos mtodos para ejecutar consultas:
ExecuteReader: este mtodo lanza la consulta a la base de datos y devuelve una
referencia a una instancia de la clase DataReader (SqlDataReader en el caso de SQL
Server). Podemos utilizar el DataReader para recorrer los datos y procesarlos.
42
ExecuteNonQuery: ejecuta la consulta sin devolver resultado alguno. Simplemente
enva la consulta al servidor y devuelve el nmero de registros afectados por sta.
til para realizar consultas de insercin (INSERT), actualizacin (UPDATE) y borrado
(DELETE).
ExecuteScalar: lanza la consulta y devuelve un objeto con el valor del primer
campo del primer registro que se obtenga de dicha consulta. Es til para lanzar
consultas de agregacin como sumas (SUM), cuentas (SELECT COUNT * ....) y
similares de las que slo necesitamos un valor como resultado.
En el ejemplo hemos utilizado el primer mtodo ya que requerimos que devuelva varios
registros con diferentes campos. Entonces lo que hacemos es (lneas a partir de la 9):
1. Abrir la conexin.
2. Crear una variable para contener una referencia a un objeto de la clase DataReader
que es el que nos permitir acceder a los resultados. Fjese en que no se puede
instanciar un DataReader (la declaracin no lleva la palabra clave New).
3. Se obtiene el resultado mediante el mtodo ExecuteReader, recogindolo en la
variable (dr) recin declarada.
4. Se procesan los resultados (lneas 14-18).
5. Se cierra la conexin.
El objeto DataReader es asimilable a un cursor de servidor de slo lectura y hacia
adelante (conocidos como de manguera de bombero o firehose). Es decir, los datos
devueltos por el DataReader slo se pueden leer y no actualizar. Adems de esto slo
se pueden leer en secuencia hacia adelante (no hay forma de regresar sobre lo
andado).
La propiedad HasRows nos indica si hay o no resultados devueltos. El mtodo Read
avanza una posicin en los registros devolviendo True si quedan registros pendientes de
leer. Con esta informacin es muy fcil entender las lneas 14 a 18.
1.3.2.1.2. La clusula Using
Qu ocurre si se produce un error durante el procesamiento del bucle anterior en el
que se trata el DataReader? La respuesta es que la conexin, que debemos tener
abierta durante el procesamiento, no se cerrar pues el cdigo no llega al final.
Esto es algo muy grave ya que las conexiones que no se cierran no se pueden reutilizar
y por lo tanto puede llegar un momento en que no tengamos conexiones disponibles, lo
que limita enormemente la escalabilidad del sistema.
Podemos evitar el problema escribiendo:
43
De este modo, con la clusula Finally nos aseguramos que siempre se va a cerrar la
conexin.
De todos modos escribir este cdigo es algo tedioso sobre todo si queremos que la
excepcin se replique y slo metemos la clusula Finally por el hecho de cerrar la
conexin.
Para facilitar el trabajo VB.NET en .NET 2.0 incluye una clusula especial denominada
Using que habilita la destruccin automtica de los objetos a los que se hace
referencia. As el cdigo anterior quedara simplemente:
Al terminar la clusula Using (aunque haya un error por medio) se llama de manera
automtica al mtodo Dispose del objeto utilizado (en este caso una conexin). Entre
otras cosas este mtodo se encarga de cerrar el objeto si estaba abierto, por lo que no
nos tendremos que preocupar de este aspecto.
1.3.2.1.3. Grupos de registros
Aunque los DataReader se asemejan al funcionamiento de un cursor firehose, en
realidad difieren bastante de stos. Imaginemos que conectamos con la base de datos
en el ejemplo anterior y, mientras estamos procesando el bucle de los registros, se
interrumpe la conexin a la base de datos por el motivo que sea.
En principio en el caso de un cursor firehose tradicional obtendramos un error porque
se ha roto la conexin con el servidor. En el caso de un DataReader es posible que
sigamos ejecutando varias vueltas ms del bucle sin problemas. Esto se debe a que, en
44
realidad, el DataReader obtiene los registros en grupos a travs de la conexin y va
solicitando nuevos grupos a medida que los necesita.
Es algo que hay que tener en cuenta a la hora de utilizarlos.
1.3.2.1.4. Ventajas e inconvenientes
El cdigo anterior, aunque sencillo, es un poco lioso y el uso de los DataReader est
algo limitado dada su idiosincrasia (de slo lectura y hacia adelante). Este cdigo es
adecuado si no necesitamos almacenar los resultados de la consulta en memoria ni
regresar sobre ellos una vez procesados una primera vez. Tambin es muy til para
obtener resultados con miles o millones de registros que queremos tratar
secuencialmente pero no almacenar en memoria.
Sin embargo para un uso cotidiano se trata de un cdigo muy poco til y complicado de
utilizar salvo para cosas muy sencillas. Adems slo hemos utilizado clases de la capa
conectada de ADO.NET. Todava debemos aprender a obtener los resultados dentro de
un DataSet para su explotacin de manera cmoda. Hay que tender un puente entre
ambos mundos (conectado y desconectado): el DataAdapter.
1.3.2.2. DataAdapter: puente entre mundos
Si lo que deseamos es poder almacena temporalmente en memoria los datos obtenidos de
una consulta debemos recurrir al uso de objetos de la clase DataSet. Como sabemos se
trata de un almacenamiento en memoria desvinculado por completo del origen de los
datos.
Si el ejemplo anterior lo modificamos para convertirlo en una funcin que nos devuelva un
DataSet con los datos obtenidos a partir de la consulta, el resultado sera similar a este:
La primera parte del cdigo es como la anterior. Se crean una conexin y un comando. Lo
que difiere bastante es la segunda parte. Hay varias diferencias importantes:
1. Ya no aparece en el cdigo objeto DataReader de tipo alguno.
2. No se abre ni se cierra la conexin a la base de datos.
3. Se crea un nuevo DataSet y aparece un objeto de la clase DataAdapter.
45
Un DataAdapter es una clase que conoce las particularidades de la capa conectada de un
determinado proveedor y es capaz de "comunicar" informacin entre sta y la capa
desconectada formada por los DataSet.
El mtodo Fill de un DataAdapter se encarga e rellenar un DataSet con los datos obtenidos
a partir de una consulta (o procedimiento almacenado) definida a travs de un comando.
Su propiedad SelectCommand se usa para indicar qu comando se utilizar para rellenar
el DataSet.
Internamente el mtodo Fill emplea el objeto DataReader devuelto por ExecuteReader y
rellena el DataSet con l por lo que sera factible crear un cdigo equivalente. Sin embargo
es muy cmodo y nos evita problemas y el tener que "reinventar la rueda" en cada
proyecto.
1.3.2.2.1. El objeto DataSet
Los objetos DataSet contienen a su vez objetos DataTable que son los que contienen
realmente los datos. Para acceder a las tablas de un DataSet se utiliza su coleccin
Tables. Se puede acceder a las tablas por posicin (nmeros enteros) o por nombre si lo
sabemos.
En un ejemplo sencillo como el anterior (y por otro lado uno de los ms comunes) se
crea una nica tabla en el DataSet de nombre "Table1" y posicin 0.
Las tablas contienen dos colecciones interesantes:
Columns: conjunto de objetos de tipo DataColumn que ofrecen informacin sobre
los campos de la tabla (nombre, tipo, longitud...).
Rows: coleccin de objetos de la clase DataRow que contienen informacin concreta
sobre cada campo de un registro de la base de datos.
Con esta informacin resulta muy sencillo tratar los datos de una consulta. Podemos
acceder directamente a cualquier registro de la tabla usando su posicin en la coleccin
de filas. Por ejemplo para acceder al quinto registro de una tabla basta con escribir:
Dim dr As DataRow
Dr = ds.Tables(0).Rows(4)
(ntese que las colecciones comienzan a numerarse en 0, de ah que el quinto registro
tenga ndice 4).
Podemos acceder a cualquier campo del registro usando su posicin o bien su nombre,
as:
ds.Tables(0).Rows(4)("CompanyName")
que devolver un objeto del tipo adecuado para el campo que representa (una cadena,
un objeto de fecha, un booleano, etc...).
Nota: Es muy sencillo definir objetos DataTable que dispongan de los campos que
deseemos sin depender de origen alguno de datos. Emplee el mtodo Add de la
coleccin Columns para crear nuevos campos, algunos de los cuales pueden ser incluso
derivados mediante una frmula de los valores de otros. Esto permite definir
estructuras de almacenamiento a medida en memoria sin preocuparnos de usar una
base de datos para ello.
1.3.2.2.2. Ventajas del uso de objetos DataSet
Es posible cargar datos de varias tablas en un mismo DataSet, incluso aunque procedan
de bases de datos diferentes, y relacionarlas en memoria. Es posible establecer
relaciones entre ellas para mantener la consistencia, as como hacer un mantenimiento
en memoria de los datos (altas, bajas y modificaciones). Posteriormente se puede
46
sincronizar el DataSet con el servidor usando un DataAdapter, realizando el proceso
contrario al de obtencin de datos. Luego lo veremos.
La principal ventaja de un DataSet es que podemos almacenarlo en donde queramos
(en una variable global, en cach, incluso a disco a una base de datos) para trabajar
con l sin estar conectado a una base de datos. De hecho se pueden transferir DataSet
completos entre diferentes mquinas o por Internet, trabajar con ellos en remoto,
almacenarlos, recuperarlos y finalmente transferirlos en cualquier momento de nuevo al
origen (enteros o slo los cambios) para sincronizarlos.
Es posible moverse con libertad entre los registros de una tabla y sus registros
relacionados en otras tablas. Y sobre todo, se pueden vincular con elementos de la
interfaz grfica para mostrar los datos automticamente.
1.3.2.3. Consultas parametrizadas
Las consultas simples como la que acabamos de utilizar en los ejemplos anteriores son muy
raras. En la realidad las consultas son mucho ms complejas, suelen intervenir varias
tablas y dependen de diversos parmetros que le aaden condiciones.
Por ejemplo, si en la base de datos Northwind queremos obtener slo aquellos clientes de
un pas determinado. Podramos escribir de nuevo la funcin DameClientes para que se
pareciese a la siguiente:
Esta funcin acepta un pas como parmetro y lo nico que hace es concatenar a la
consulta una nueva condicin que introduce el pas.
Esto, sin duda, funcionara. Sin embargo presenta multitud de problemas seguramente no
demasiado obvios para los programadores noveles. Los ms importantes son los
siguientes:
1. Este cdigo es vulnerable a problemas de seguridad provocados por ataques de
inyeccin de SQL. Esto puede poner en peligro fcilmente nuestra aplicacin e incluso
todo nuestro sistema en casos graves. El estudio de esta problemtica se sale del
mbito de este curso, pero crame cuando le digo que se trata de un gravsimo
problema que debemos evitar a toda costa.
47
2. Si se solicitan 100 consultas idnticas al servidor en las que slo vara el nombre del
pas por el que se filtra, ste no tiene modo de saber que son las mismas y sacar factor
comn. Es decir, no se puede reutilizar el plan de consulta de la primera de ellas
para las dems por lo que se debe calcular de nuevo cada vez, incidiendo en el
rendimiento y la escalabilidad de la aplicacin. Obviamente en consultas ms
complicadas es un problema ms importante que en esta.
3. Este cdigo es ms difcil de transportar a otros sistemas de bases de datos ya que hay
que incluir los delimitadores y notaciones especficos de cada gestor. Por ejemplo en
SQL Server los delimitadores de fechas son comillas simples ('), mientras que en Access
son almohadillas (#) y la sentencia usada no se puede reutilizar.
La forma correcta de realizar este tipo de consultas es utilizar parmetros en la consulta.
Ello evita los problemas enumerados.
Los objetos de tipo Command disponen de una coleccin llamada Parameters que sirve
para asignar dichos parmetros. stos previamente se definen en la consulta utilizando
comodines que marquen su ubicacin.
Nota: Cada proveedor de datos utiliza su propia convencin para indicar la posicin de los
parmetros en una consulta. En el caso de SQL Server se indican con una arroba '@'
seguida de un identificador. En otros proveedores no se puede definir nombre para los
parmetros, slo se marca su posicin con un caracter especial.
La funcin anterior empleando parmetros sera la siguiente:
Se ha resaltado los cambios.
Como vemos en lugar de concatenar cadenas se marca la posicin de las partes de la
consulta que varan con un parmetro que consta de una arroba seguida de un
identificador.
Luego hay que declarar el parmetro aadindolo a la coleccin de parmetros. Para ello se
indica su nombre y el tipo de datos que representa (en este caso un NVarChar de SQL
Server, que es una cadena de longitud variable).
48
Por fin se asigna su valor concreto antes de lanzar la consulta.
El proveedor de datos crea la consulta de la manera correcta, usando los delimitadores
adecuados y tratando los datos del modo que sea preciso para asegurar que es correcta.
Ello elimina los problemas de los que hablbamos anteriormente y permite optimizar el uso
de consultas.
1.3.2.4. Altas bajas y modificaciones
Con lo que hemos visto hasta ahora ya estamos en condiciones de escribir cdigo para
realizar altas, bajas y modificaciones de registros. Al fin y al cabo stas son simplemente
consultas SQL del tipo adecuado (INSERT, DELETE o UPDATE) que se deben enviar al
servidor.
As pues, para crear un nuevo cliente podemos escribir una funcin como la siguiente:
Es un cdigo muy similar al anterior que realizaba una seleccin de datos. En este caso se
ha definido una consulta de insercin con tres parmetros. En lugar de usar ExecuteReader
o un DataAdapter en este caso se utiliza el mtodo ExecuteNonQuery. ste lanza la
consulta (es decir, se inserta el nuevo registro) y devuelve el nmero de registros
afectados por la consulta (que en el caso de una insercin siempre es 1 si se inserta
correctamente o 0 si ha habido un error).
Las actualizaciones y eliminaciones de registros se podran conseguir de modo similar.
1.3.2.4.1. Trabajando desconectados
El cdigo anterior funciona perfectamente pero no es la forma ptima de trabajar
cuando tenemos que tratar con datos desconectados contenidos en objetos DataSet.
49
Los DataSet normalmente circulan, independientes de cualquier origen de datos, entre
las diferentes capas de una aplicacin e incluso se mueven entre contextos de ejecucin
y mquinas (por ejemplo a travs de un servicio Web como veremos). Hemos dicho que
son como pequeas bases de datos, por lo que la forma habitual de trabajar con ellos es
aadir, eliminar y modificar registros directamente sobre sus tablas, sin pensar en la
ubicacin real de estos datos.
As pues, para crear un nuevo registro en un DataSet debemos usar el mtodo
NewRow del DataTable en la que lo queremos insertar. El nuevo registro tiene la
misma estructura (el mismo "esquema") que el resto de registros y slo tendremos que
rellenar sus datos. Una vez rellenados aadiremos el nuevo registro a la coleccin de
filas de la tabla. As por ejemplo si tenemos almacenado un DataSet con una tabla con
los datos de los clientes obtenidos con la funcin de ejemplo DameClientes, podramos
agregar uno nuevo de la siguiente manera:
Es decir, se crea la nueva fila/registro, se rellenan sus campos y se aade a la coleccin
de filas con el mtodo Add de sta.
La actualizacin de datos es ms sencilla an ya que basta con acceder directamente al
registro que nos interesa modificar y cambiar los valores de sus campos. Por ejemplo,
para modificar la direccin del cliente cuyos datos estn en el quinto registro de nuestra
tabla slo hay que escribir:
Por fin, para eliminar un registro slo hay que usar su mtodo Delete, as:
que borrara el quinto registro de nuestra tabla en memoria.
1.3.2.4.2. Conciliando los cambios con el origen
Es muy fcil trabajar con los Dataset en memoria de este modo. Slo hay un "pequeo"
problema: los cambios se realizan en memoria pero, al no estar vinculado el DataSet
con origen de datos alguno, no los veremos reflejados en la base de datos que es lo que
buscamos.
Debemos realizar una sincronizacin entre la representacin en memoria de los datos y
su ubicacin fsica real, para lo cual debemos hacer que los cambios trasciendan a la
capa conectada. Al igual que cuando los recuperamos, el trasiego en el otro sentido se
realiza con la ayuda del puente que representa la clase DataAdapter.
Al igual que utilizbamos la propiedad SelectCommand para indicar cmo se
recuperaban los datos hacia un DataSet, ahora debemos utilizar las propiedades
InsertCommand, UpdateCommand y DeleteCommand para indicar qu comandos
se deben usar para agregar, modificar y eliminar los registros modificados en memoria
a travs del DataSet.
Una vez especificados estos comandos slo resta llamar al mtodo Update del
DataAdapter para que se ocupe de sincronizar automticamente todos los cambios que
hayamos realizado en las tablas en memoria. Este mtodo acepta como argumentos un
50
DataSet completo, una DataTable o incluso un DataRow si slo queremos actualizar un
nico registro.
1.3.2.4.3. Definicin de los comandos
Los comandos de insercin, modificacin o borrado para el DataAdapter se definen del
mismo modo que en el cdigo de ejemplo al principio de este apartado, es decir, se
define la consulta apropiada y sus parmetros. En esta ocasin como los parmetros
sern rellenados automticamente por el DataAdapter hay que utilizar una sobrecarga
del mtodo Add de la coleccin de parmetros que incluye el nombre del campo
asociado con el parmetro, as:
En este caso se define el parmetro "@Direccin", de tipo NVarChar y longitud 60 que
se refiere siempre al valor del campo "Address" de la tabla.
Por ejemplo, para definir la consulta de eliminacin de registros de la tabla de clientes
usaramos el siguiente cdigo:
siendo CustomerID la clave primaria de la tabla.
Una vez definidos los tres parmetros de alta, baja y modificacin slo resta llamar a
Update para que el DataAdapter se ocupe de toda la sincronizacin.
1.3.2.4.4. Ventajas
Este modelo est lleno de ventajas aunque a primera vista pueda parecer algo
engorroso.
Nota: Luego veremos que podemos usar las herramientas que nos proporciona Visual
Studio 2005 para definir de manera automtica los comandos de manipulacin de datos
sin necesidad de pasar el trabajo de hacerlo manualmente.
Para empezar podemos trabajar con los datos en total libertad sin preocuparnos de si
existe conexin o no con el origen y aunque el DataSet se manipule en una ubicacin
fsica a miles de kilmetros del origen y desconectado de ste o los cambios se
almacenen a disco y se concilien das ms tarde.
Se pueden realizar multitud de modificaciones en los datos y luego conciliarlas
simultneamente en lugar de hacerlo en tiempo real de una en una.
El paso de datos entre capas y funciones se simplifica. Lo habitual antes era definir
funciones con tantos parmetros como datos se quisieran modificar en un registro. Por
ejemplo, para insertar un registro en una tabla que tiene 20 campos se defina una
funcin con 20 parmetros (muchos de ellos opcionales) o, en el mejor de los casos, se
pasaba una clase creada a medida que representaba lo valores del registro. Ahora basta
con pasar un DataSet, un DataTable o un dataRow que ya contiene toda la informacin
que necesitamos saber sobre los registros y su tabla asociada.
Lo mejor es que es posible saber mediante ciertas propiedades qu registros han
cambiado (nuevos, modificados, borrados) y mover entre capas exclusivamente estos.
La propiedad HasChanges de los DataSet, DataTable y DataRow nos informa de si el
objeto ha sufrido cambios de algn tipo.
El mtodo GetChanges de los objetos DataSet y DataTable devuelve un subconjunto
de los datos que contiene exclusivamente los cambios. As, aunque en un DataSet
51
tengamos 1000 registros, si slo hemos modificado 2 slo ser necesario trasegar la
informacin de estos a la hora de enviarlos a otra capa o funcin para sincronizarlos con
la base de datos.
El mtodo GetChanges se puede invocar sin parmetros o indicando qu tipo de
cambios queremos obtener, lo que se indica con un valor de la enumeracin
DataRowState:
Valor Significado
Added Registros que no estaban originalmente
Deleted Registros que se han eliminado
Modified Registros cuyos valores se han modificado
UnChanged Registros que no se han modificado
Detached Registros que se han desasignado de una tabla (pero no borrado con
Delete)
Se puede dejar un DataSet en estado sin modificar llamando a su mtodo
AceptChanges. Esto es lo que hace un DataAdapter tras haber sincronizado los
cambios con el origen de datos.
1.3.3. Acceso a datos con Visual Studio 2005
Ahora que ya hemos visto la forma de trabajo manual con ADO.NET y dominamos los
fundamentos, vamos a sacar partido a todas las ventajas que nos proporciona un entorno
como Visual Studio 2005 que, como veremos, nos permiten hacer casi cualquier tarea de datos
sin necesidad de escribir cdigo.
1.3.3.1. Controles de datos
Aparte de la escritura manual de cdigo y el uso directo de objetos de ADO.NET, ASP.NET
2.0 proporciona un nuevo modelo de trabajo declarativo para acceso a datos que nos
permite realizar tareas comunes de acceso a datos sin escribir cdigo alguno.
ASP.NET 2.0 presenta dos nuevos tipos de controles Web que participan en este modelo
declarativo de enlace a datos. Estos controles nos abstraen por completo de las
complejidades de manejo de las clases de ADO.NET por un lado, y de las dificultades
inherentes al modo de trabajo desconectado de las pginas Web. Equiparan en muchos
aspectos el desarrollo Web al tradicional desarrollo de aplicaciones de escritorio.
Estos controles se encuentran agrupados en el cuadro de herramientas bajo el nombre de
"Datos", tal y como se ve en la figura.
52
1.3.3.1.1. Orgenes de datos
Estos controles de datos representan conexiones con diferentes tipos de orgenes de
informacin que van desde bases de datos a objetos de negocio. No disponen de
apariencia visual pero se arrastran igualmente sobre los formularios Web para trabajar
con ellos visualmente y poder usar sus paneles de tareas. Abstraen al programador de
las complejidades relacionadas con el manejo de los datos, permitiendo de manera
automtica seleccionarlos, actualizarlos, ordenarlos, paginarlos, etc.
ASP.NET 2.0 ofrece los siguientes controles de origen de datos que se pueden ver en la
figura anterior:
Control Descripcin
SqlDataSource
Enlaza con cualquier base de datos para que exista un
proveedor de ADO.NET.
AccessdataSource
Esta especializado en trabajar con bases de datos Microsoft
Access.
ObjectDataSource
Se enlaza con objetos de negocio y capas personalizadas de
acceso a datos.
XmlDataSource Trata datos contenidos en documentos XML.
SiteMapDataSource
Se enlaza con la jerarqua de clases expuesta por el modelo de
navegacin de sitios de ASP.NET 2.0.
ATENCIN!: El control SqlDataSource sirve para enlazar con cualquier gestor de
datos relacional para la que haya proveedor ADO.NET disponible, no slo para enlazar
con SQL Server. No se deje despistar por su nombre.
1.3.3.1.2. Concurrencia optimista
Durante la configuracin de un origen de datos SQL (luego lo ver en el primer vdeo de
esta leccin) una de las opciones avanzadas que se presenta habla de la Concurrencia
optimista. La concurrencia optimista evita la actualizacin de registros en el caso de
que haya variado cualquiera de sus campos desde que se obtuvieron de la fuente de
datos. Este comportamiento puede ser bueno en ciertas ocasiones, cuando queremos
preservar los cambios realizados por cualquier usuario. En otras sin embargo no resulta
de utilidad y s aade una gran sobrecarga al acceso a datos.
53
Se le denomina concurrencia optimista porque parte de la base de que la posibilidad de
coincidencia de dos usuarios sobre el mismo registro es baja y es un caso que apenas
se dar. Al caso contrario a la concurrencia optimista se le denomina concurrencia
pesimista.
Nota: En mi opinin debera llamarse "concurrencia realista" ya que, lo cierto es que si
se analiza con detenimiento la posibilidad de conflicto en un sistema grande tiende a ser
realmente pequea en la mayora de los casos. Y de todos modos el sobreescribir cierta
informacin no suele ser un problema grave salvo cuando hablamos de cuestiones de
dinero, facturas y similares.
Cuando se establece la concurrencia optimista las consultas que genera el asistente de
Visual Studio incluyen todos los campos del registro como condicin de bsqueda del
mismo, por ejemplo:
DELETE FROM [Customers]
WHERE [CustomerID] = @original_CustomerID
AND [CompanyName] = @original_CompanyName
AND [ContactName] = @original_ContactName
AND [ContactTitle] = @original_ContactTitle
AND [Address] = @original_Address
AND [City] = @original_City
AND [Region] = @original_Region
AND [PostalCode] = @original_PostalCode
AND [Country] = @original_Country
AND [Phone] = @original_Phone
AND [Fax] = @original_Fax
mientras que en un caso de concurrencia pesimista se emplea simplemente la clave
primaria del registro para localizarlo:
DELETE FROM [Customers] WHERE [CustomerID] = @original_CustomerID
Es decisin suya qu tipo de actualizacin utilizar pero en la mayor parte de los casos
usar seguramente la pesimista que, de hecho, es la que usted utiliza normalmente si
escribe las funciones a mano de manera independiente.
1.3.3.1.3. Controles enlazados a datos
Se trata de controles de interfaz de usuario que, haciendo uso de los anteriores,
muestran la informacin a travs de la pgina. Pueden sacar partido a todas las
propiedades de los orgenes de datos y por lo tanto habilitan de manera sencilla la
edicin, eliminacin, ordenacin, filtrado y paginacin de los datos entre otras cosas.
Para conectar un control enlazado a un DataSource slo hay que establecer su
propiedad DataSourceID indicando el nombre apropiado. As de fcil.
Nota: Si usted ya conoce los controles enlazados a datos de ASP.NET 1.x como el
DataGrid, el DataRepeater, etc... estos controles le resultarn ms cmodos de utilizar
pues al contrario que con aquellos no hay que escribir cdigo alguno. Aunque estos
controles "antiguos" no aparecen en el cuadro de herramientas siguen estando
soportados y los puede seguir utilizando. Incluso si lo desea puede aadirlos al cuadro
de herramientas. De todos modos se recomienda utilizar el nuevo modelo declarativo de
acceso a datos.
1.3.3.1.4. Uso de los controles de datos en la prctica
La mejor forma de conocer la manera de trabajar con estos controles es vindolos
actuar en la prctica. Los vdeos de esta leccin muestran un ejemplo completo de uso
de los controles en el que se explotan unos datos para su visualizacin, edicin y
eliminacin. Por favor, examnelo con atencin y luego trate de practicarlo por su cuenta
con ejemplos similares.
54
1.3.3.2. DataSet tipados
La clase DataSet, como cualquier otra clase no sellada de .NET, puede ser extendida
mediante herencia para aadirle nuevas funcionalidades y aprovechar las ya existentes. Si
creamos una nueva clase que herede de DataSet y sta la especializamos en el tratamiento
de un conjunto de datos determinado que conocemos de antemano nos encontramos un
DataSet especializado.
Por ejemplo, podemos crear un DataSet especial que tengan en cuenta las particularidades
de los datos que maneja para validarlos antes de permitir su insercin, que verifique las
relaciones con otros datos o que los transforme o controle el acceso a los mismos. Nosotros
slo tendramos que ocuparnos de estas tareas dejando a la clase DataSet de la que hemos
heredado todos los puntos complejos que tienen que ver con la gestin de datos pura y
dura.
Esta es, en esencia, la idea que subyace bajo los DataSet tipados de Visual Studio 2005.
Se trata de clases especializadas derivadas de DataSet que ofrecen una forma ms rpida y
sencilla de acceder a los datos que albergan. Adems Visual Studio nos permite crear este
tipo de DataSet de forma visual y usando asistentes. En el vdeo se ilustra la manera de
conseguirlo.
Los DataSet tipados parten del conocimiento preciso de la estructura de una base de datos
para definir su funcionalidad. Esta es su principal diferencia con los DataSet normales
puesto que stos son genricos y no saben nada acerca de los datos que albergan. Los
tipados slo sirven para albergar una informacin muy concreta. Ganan en especializacin
y pierden en versatilidad.
Para agregar un DataSet tipado a nuestro proyecto slo hay que presionar con el botn
secundario sobre la carpeta App_Code y en el dilogo que aparece elegir el icono de
DataSet. La extensin del archivo generado es '.xsd' porque lo que en realidad albergan es
un esquema XML que define la estructura de los datos en los que se van a especializar.
Una vez agregado el DataSet aparece una superficie de diseo y un asistente como el de la
figura.
Figura 4.5.- Primer paso del asistente de configuracin de un TableAdapter.
55
Este asistente nos permite configurar un objeto TableAdapter que se encargar de
trasegar datos entre el DataSet tipado que estamos creando y la base de datos. Un
TableAdapter es una clase que encapsula a un DataAdapter especializado en los datos que
vamos a procesar con la tabla del DataSet tipado que estamos definiendo. De hecho sus
mtodos son, por defecto, los mismos que los de un DataAdapter normal (Fill, Update...).
Con l dispondremos de mtodos para recuperar informacin, crear nuevos registros,
actualizarlos y eliminarlos, slo que los correspondientes comandos estarn creados de
manera automtica o asistindonos en ello. As, por defecto, se definen un par de mtodos
para obtener los datos subyacentes rellenando un DataSet que se le pase (mtodo Fill) o
devolviendo directamente un DataTable (mtodo GetData). Adems el mtodo Update
sirve para conciliar automticamente los cambios del un DataSet tipado con la base de
datos original.
No vamos a analizar desde el texto la definicin de estos objetos adaptadores pero puede
conocerlo viendo el vdeo de esta leccin.
Truco: Podemos ver el cdigo que se genera de manera automtica para crear el
DataAdapter si hacemos doble-clic sobre l desde el examinador de objetos de Visual
Studio (CTRL+ALT+J). Esto har que se abra el archivo de cdigo auto-generado por
ASP.NET desde la ubicacin real de ejecucin (normalmente una ruta del estilo
C:\Windows\Microsoft.NET\....). Es muy interesante echarle un vistazo a este cdigo para
aprender el funcionamiento interno de los DataSet tipados.
1.3.3.2.1. Partes de un DataSet tipado
Al igual que un DataSet normal, uno tipado consta de un conjunto de tablas y relaciones
entre ellas. En este caso, sin embargo, podemos acceder a las tablas y a sus campos
utilizando directamente sus nombres en lugar de recorrer la coleccin de tablas, lo cual
lo hace ms fcil de usar.
Cada una de las tablas del DataSet lleva asociado como mnimo un TableAdapter. Entre
los dos objetos (el DataTable y el o los TableAdapter relacionados) se reparten el
trabajo. El DataTable tipado mantiene en memoria la informacin y el TableAdapter
acta de puente con la tabla real en la base de datos.
Nota: Como sabemos (y veremos en el vdeo tambin) las tablas de un DataSet no
tienen porqu coincidir con tablas reales de una base de datos ya que pueden ser
resultados obtenidos de una consulta compleja que involucre a varias tablas. En estos
casos es ms complicada la actualizacin y se suelen usar nicamente para recuperar
datos. la alternativa habitual es tratar de replicar la estructura fsica de la base de datos
en la estructura en memoria del DataSet de modo que se tiene acceso estructurado a la
misma informacin y gracias a las relaciones y restricciones se conserva la consistencia
de los datos tambin estando desconectados.
El DataSet tipado dispone de propiedades que coinciden con los nombres de los objetos
que contienen. As, por ejemplo, si tenemos una tabla "Clientes" con un campo
"Nombre" podemos acceder a l directamente con este cdigo:
ds.Clientes(0).Nombre
que nos dara el nombre del primer cliente de la tabla de clientes en el DataSet 'ds'.
esta propiedad nombre adems ya sera un campo de tipo String que es el tipo
adecuado para la informacin albergada, por lo que se simplifica mucho su uso.
En un DataSet normal para obtener lo mismo tendramos que haber escrito:
ds..Tables(0).Rows(0)("Nombre").ToString()
que obviamente es mucho menos legible.
La cosa no termina aqu ya que adems se definen clases especficas para representar
los registros de las tablas. Por ejemplo si la tabla se llama 'Clientes' existir una clase
56
ClientesRow que dispone de propiedades con el mismo nombre y tipo que los campos
correspondientes en la tabla de la base de datos y que hemos usado en la lnea de
ejemplo. As, para aadir un cliente podramos escribir:
Dim cliente As New Cliente
cliente.Nombre = "Pepe"
....
ds.Clientes.AddClientesRow(cliente)
Ntese que el mtodo Add del DataTable se ha sustituido por uno con nombre
especializado que nos ayuda a saber mejor por donde pisamos, pero su funcin es
idntica.
Para rellenar una tabla de un DataSet tipado se usa su correspondiente TableAdapter
as:
Dim clientes As New ClientesDS
Dim ta As New ClientesTableAdapters.ClientesTableAdapter()
ta.Fill(clientes.Clientes)
clientes.Clientes(0).Nombre = "Pepe"
....
o tambin usando el mtodo GetData para obtener la tabla directamente si slo nos
interesa esa parte concreta del DataSet (que puede constar de varias tablas):
Dim clientes As Clientes.ClientesDataTable
Dim ta As New ClientesTableAdapters.ClientesTableAdapter()
clientes = ta.GetData()
clientes(0).Nombre = "Pepe"
....
Para un mismo DataTable tipado se pueden definir diversos TableAdapter especializados
aparte del bsico que permite llenar todos los datos: para filtrar por diversos
parmetros normalmente.
El uso de DataSet tipados es muy recomendable puesto que simplifica mucho el trabajo
puesto que podemos realizar casi todo el trabajo utilizando asistentes y accediendo a la
informacin de manera muy cmodo. Adems es un modo muy sencillo de separar la
funcionalidad de la base de datos del resto del cdigo. As, si se hace necesario en el
futuro, se puede exponer esta parte de manera independiente mediante un, por
ejemplo, un servicio Web que utilice el DataSet tipado y sus TableAdapters para acceder
a los datos desde una ubicacin remota.
57
2. Creacin de bases de datos con Visual Studio
La mayora de aplicaciones comerciales (y principalmente las de gestin) utilizan datos que deben
guardarse en algn sitio. Generalmente esta informacin se guarda en bases de datos. En ste
mdulo, vers cmo crear una base de datos para SQL Server 2005 Express, y crears tablas para
guardar la informacin a almacenar; aprenders sobre los tipos de datos que forman las columnas
de las tablas, cmo relaciona las tablas, integridad, y cmo realizar consultas sobre las tablas.
2.1. Objetos bsicos del sistema
2.1.1. Crear una base de datos
Cuando se crea una base de datos, es importante comprender cmo SQL Server almacena los
datos para poder calcular y especificar la cantidad de espacio en disco que hay que asignar a
los archivos de datos y registros de transacciones. Aunque SQL Server automticamente
incrementa el tamao asignado a los ficheros de bases de datos dinmicamente, para tener un
rendimiento ptimo del sistema (evitar fragmentacin de los ficheros), se recomienda ser
"precisos" a la hora de definir el tamao de la base de datos.
2.1.1.1. Ficheros de la base de datos
Todas las bases de datos tienen un archivo de datos principal (.mdf), y uno o varios
archivos de registro de transacciones (.ldf). Una base de datos tambin puede tener
archivos de datos secundarios (.ndf). La extensin definida para cada tipo de archivos es
libre, pero como buenas prcticas se suele seguir el modelo de extensiones recomendado
por Microsoft (mdf, ldf, y ndf). El proceso de creacin de la base de datos, consiste en
hacer una copia de la base de datos model, que incluye las tablas del sistema. La ubicacin
predeterminada para todos los archivos de datos y registros de transacciones es
C:\Archivos de programa\Microsoft SQL Server\MSSQL.1\MSSQL\Data.
La base de datos puede configurarse con tres modelos de recuperacin en caso de fallo del
sistema (FULL, BULK_LOGGED, y SIMPLE); evala cada modelo en base a las necesidades
del sistema que ests implementando.
2.1.1.2. Creacin de base de datos desde SQL Server 2005 Management
Studio Express
SQL Server Management Studio Express es la herramienta de administracin incluida con
SQL Server Express; la herramienta no fue incluida en la primera distribucin de SQL
Server Express, y se puede descargar de forma gratuita de la siguiente url:
Microsoft SQL Server Management Studio Express - Community Technology Preview (CTP)
November 2005:
http://www.microsoft.com/downloads/details.aspx?familyid=82afbd59-57a4-455e-a2d6-
1d4c98d40f6e&displaylang=en
58
Para crear una base de datos desde SQL Server 2005 Management Studio, expande la lista
de bases de datos, de la lista de instancias de SQL Server 2005 registradas, y selecciona la
opcin "New database":
59
Debers rellenar el nombre de base de datos, nombres lgico y fsico de los archivos
relacionados, y tamao de los ficheros, as como su crecimiento:
60
Y debers establecer el modo de recuperacin de la base de datos; en la versin Express al
crear una base de datos por defecto se establece como recuperacin SIMPLE:
Para famializarte con la sintaxis del lenguaje T-SQL, te recomiendo que utilices la opcin de
men script (en recuadro verde en las dos imgenes anteriores), que mostrar la
instruccin T-SQL correspondiente a las operaciones que has ido configurando en las
distintas opciones.
2.1.1.3. Consideraciones
Dependiendo de las necesidades a cubrir del sistema de base de datos a desarrollar,
debers configurar los archivos de una forma u otra; por ejemplo, en grandes sistemas
llegars a configurar niveles de redundancia de discos (RAID), y repartirs la informacin
de las tablas en distintos ficheros. Aunque no est soportado en la versin Express,
funcionalidades del producto como Particionado de datos, llegan a ser primordiales, y es un
factor a considerar desde el momento de diseo del sistema.
Por otro lado, para familiarizarte con SQL Server, recomendara entender las opciones de
configuracin de base de datos que aparecen en la pestaa opciones, que aunque no son
necesarias para comenzar a disear bases de datos SQL Server, si ayudan a comprender
un poco el funcionamiento interno de SQL Server (shrink, statistics, etc.):
61
2.1.2. Tipos de datos
Empezaremos por los tipos de datos. Las tablas tienen columnas, y las columnas se definen en
base a un tipo de datos; los tipos de datos acotan el tipo y tamao de la informacin que se
guardar en una columna. La importancia de la eleccin de los tipos de datos reside en el
almacenamiento que ocupa; para varios cientos de filas, el tamao no es tan crucial, pero
cuantas ms filas se aadan a la tabla, mayor ser la repercusin en el rendimiento de las
operaciones de E/S.
Como veremos, habr tipos de datos en los que habr que seleccionar el tamao, e incluso
algunos tendrn la posibilidad de ofrecer tamao variable; vamos a analizar los ms
significativos.
2.1.2.1. Tipos de datos numricos
Los tipos de datos numricos se utilizan para guardar valores numricos enteros, o
decimales. Los dividiremos en dos grandes grupos: enteros, y decimales.
62
2.1.2.1.1. Tipos de datos numricos enteros
Tipo de dato Precisin Almacenamiento
bigint
De -2^63 (-9.223.372.036.854.775.808)
a 2^63-1 (9.223.372.036.854.775.807)
8 bytes
int
De -2^31 (-2.147.483.648) a 2^31-1
(2.147.483.647)
4 bytes
smallint De -2^15 (-32.768) a 2^15-1 (32.767) 2 bytes
tinyint De 0 a 255 1 bytes
bit 0,1
1 bit, mmino 1
bytes
Tradicionalmente el tipo de datos ms usado es el int; el tipo de datos bigint apareci
en SQL Server 2000, y es la alternativa al tipo de datos int, cuando los valores son muy
grandes.
2.1.2.1.2. Tipos de datos numricos decimales
Decimal, numeric. Tipo de datos numrico con precisin y escala fijas.
decimal[ (p[ ,s] )] y numeric[ (p[ ,s] )]
Nmeros de precisin y escala fijas. Cuando se utiliza la precisin mxima, los valores
permitidos estn comprendidos entre - 10^38 +1 y 10^38 - 1. Numeric equivale
funcionalmente a decimal
p (precisin). El nmero total mximo de dgitos decimales que se puede almacenar,
tanto a la izquierda como a la derecha del separador decimal. La precisin debe ser un
valor comprendido entre 1 y la precisin mxima de 38. La precisin predeterminada es
18.
s (escala). El nmero mximo de dgitos decimales que se puede almacenar a la
derecha del separador decimal. La escala debe ser un valor comprendido entre 0 y p.
Para especificar la escala es necesario haber especificado la precisin.
Y la relacin entre precisin y almacenamiento es:
Precisin Almacenamiento
1-9 5
10-19 9
20-28 13
29-38 17
63
money, smallmoney. Tipos de datos que representan valores monetarios o de
moneda.
Tipo de dato Precisin Almacenamiento
money De -922,337,203,685.477,5808
a 922,337,203,685.477,5807
8 bytes
smallmoney De - 214.748,3648 a
214.748,3647
4 bytes
float(n), single. Tipos de datos numricos y aproximados que se utilizan con datos
numricos de coma flotante. Los datos de coma flotante son aproximados; por tanto, no
todos los valores del intervalo del tipo de datos se pueden representar con exactitud.
Tipo de dato Precisin Almacenamiento
float De -1,79E
308
a -2,23E
-308
, 0 y de
2,23E
-308
a 1,79E
308
Depende del valor
de n (4 u 8 bytes)
real De -3,40E
38
a -1,18E
-38
, 0 y de
1,18E
-38
a 3,40E
38
4 bytes
2.1.2.2. Tipos de datos de caracteres
Los tipos de datos caracter se puede definir de longitud fija y de longitud variable.
Los de longitud fija son char(n) y su tamao lo define el valor que tenga n. Por ejemplo,
una columna char(15) ocupa 15 bytes.
Los de longitud variable son varchar(n), y su tamao lo define la longitud de la columna
guardada; por ejemplo una columna varchar(250), que guarda el valor "columna variable"
el almacenamiento que ocupa es 16 bytes.
En caso de desear valores Unicode, debers anteponer al tipo de datos la letra n, siendo los
tipos nchar, o nvarchar. La principal diferencia con los tipos de datos no-unicode, es que
utilizan el doble de bytes. Por ejemplo, el texto "Tutorial", en una columna varchar(100)
ocupara 8 bytes, mientras que siendo unicode ocupara 16 bytes.
El tamao de las columnas char, varchar, nchar, nvarchar est limitado a 8000 bytes de
almacenamiento; en caso de necesitar mayor longitud puedes usar el tipo de datos
varchar(max) o nvarchar(max), que es nuevo en SQL Server 2005.
2.1.2.3. Tipos de datos fecha
smalldatetime, datetime. Son los tipos de datos utilizados para representar la fecha y la
hora. El valor internamente se almacena como un valor integer, y dependiendo de la
precisin utilizar 4 u 8 bytes.
Tipo de dato Precisin Almacenamiento
smalldatetime Del 1 de enero de 1900 hasta el
6 de junio de 2079
4 u 8 bytes
datetime Del 1 de enero de 1753 hasta el
31 de diciembre de 9999
8 bytes
El tipo de datos smalldatetime almacena las fechas y horas del da con menor precisin que
datetime. El Database Engine (Motor de base de datos) almacena los valores smalldatetime
64
como dos enteros de 2 bytes. Los dos primeros bytes almacenan el nmero de das
despus del 1 de enero de 1900. Los otros dos, almacenan el nmero de minutos desde
medianoche.
Los valores datetime se redondean con incrementos de 0,000; 0,003 o 0,007 segundos,
como se muestra en la siguiente tabla.
2.1.2.4. Otros tipos de datos
Se pueden crear tipos definidos de usuario que suele ayudar para unificar el diseo de las
tablas; por ejemplo, se puede crear un tipo llamado NIF que corresponde al tipo de datos
CHAR(20), y admite valores nulos.
CREATE TYPE NIF FROM char(20) NULL
2.1.2.4.1. XML
La versin 2005 de SQL Server incorpora el tipo de datos nativo XML. El tipo de datos
obliga a que el dato sea por lo menos bien formado (well-formed). Adicionalmente, la
columna puede asociarse a un esquema XSD. Esta es una caracterstica muy
interesante porque cada da se estn guardando ms datos en formato XML, y las
aplicaciones cliente tienen que soportar el coste y codificacin de validar el dato a
guardar. La otra gran funcionalidad que incorpora el tipo de datos XML es que se puede
hacer consultas XPath 2.0 contra la columna XML; adems la columna se puede indexar
para optimizar las consultas XPath.
2.1.2.4.2. Tipos de datos definidos de usuario en .NET
La integracin del CLR, permite la posibilidad de definir tipos de datos con cualquier
lenguaje .NET; durante el curso no se va a tratar este tema, pero como recomendacin
general, slo deberan usarse para definir estructuras complejas; por ejemplo,
coordenadas 3D, o 2D, nmeros complejos, etc. nunca para implementar estructuras
relacionales.
2.1.3. Crear tablas
Las tablas son objetos que contienen la informacin guardada en la base de datos. Una tabla
es una coleccin de columnas; cada columna tendr un tipo de dato y una serie de
propiedades. La informacin est guardada fila por fila de forma similar a lo que grficamente
representa una hoja Excel: una coleccin de filas por columnas.
2.1.3.1. Creacin de tablas
Para crear tablas podremos utilizar SQL Server 2005 Management Studio Express, o Visual
Basic Express Edition; la forma es muy similar en ambas herramientas, y esta vez tambin
utilizaremos SQL Server 2005 Management Studio Express.
Expandiendo la base de datos "DemoMSDN", vemos una lista de tipos de objetos entre las
que se encuentra "tables"; pulsando el botn derecho del ratn, y selecciona "New Table"
como aparecen en la siguiente imagen:
65
Aparecer una ventana como la siguiente que describimos a continuacin:
En el cuadro marcado en rojo, se aaden cada una de las columnas que forman parte de la
tabla a crear; se pone nombre a la columna (debe comenzar por un caracter alfabtico), se
selecciona el tipo de datos y precisin (ver leccin anterior para ms informacin), y se
establece si la columna aceptar valores nulos o no.
66
En el cuadro de debajo (en color azul), se podrn establecer las propiedades de cada
columna de la tabla; se podrn modificar las propiedades vistas anteriormente, si la
columna es calculada o no, si tiene propiedad identidad (que veremos ms adelante en el
captulo), etc.
A la derecha, en el cuadro verde, se podrn establecer propiedades de la tabla; como
esquema al que pertenece la tabla, nombre de la tabla, descripcin de la tabla, y grupo de
ficheros donde se almacenar la tabla.
Adems toda tabla debe tener una columna o conjunto de columnas que identifique de
manera nica cada fila de la tabla; para ello selecciona la columna que deseas como clave
primaria, y despus de hacer click en el botn derecho del ratn, selecciona "Primary Key"
como se muestra en la imagen (tambin se puede hacer sobre el botn marcado en rojo en
la imagen):
67
A continuacin, para grabar los cambios, es decir, para generar la tabla, pulsars sobre la
zona en color verde de la siguiente imagen, y seleccionars la opcin Save Clientes (que es
el nombre de la tabla):
2.1.3.2. Propiedad identity en las columnas
La propiedad identity, establece que una columna numrica genere automticamente
valores consecutivos partiendo de una semilla inicial, y un incremento definido. Se suele
utilizar como clave primaria, en lugar de establecer claves primarias de columnas o
conjuntos de columnas muy grandes. Lo importante de esta propiedad es que "convierte"
automticamente el valor de una columna a un valor numrico siguiente al anteriormente
insertado. Por ejemplo, si definimos la columna Id de la tabla clientes como identity, a la
hora de insertar filas, de esa columna nos "olvidaremos" porque SQL Server lo hace por
nosotros. Luego ese valor lo podremos usar como referencia principal (clave primaria), para
identificar la fila insertada. Para establecer la propiedad identity, debes seleccionar la
columna a la que deseas establecer la propiedad, y hacerlo desde la ventana de
propiedades de columna (cuadro rojo de la siguiente imagen):
68
2.1.4. Relacionar tablas
2.1.4.1. Relacionar tablas
Las tablas se relacionan entre s; podra decirse que existe informacin de la fila que est
guardada en varias tablas. El nexo de unin de las filas es la clave primaria en la tabla
padre, y la clave primaria en la tabla hija. Por ejemplo, una relacin entre clientes y
pedidos; en la tabla pedidos existir un identificador de cliente que est asociado a un
identificador de cliente en la tabla clientes. La informacin estara repartida como sigue:
Clientes
ID Nombre Apellidos ...
1 Julia Herrera ...
2 Javier Alonso ...
Pedidos
IDPedido IDCliente Importe ...
1 1 1200 ...
2 1 1300
3 1 1200
4 2 1000 ...
69
Fjate que el cliente 1 (Julia Herrera), tiene los pedidos del 1 al 3, y el cliente 2 el pedido 4.
La informacin la "interpretamos" como si las filas de cliente en "embebiera dentro de la
tabla pedidos:
Pedidos
IDPedido IDCliente Nombre-Cliente Apellido-Cliente Importe ...
1 1 Julia Herrera 1200 ...
2 1 Julia Herrera 1300
3 1 Julia Herrera 1200
4 2 Javier Alonso 1000 ...
Visto el esquema, vamos a implementar la tabla Pedidos, definiendo la clave ajena a la
tabla clientes. Para ello, despus de haber aadido las columnas que definen la tabla
pedidos (ID, IDCliente, y Cantidad), pulsaremos en el botn habilitado para establecer
relaciones, o seleccionaremos la opcin "Relationships...":
70
Aparecer una ventana como la que se muestra a continuacin, en la que expandirs la
opcin "Tables and columns specifications", y pulsars en el botn encuadrado con bordes
azules, para establecer la relacin entre las tablas:
A continuacin, rellenars los combos que aparecen para establecer la relacin entre las
tablas clientes y pedidos (columnas ID de clientes, e IDCliente de Pedidos):
71
Para finalizar pulsa en aceptar, y expandes la opcin "Insert and Update Expecifications",
en la que se podr especificar cmo establecer el valor de la columna en caso de que la fila
padre haya sido borrada o modificada. En SQL Server 2005, se permiten dos opciones:
No Action. Que indica que no actual, que se deja la columna como estaba.
Cascade. Que se realiza la misma operacin que se hizo en la fila de la tabla padre.
Set Null. Que establece a nulo el valor de las columnas afectadas.
Set Default. Que establece la columna a un valor por defecto.
Con un ejemplo se ver ms claro; digamos que se borra el cliente 2 (Javier Alonso); al
borrar al cliente, las opciones que acabamos de comentar se activarn, y actuarn segn
las hayamos configurado; Veamos como se comportara en cada uno de los casos:
No Action. El pedido se quedara igual, es decir, el pedido nmero 4 se quedara con
referencia al cliente 2, que en realidad ya no existe.
Cascade. Como se trataba de una operacin de borrado de clientes, al borrar al cliente,
tambin se borraran los pedidos asociados al cliente 2; en nuestro ejemplo, el pedido
nmero 4, se eliminara.
Set Null. Al realizar el borrado, el pedido nmero 4 se quedara con identificador de
cliente a un valor nulo; es decir, el pedido seguira existiendo, pero no estara asociado
a ningn cliente.
Set Default. Se establecera un valor por defecto; en nuestro caso no hemos definido
ningn valor por defecto, pero podramos establecer un valor por defecto para
identificar los pedidos cuyos clientes han sido eliminados.
Todas estas operaciones que hemos realizado desde las herramientas grficas, tambin se
pueden hacer con sentencias T-SQL; de hecho, llegar un momento en que tu experiencia
ser tan profunda que te resultar ms sencillo realizar gran parte de las operaciones
mediante sentencias T-SQL. En concreto, las palabras clave para definir este tipo de
sentencias son ALTER TABLE, CREATE TABLE, CONSTRAINT, FOREIGN KEY, PRIMARY KEY.
72
2.1.4.2. Otras restricciones (UNIQUE, CHECK, DEFAULT)
Adems, existen restricciones que "acotan", limitan, o establecen el valor de una columna
en ciertas condiciones. Se llaman restricciones (CONSTRAINTS), y forman parte del
estndar SQL-99. Estas restricciones que vamos a ver son: restriccin UNIQUE, restriccin
CHECK, y restriccin DEFAULT.
2.1.4.2.1. Restriccin UNIQUE
La restriccin UNIQUE establece que el valor de cada columna de una fila sea nico, Por
ejemplo, en la tabla clientes podemos tener una clave primaria como ID, y adems
tener una columna NIF que establecemos que sea nica: lo que internamente
implementa SQL Server, es que cada vez que se intente hacer una modificacin, o
insercin de un valor para esa columna, antes de realizar la operacin, se asegura que
el nuevo/modificado valor es nico en el conjunto de filas de la tabla.
La restriccin UNIQUE se implementa en T-SQL con la palabra clave UNIQUE; por
ejemplo, si queremos que la columna Nombre de la tabla Clientes sea nica, podramos
ejecutar el siguiente cdigo T-SQL:
ALTER TABLE dbo.Clientes
ADD CONSTRAINT RestriccionNombreUnico UNIQUE (Nombre).
2.1.4.2.2. Restriccin CHECK
La restriccin CHECK establece que el valor de la columna se ajuste a ciertas
condiciones. Se define para limitar el valor que pueda tener la columna; por ejemplo, se
puede definir que la columna Importe sea de un valor positivo mayor que cero. SQL
Server, se encargar de "validar" el valor que tendr la columna cuando se intente
hacer una modificacin, o insercin de un valor para esa columna. En caso de que el
valor no cumpla la restriccin, se generar una excepcin y se cancelar la operacin en
curso.
La restriccin CHECK se implementa en T-SQL con la palabra clave CHECK; por ejemplo,
si queremos que la columna Cantidad de la tabla Pedidos sea un valor mayor que cero,
podramos ejecutar el siguiente cdigo T-SQL:
ALTER TABLE dbo.Pedidos
ADD CONSTRAINT RestriccionCantidad CHECK (Cantidad>0).
2.1.4.2.3. Restriccin DEFAULT
La restriccin DEFAULT establece el valor para una columna cuando no se ha
especificado valor en la sentencia de insercin. SQL Server, comprobar si la sentencia
de insercin establece un valor para la columna, y en caso negativo, establecer el valor
por defecto.
La restriccin DEFAULT se implementa en T-SQL con la palabra clave DEFAULT; por
ejemplo, si queremos aadir una columna Importe a la tabla Pedidos, y su valor por
defecto sea cero, podramos ejecutar el siguiente cdigo T-SQL:
ALTER TABLE dbo.Pedidos
ADD Importe DEFAULT (0).
2.1.5. Creacin de ndices
Los ndices son "estructuras" alternativa a la organizacin de los datos en una tabla. El
propsito de los ndices es acelerar el acceso a los datos mediante operaciones fsicas ms
rpidas y efectivas. Para entender mejor la importancia de un ndice pongamos un ejemplo;
imagnate que tienes delante las pginas amarillas, y deseas buscar el telfono de Manuel
Salazar que vive en Alicante. Lo que hars ser buscar en ese pesado libro la poblacin
Alicante, y guindote por la cabecera de las pginas buscars los apellidos que empiezan por S
73
de Salazar. De esa forma localizars ms rpido el apellido Salazar. Pues bien, enhorabuena,
has estado usando un ndice.
Pues el objetivo de definir ndices en SQL Server es exactamente para conseguir el mismo
objetivo: acceder ms rpido a los datos. Adems SQL Server tiene dos tipos de ndices que
analizaremos a continuacin.
2.1.5.1. ndices agrupados
Los ndices agrupados, definen el orden en que almacenan las filas de la tabla (nodos
hoja/pgina de datos de la imagen anterior). La clave del ndice agrupado es el elemento
clave para esta ordenacin; el ndice agrupado se implementa como una estructura de
rbol b que ayuda a que la recuperacin de las filas a partir de los valores de las claves del
ndice agrupado sea ms rpida. Las pginas de cada nivel del ndice, incluidas las pginas
de datos del nivel hoja, se vinculan en una lista con vnculos dobles. Adems, el
desplazamiento de un nivel a otro se produce recorriendo los valores de claves.
2.1.5.1.1. Consideraciones
Columnas selectivas.
Columnas afectadas en consultas de rangos: BETWEEN, mayor que, menor que, etc.
Columnas accedidas "secuencialmente".
Columnas implicadas en JOIN, GROUP BY.
Acceso muy rpido a filas: lookups.
74
2.1.5.2. ndices no-agrupados
Los ndices no agrupados tienen la misma estructura de rbol b que los ndices agrupados,
con algunos matices; como hemos visto antes, en los ndices agrupados, en el ltimo nivel
del ndice (nivel de hoja) estn los datos; en los ndices no-agrupados, en el nivel de hoja
del ndice, hay un puntero a la localizacin fsica de la fila correspondiente en el ndice
agrupado. Adems, la ordenacin de las filas del ndice est construida en base a la(s)
columna(s) indexadas, lo cual no quiere decir (a diferencia de los ndices agrupados), que
la organizacin fsica de las pginas de datos corresponda con el ndice.
2.1.5.2.1. Consideraciones
Columnas con datos muy selectivos
Consultas que no devuelven muchas filas.
Columnas en WHERE.
Evitar acceso a pginas de datos realizando el acceso slo por el ndice.
Covered queries (consultas cubiertas).
En SQL Server 2005, son nuevos los ndices INCLUDE que son ndices no-agrupados que
en el nivel de hoja del ndice (donde est el puntero al ndice agrupado), se puede
incluir ms columnas; el objetivo de este nuevo tipo de ndices es beneficiar el uso de
las consultar cubiertas para evitar que se acceda a la pgina de datos del ndice
agrupado.
75
2.2. Consultas sobre la base de datos
En esta leccin, conocers los conceptos bsicos para poder realizar consultas y modificaciones
sobre la base de datos. La leccin se dividir en dos partes: cmo realizar consultas de seleccin,
y cmo realizar consultas de modificacin.
Durante la primera parte de la leccin se introducirn distintas clusulas que a pesar de estar en
la seccin de consultas de seleccin, tambin sern vlidas para sentencias de modificacin; por
ejemplo, dentro de una operacin de borrado se podrn usar clusulas JOIN, WHERE, TOP, etc.
2.2.1. Consultas de seleccin
En esta leccin veremos mecanismos para recuperar informacin de la base de datos. Veremos
como elegir las columnas de las tablas a recuperar, y cmo aplicar distintos tipos de clusulas
como WHERE, JOIN, GROUP BY, y TOP. Adems veremos dos novedades de la versin 2005 de
SQL Server: funciones de Ranking, en las que se devuelve la posicin relativa de las filas
respecto al conjunto total, y Expresiones de tablas comunes que son una nueva funcionalidad
para implementar consultas de una forma si cabe ms sencilla, y a la ver aporta la posibilidad
de realizar consultas recursivas que hasta la versin 2000 no era posible.
2.2.1.1. Seleccin de columnas y clusula FROM
Usando la clusula FROM cuales son las tablas, vistas, funciones, tablas derivadas o
expresiones de tablas comunes que se utilizan en la instruccin SELECT.
A su vez, se deber indicar las columnas a recuperar de la consulta. Si se quiere recuperar
todas las columnas se puede usar el comodn * (astersco), aunque deberemos ser
cuidadosos con ello.
Como recomendacin, debers intentar ser lo ms selectivo posible en las columnas a
incluir en la clusula SELECT. Por qu razn? Recuerdas la estructura de los ndices? Si
deseamos todas las columnas de una tabla, estaremos "forzando" a SQL Server a acceder
al nivel de datos de las pginas (recuerda: abajo del todo), y estaremos limitando la
efectividad de los ndices diseados en las tablas.
El contrapunto de ste comentario es la parte de desarrollo, si generamos cdigo
"genrico" que recupera todas las columnas porque las columnas sern necesarias unas
veces si y otras no, estaremos penalizando el rendimiento del servidor SQL Server Express
pero estaremos ganando tiempo de desarrollo...
Para ejecutar una consulta desde SQL Server 2005 Management Studio Express,
conectaremos a la base de datos DemoMSDN, desde una de las opciones marcada en la
siguiente imagen en recuadro rojo:
76
A continuacin debers escribir el siguiente texto para rellenar unas cuantas filas en la
tabla clientes (veremos luego la sentencia INSERT):
INSERT Clientes SELECT 'Julia Herrera', 'Alicante';
INSERT Clientes SELECT 'Javier lvarez', 'Madrid';
Para ello, copia el texto en la ventana de texto, y pulsa F5, o el botn Execute para
ejecutar la sentencia.
Borra el texto de la sentencia, y escribe el siguiente texto:
SELECT Id AS Identificador, Nombre FROM Clientes;
Ejecuta la instruccin y vers como resultado todas las filas de la tabla Clientes. Fjate que
la columna de base de datos Id, ahora parece que se llama Identificador. Esto es un alias
de columna; habr ocasiones en las que necesites personalizar el nombre de columna que
se muestra.
77
Desde Management Studio, tambin se puede ver la informacin de la tabla de forma
similar a como se presenta en Access; para ello, debers seleccionar la tabla que quieres
editar, botn derecho del ratn, y elegir la opcin "Open Table" como aparece en la
siguiente imagen:
Y como resultado tendremos:
78
Debers tener cuidado con abrir tablas muy grandes, porque el proceso de carga es ms
costoso cuanto mayor sea el tamao de la tabla. Sin embargo, en la versin 2005 de las
herramientas administrativas, tenemos la posibilidad de cancelar consultas mientras se
est realizando la peticin; fjate en el botn marcado en color rojo en la siguiente imagen;
pulsando dicho botn se solicita al servidor que se cancele la consulta.
2.2.1.2. Clusula WHERE
La clusula WHERE se utiliza para aplicar filtros al conjunto de resultados; para ello existen
operadores lgicos AND, OR, NOT, EXISTS con los condicionantes <, >, =, y BETWEEN. No
hay lmite para el nmero de condiciones a establecer. El orden de prioridad de los
operadores lgicos es NOT, seguido de AND y OR. Se pueden utilizar parntesis para
suplantar esta prioridad en una condicin de bsqueda. El orden de evaluacin de los
operadores lgicos puede variar dependiendo de las opciones elegidas por el optimizador
de consultas.
Para ms informacin sobre los operadores lgicos, debes consulta la ayuda on-line del
producto:
http://msdn2.microsoft.com/es-es/library/ms203721(sql.90).aspx
2.2.1.3. Clusula JOIN
Cuando se necesita recuperar informacin de ms de una tabla, se suele especificar cuales
son las filas coincidentes entre ambas tablas (columnas Clave Ajena / Clave Primaria que
vimos en la leccin anterior). Para ello, hay una serie de operadores que condicionan dicho
filtro.
2.2.1.3.1. INNER JOIN
Especifica que se devuelvan todos los pares de filas coincidentes. Las filas no
coincidentes se descartan del resultado. Si no se especifica ningn tipo de combinacin,
ste es el tipo por defecto.
2.2.1.3.2. FULL [ OUTER ] JOIN
79
Especifica que una fila de la tabla de la derecha o de la izquierda, que no cumpla la
condicin de combinacin, se incluya en el conjunto de resultados y que las columnas
que correspondan a la otra tabla se establezcan en NULL.
2.2.1.3.3. LEFT [ OUTER ] JOIN
Especifica que todas las filas de la tabla izquierda que no cumplan la condicin de
combinacin se incluyan en el conjunto de resultados, con las columnas de resultados
de la otra tabla establecidas en NULL, adems de todas las filas devueltas por la
combinacin interna.
2.2.1.3.4. RIGHT [OUTER] JOIN
Especifica que todas las filas de la tabla derecha que no cumplan la condicin de
combinacin se incluyan en el conjunto de resultados, con las columnas de resultados
de la otra tabla establecidas en NULL, adems de todas las filas devueltas por la
combinacin interna.
2.2.1.3.5. ON <search_condition>
Especifica la condicin en la que se basa la combinacin; se puede referenciar ms de
una columna, por ejemplo, tablas con claves primarias compuestas.
Un ejemplo de consulta podra ser el siguiente:
SELECT
sh.SalesOrderID,
sh.OrderDate,
sh.CustomerID,
sd.OrderQty,
sd.ProductID,
sd.UnitPrice
FROM Sales.SalesOrderHeader sh
INNER JOIN Sales.SalesOrderDetail sd
ON sh.SalesOrderID = sd.SalesOrderID
2.2.1.4. Clusula GROUP BY
El lenguaje T-SQL permite devolver la informacin agregada usando la clusula GROUP BY;
los condicionantes de la agregacin se colocan despus de la clusula. Existen las
siguientes funciones de agregado:
AVG, MIN, CHECKSUM, SUM, CHECKSUM_AGG, STDEV, COUNT, STDEVP, COUNT_BIG, VAR,
GROUPING, VARP, MAX.
Por ejemplo, la siguiente sentencia T-SQL devolvera la cantidad de productos pedidos por
cliente en la base de datos MSDN:
SELECT Id, COUNT(*) AS Cantidad
FROM Pedido
GROUP BY Id
En SQL Server 2005, se pueden disear funciones de agregado personalizadas con
lenguajes .NET como Visual Basic o C#; para ello deber implementar el mtodo de
agregacin siguiendo unas "reglas" que define SQL Server (interfaces, mtodo de
acumulacin, funciones varias, etc.), compilarlo, incluirlo en la base de datos con la
sentencia (CREATE ASSEMBLY), y hacerlo referencia con la funcin T-SQL CREATE
AGGREGATE.
2.2.1.5. Clusula TOP (n) [PERCENT]
Cuando se necesita recuperar los n primeros elementos que cumplen una condicin, se
puede utilizar la funcin TOP. La funcin TOP tiene un argumento que puede representar un
nmero o un porcentaje.
80
La nica forma de garantizar que la sentencia TOP devuelva los n primeros elementos que
cumplen una condicin es usando la clusula ORDER BY.
Adems, SQL Server 2005, incorpora nuevas funciones de RANKING que devuelven
posiciones relativas de las filas; las funciones son RANK, DENSERANK, TILE , y NTILE.
2.2.1.6. Expresiones de tablas comunes (CTE)
Las expresiones de tablas comunes son una de las novedades en el lenguaje T-SQL en la
versin 2005; representan un conjunto temporal de datos, al que se puede hacer referencia
varias veces en la sentencia en la que est incluida. Su mbito es la sentencia en la que se
ejecuta, y puede utilizarse en sentencias SELECT, INSERT, UPDATE, y DELETE. Adems,
tambin puede ser incluida en procedimientos almacenados, y en la definicin de vistas.
Su sintaxis es:
[ WITH <common_table_expression> [ ,...n ] ]
<common_table_expression>
::=
expression_name [ ( column_name [ ,...n ] ) ]
AS
( CTE_query_definition )
Aprovechando la consulta anterior, un ejemplo de CTE podra ser el siguiente:
WITH PedidosAgrupados (Id, Cantidad) AS
(SELECT Id, COUNT(*) AS Cantidad FROM Pedidos GROUP BY Id)
SELECT Id, Nombre
FROM Clientes
INNER JOIN PedidosAgrupados
ON Clientes.Id = PedidosAgrupados.I
2.2.2. Consultas de modificacin
2.2.2.1. Sentencia INSERT
La sentencia INSERT, inserta filas en una tabla; tiene dos formatos:
INSERT INTO <tabla> VALUES ( <lista de columnas> )
En la que se insertan la lista de valores en una tabla; corresponde a una insercin de una
fila en la tabla.
INSERT INTO <tabla> <sentencia select>
Donde la sentencia select ser un conjunto de filas que se insertar en la tabla destino.
Cuando una de las columnas de la tabla tenga establecida la propiedad IDENTITY, no ser
necesario especifica el valor de la columna porque SQL Server automticamente lo har por
nosotros. En realidad, si se intenta insertar un valor, se generar una excepcin porque la
propiedad IDENTITY, no admite especificar valores para las columnas a menos que se use
la opcin SET IDENTITY_INSERT.
La sentencia INSERT se puede utilizar en combinacin con las expresiones de tablas
comunes; adicionalmente, existe una opcin (OUTPUT), que devuelve Cuando una de las
columnas de la tabla tenga establecida la propiedad IDENTITY, no ser necesario especifica
el valor de la columna porque SQL Server automticamente lo har por nosotros. En
realidad, si se intenta insertar un valor, se generar una excepcin porque la propiedad
IDENTITY, no admite especificar valores para las columnas a menos que se use la opcin
SET IDENTITY_INSERT.
81
2.2.2.2. Sentencia UPDATE, y DELETE
La sentencia UPDATE/DELETE, actualizan/borran filas de una tabla. Normalmente se le
aplican filtros a la sentencia para que filtre las filas que se van a modificar. Se puede hacer
la operacin UPDATE/DELETE de dos formas, que explicaremos con un ejemplo:
DELETE Sales.SalesOrderDetail
WHERE SalesOrderID = 3443
En el que se borran las filas de la tabla Sales.SalesOrderDetail cuyo identificador es el
3443.
La otra posibilidad es hacer la operacin con un JOIN (no todos los gestores de bases de
datos lo permiten); el ejemplo sera el siguiente:
UPDATE t
SET AcumuladoImporte = t2.SumaImporte
FROM TablaAcumulados t
INNER JOIN
(SELECT Pedidos.Id, SUM (LineasPedido.Importe) AS SumaImporte
FROM Pedidos
JOIN LineasPedido ON Pedidos.Id = LineasPedido.Id Pedidos.Fecha
BETWEEN '20050101' AND '20060101'
GROUP BY Pedidos.Id) t2
ON t.Id = t2.Id
WHERE Fecha BETWEEN '20050101' AND '20060101'
Para leer esta consulta es mejor que empieces por el final; mira la consulta que representa
el alias t2: obtiene los en importe total de cada pedido del ao 2005.
A continuacin, ese resultado se va a cruzar (JOIN) con la tabla TablaAcumulados para
actualizar la columna AcumuladoPedidos, reemplazndolo por el valor de SumaImporte de
la consulta anterior. Antes de aplicarlo, deber acotar la actualizacin a los pedidos
realizados en el ao 2005.
Las sentencias DELETE, y UPDATE tambin pueden usar la opcin (OUTPUT), para devolver
las filas afectadas por la operacin. Puedes consultar los libros en pantalla on-line del
producto en:
http://msdn2.microsoft.com/es-es/library/ms203721(sql.90).aspx
82
3. Programacin de una base de datos
3.1. Procedimientos almacenados
Los procedimientos almacenados (stored procedures) no son mas que una sucesin ordenada de
instrucciones T-SQL que pueden recibir y devolver parmetros provistos por el usuario y se
pueden guardar en el servidor con un nombre, para luego poder invocarlos y ejecutarlos. En esta
nueva versin (2005), tambin es posible utiliza procedimientos almacenados usando CLR. Un
procedimiento almacenado CLR es una referencia a un mtodo de un ensamble de .NET
Framework que puede aceptar y devolver parmetros suministrados por el usuario.
3.1.1. Algunas ventajas de usar procedimientos almacenados
3.1.1.1. Compilacin
La primera vez que se invoca un procedimiento almacenado, el motor lo compila y a partir
de ah, se sigue usando la versin compilada del mismo, hasta que se modifique o se
reinicie el servicio de SQL. Esto hace que tengan un mejor rendimiento que las consultas
directas que usan cadenas con instrucciones T-SQL, que el motor compila cada vez que se
invoca.
3.1.1.2. Automatizacin
Si tenemos un conjunto de instrucciones T-SQL que queremos ejecutar en un orden, los
stored procedures son el espacio ideal para hacerlo.
3.1.1.3. Administracin
Si hacemos buen uso de los procedimientos almacenados, muchas veces algn cambio en
nuestra aplicacin, solo implica modificar un stored procedure y no toda la aplicacin. Si
nuestra aplicacin llama a los stored procedures, con solo cambiarlo en el servidor, ya
tenemos todo funcionado sin la necesidad de actualizar la aplicacin en todos los equipos
cliente.
3.1.1.4. Seguridad
Otra ventaja que tienen es que permiten aplicar un esquema de seguridad mas potente,
haciendo que los usuarios que usen nuestra aplicacin, solo tengan permisos para ejecutar
procedimientos almacenados y no a todos los objetos de la base. De esta forma si un
hacker encuentra una vulnerabilidad (SQL Injection) en nuestra aplicacin, no podr
explotarla ejecutando comandos SQL directamente sobre la base, ya que el usuario con el
cual se ejecuta la aplicacin solo tiene derecho a la ejecucin de los procedimientos
almacenados en la base de datos.
3.1.1.5. Programabilidad
Los procedimientos almacenados admiten el uso de variables y estructuras de control como
IF, Bucles, Case, etc.. adems de el manejo de transacciones, que permiten que los stored
procedures sean aplicables para escribir lgica del negocio en los mismos. Depende el
modelo de programacin que se utilice esto puede ser tanto una buena practica como una
mala practica, pero la posibilidad de incluir las reglas del negocio en los mismos existe.
Como explicbamos mas arriba a partir de esta versin de SQL (2005), podemos utilizar
CLR esto es (cualquier leguaje .NET como C# o Visual Basic) para escribir los stored
procedures (adems del tradicional T-SQL).
3.1.1.6. Trafico de Red
Pueden reducir el trfico de la red, debido a que se trabaja sobre el motor (en el servidor),
y si una operacin incluye hacer un trabajo de lectura primero y en base a eso realizar
algunas operaciones, esos datos que se obtienen no viajan por la red.
83
3.1.2. Crear procedimientos almacenados
Para crear un procedimiento almacenado es necesario ejecutar la instruccin CREATE
PROCEDURE, como se muestra en el ejemplo:
CREATE PROCEDURE Clientes_GetAll
AS
SELECT Id, Nombre FROM dbo.Clientes
Si el procedimiento almacenado ya existe se debe usar la instruccin ALTER PROCEDURE, de la
misma manera que si se estuviera creando. En el ejemplo, el stored procedure devuelve todos
los registros de la tabla Clientes.
La creacin de procedimientos almacenados basados en .NET Framework lo veremos en la
leccin 4 del mdulo 4 (Conceptos avanzados -- Integracin del CLR).
3.1.3. Ejecutar procedimientos almacenados
La ejecucin de los procedimientos almacenados es muy simple. Desde T-SQL hay que utilizar
la instruccin EXEC, para ejecutar los dos procedimientos almacenados que creamos arriba
debera escribirse esto:
EXEC Clientes_GetAll
Y cmo se hara la llamada desde una aplicacin .NET?; para ello deberemos definir un objeto
conexin que conecta a la base de datos, y un objeto command que ejecute el comando:
'Creamos una nueva conexin.
Dim myConn As SqlClient.SqlConnection = New
SqlClient.SqlConnection("Data Source=(localhost)\SQLEXPRESS;Initial
Catalog=DemoMSDN;Integrated Security=True")
'Creamos un nuevo comando
Dim myComm As SqlClient.SqlCommand = New SqlClient.SqlCommand()
'Le asignamos la conexion.
myComm.Connection = myConn
'especificamos que el comando es un stored procedure
myComm.CommandType = CommandType.StoredProcedure
'y escribimos el nombre del stored procedure a invocar
myComm.CommandText = "Clientes_GetAll"
'Creamos un nuevo DataAdapter con nuestro comando.
Dim myDA As SqlClient.SqlDataAdapter = New
SqlClient.SqlDataAdapter(myComm)
'Creamos un dataset para soportar los datos devueltos por el stored
procedure
Dim ClientesDs As DataSet = New DataSet
'Pedimos al Data Adapter que llene el dataset (Esto llama a nuestro
comando)
myDA.Fill(ClientesDs)
'Y lo mostramos por pantalla
For Each row As Data.DataRow In ClientesDs.Tables(0).Rows
Console.WriteLine(row!Id.ToString() + " " + row!Nombre)
Next
84
3.1.4. Argumentos en procedimientos almacenados
Los procedimientos almacenados pueden recibir y devolver datos a quien lo llame.
Supongamos que ahora necesitamos obtener una sola categora y no todas como el ejemplo
anterior. Podemos crear un nuevo stored procedure llamado Clientes_GetOne que reciba como
parmetro el Id y devuelva solo ese registro.
CREATE PROCEDURE Clientes_GetOne
@Id int
AS
SELECT Id, Nombre FROM dbo.Clientes
WHERE Id = @Id
Como se puede ver, ahora este stored procedure espera un parmetro que luego se usa para
hacer la consulta en el select.
Para llamar a este store procedure se usa la misma sintaxis pero solo agregando el valor del
parmetro. (En este caso, queremos obtener el registro cuyo Id = 4).
EXEC Clientes_GetOne 4
3.1.4.1. Desde ADO.NET
'Creamos una nueva conexin.
Dim myConn As SqlClient.SqlConnection = New
SqlClient.SqlConnection("Data Source=(localhost)\SQLEXPRESS;Initial
Catalog=DemoMSDN;Integrated Security=True")
'Creamos un nuevo comando
Dim myComm As SqlClient.SqlCommand = New SqlClient.SqlCommand()
'Le asignamos la conexion.
myComm.Connection = myConn
'especificamos que el comando es un stored procedure
myComm.CommandType = CommandType.StoredProcedure
'y escribimos el nombre del stored procedure a invocar
myComm.CommandText = "Clientes_GetOne"
'Creamos un nuevo parmetro
Dim myParam As SqlClient.SqlParameter = New SqlClient.SqlParameter()
myParam.ParameterName = "@Id"
myParam.SqlDbType = SqlDbType.Int
myParam.Value = 4
'Y se lo agregamos a la coleccion de parametros del comando
myComm.Parameters.Add(myParam)
'Creamos un nuevo DataAdapter con nuestro comando.
Dim myDA As SqlClient.SqlDataAdapter = New
SqlClient.SqlDataAdapter(myComm)
'Creamos un dataset para soportar los datos devueltos por el stored
procedure
Dim ClientesDs As DataSet = New DataSet
'Pedimos al Data Adapter que llene el dataset (Esto llama a nuestro
comando)
myDA.Fill(ClientesDs)
85
'Y lo mostramos por pantalla
For Each row As Data.DataRow In ClientesDs.Tables(0).Rows
Console.WriteLine(row!Id.ToString() + " " + row!Nombre)
Next
3.2. Triggers
Los TRIGGERS o disparadores son muy similares en su concepto a los procedimientos
almacenados, es decir son piezas de cdigo Transact-SQL, sin embargo son radicalmente distintas
en la ejecucin, mientras un procedimiento almacenado se ejecuta por la peticin de un cliente,
un TRIGGER responde a un evento, ya sea de manipulacin de datos como los TRIGGERS DML o
por la manipulacin de esquemas como los TRIGGERS DDL.
Los TRIGGERS son un tipo de objetos muy especiales en SQL Server 2005, ya que realmente son
muy parecidos a lo que las rutinas de atencin a eventos en cdigo en cualquier lenguaje de
programacin como por ejemplo .NET. Como objetos especiales que son tambin reciben
parmetros de una forma muy especial, en forma de unas tablas virtuales, llamadas inserted y
deleted. Estas tablas especiales (inserted y deleted) contienen la informacin de los registros que
se han eliminado o insertado, con exactamente las mismas columnas que la tabla base que est
sufriendo esa modificacin. Las tablas inserted y deleted estarn o no rellenas de datos en funcin
de cual sea el tipo de operacin que ha dado lugar a su ejecucin. Por ejemplo, un TRIGGER que
se dispare por la insercin en una tabla tendr tantos registros en la tabla virtual inserted como
registros estn siendo insertados y cero registros en la tabla deleted; un TRIGGER que se dispare
por la eliminacin de registros en una tabla tendr cero registros en la tabla inserted y tantos
registros en la tabla deleted como registros estn siendo eliminados, y un TRIGGER que responda
a una operacin de update, tendr el mismo nmero de registros en la tabla inserted y en la tabla
deleted que adems coincidir con el nmero de registros actualizados en la tabla que da lugar al
evento.
Uno de los errores ms comunes cuando se desarrollan TRIGGERS est relacionado con esta
arquitectura que acabamos de describir, un TRIGGER no se dispara una vez para cada fila
modificada, sino que se dispara una sola vez por cada operacin, independientemente del nmero
de registros afectados por la operacin, y todos los registros afectados estn contenidos en las
tablas inserted y deleted dentro del TRIGGER. Muchos desarrolladores parten de la premisa de
que las tablas inserted y deleted contendrn solamente un registro a lo sumo y como acabamos
de explicar esto no es cierto. El segundo error ms comn tiene que ver este primero y con el
rendimiento, muchos desarrolladores para solventar este problema crean cursores dentro de los
TRIGGERS, los cursores como tal estn fuera del alcance de este captulo, pero en general un
cursor dentro de un TRIGGER es casi un garanta de obtener problemas de rendimiento, por lo
que deberamos intentar evitarlos lo ms posible
Los TRIGGERS son usados para aadir lgica o restricciones a la base de datos, por ejemplo
pueden ser usados para establecer reglas de integridad con bases de datos externas (no grabar
un pedido en la base de datos de pedidos si el cliente indicado no est dado de alta en la base de
datos de pedidos por ejemplo); tambin son usados para mantener tablas de acumulados como
por ejemplo la tabla que mantienen el stock de una determinada compaa o para guardar el
acumulado de ventas en la ficha de un cliente.
DML es el acrnimo de Data Manipulation Language (Lenguaje de Manipulacin de datos), los
TRIGGERS DML son como indica su nombre aquellos que responden a operaciones de
manipulacin de datos, tales como sentencias INSERT, UPDATE o DELETE mientras que DDL es el
acrnimo de Data Definition Language (Lenguaje de definicin de datos) los TRIGGERS DDL se
dispararn por operaciones que impliquen cambios en los esquemas (en la definicin de los
objetos).
3.2.1. Triggers DML: INSTEAD OF
Los TRIGGERS de tipo Instead OF son TRIGGERS que se disparan en lugar de la operacin que
los produce, es decir, una operacin de borrado de registros con la instruccin delete sobre
86
una tabla que tiene un TRIGGER de tipo INSTEAD OF no se llega a realizar realmente, sino que
SQL Server 2005 cuando detecta esta operacin invoca al TRIGGER que es el responsable de
actuar sobre los registros afectados, en el ejemplo que estamos siguiendo, el TRIGGER sera el
responsable de borrar los registros de la tabla que ha disparado el evento. Si el TRIGGER no se
encarga de esta tarea, el usuario tendr la sensacin de que SQL Server no hace caso a sus
comandos ya que por ejemplo una instruccin DELETE no borrar los registros.
Como ejemplo de TRIGGER de tipo INSTEAD OF vamos a ver como se implementara la
siguiente regla: no se pueden borrar los clientes cuyo Crdito Total sea mayor que cero, sin
embargo si dentro de una operacin de borrado hay clientes con Riesgo Total cero y otros con
Riesgo Total distinto de cero, los que tengan cero si deben resultar eliminados. El TRIGGER
que implementara esa regla sera el siguiente.
CREATE TRIGGER TR_BorradoSelectivo on Clientes INSTEAD OF DELETE
AS
BEGIN
DELETE c
FROM Clientes C
INNER JOIN DELETED d ON C.idCliente = D.idCliente
WHERE C.CreditoTotal = 0
END
Repasando el cdigo podemos ve que estamos utilizando una sintaxis de JOIN para un
DELETE, esta sintaxis es perfectamente vlida y lo que har ser borrar todos los registros de
C (Clientes) que existan tambin en D (DELETED) uniendo estas tablas por el cdigo de cliente
en donde el Crdito Total sea 0. El resto de los registros solicitados para borrar (es decir todos
los que su campo crdito total no sea cero) simplemente no se borrarn, ya que como hemos
mencionado los triggers de tipo INSTEAD OF delegan la responsabilidad de la operacin en el
cuerpo del TRIGGER.
En algunos escenarios los TRIGGERS de tipo INSTEAD OF pueden usarse como mecanismo
para evitar operaciones no controladas en tablas, por ejemplo si queremos prevenir que se
borren datos de una tabla, basta con crear un INSTEAD OF TRIGGER y no poner ningn cdigo
en su cuerpo, de esta forma, a menos que el usuario deshabilite el TRIGGER, no podr borrar
ningn dato, sin embargo sea cuidadoso y documente bien este tipo de operaciones ya que
pueden dar la falsa sensacin de que la base de datos no se est comportando
adecuadamente.
3.2.2. Triggers DML: AFTER
Todos los TRIGGERS sirven en general para implementar restricciones de negocio avanzadas,
como ejemplo vamos a ver como se construira un TRIGGER que impidiese que se aumentase
el Crdito total de un cliente que tenga pagos pendientes, para ello vamos a suponer una tabla
de clientes con identificador idCliente y con un campo llamado CreditoTotal y una tabla de
recibos conteniendo el idCliente y el estado del recibo (estos son solamente los campos que
son relevantes para nuestro ejemplo).
CREATE TRIGGER TR_CompruebaCreditoTotal ON Clientes AFTER UPDATE
AS
BEGIN
IF UPDATE(CreditoTotal)
-- Se est actualizando el campo crdito total, comprobemos
-- las restricciones.
BEGIN
IF EXISTS(SELECT IdCliente FROM RECIBOS
WHERE Estado=PEN AND idCliente
IN (SELECT idCliente FROM DELETED))
BEGIN
ROLLBACK
87
-- Deshacemos la transaccin impidiendo que se
actualize
RAISERROR (No se pueden actualizar el crdito de
clientes con recibos pendientes,16,1)
END
END
END
Veamos algunas particularidades sobre el cdigo del TRIGGER, la clusula UPDATE, permite
comprobar si se est actualizando una columna en particular, de esta forma nuestro TRIGGER
resultar inocuo para el resto de operaciones de actualizacin. En la segunda parte se
comprueba que el cliente tenga recibos pendientes con una clusula EXISTS y con una clusula
in. La clusula IN permite comprobar que el cdigo de cliente est en la lista de cdigos de
cliente borrados (todos ellos), la clusula EXISTS permite comprobar si existen recibos
pendientes en esos clientes.
Algunos administradores de base de datos prefieren implementar estas reglas de negocio en
procedimientos almacenados e impedir el acceso de los usuarios directamente a la
modificacin de tablas. Ambas alternativas son perfectamente vlidas y el usar unas u otras
depender de las polticas que se establecen en el desarrollo. Lo que en cualquier caso suele
ser buena idea es manipular las restricciones de los datos en la base de datos, por que esta es
la nica forma de garantizar totalmente la consistencia de la informacin.
3.2.3. Triggers DDL: a nivel de base de datos
Los TRIGGERS DML (Data Manipulation Language) responden a la necesidad de garantizar la
integridad y consistencia de los datos dentro de nuestras tablas de usuario, sin embargo no
ayudan a mantener las reglas de diseo de nuestra base de datos. El nombre coincide pero el
propsito es distinto, los triggers DDL (Data Definition Language) nos proporcionarn
mecanismos para garantizar que nuestra base de datos est diseada e implementada de
acuerdo a los estndares que hayamos definido.
Los TRIGGERS DDL tienen dos alcances diferenciados, a nivel de servidor y a nivel de base de
datos. Estos alcances estn enlazados con el tipo de evento que los dispare, en esta primera
parte los eventos que vamos a ver son a nivel de Base de datos y algunos ejemplos de ellos
son:
CREATE / ALTER /DROP View
CREATE / ALTER /DROP Table
CREATE / ALTER /DROP Schema
Aunque hay muchos ms, relacionados con estadsticas, sinnimos, usuarios (no confundir con
logins que son a nivel de servidor), procedimientos, etc. Puede consultar los libros en pantalla
de SQL Server 2005 para obtener una relacin completa de todos los eventos a los que puede
responder.
Los TRIGGERS DDL tienen una particularidad adicional sobre los de tipo DML y es que no tiene
mucho sentido las tablas inserted y deleted ya que el tipo de operaciones que disparan los
triggers son radicalmente diferentes. Sin embargo, como ellos necesitan recibir informacin
acerca del evento que ha ocasionado que el trigger se dispare, para ello existe la funcin
EVENTDATA(), esta funcin devuelve un valor XML que responde al siguiente esquema:
<EVENT_INSTANCE>
<EventType>type</EventType>
<PostTime>date-time</PostTime>
<SPID>spid</ SPID>
<ServerName>name</ServerName>
<LoginName>name</LoginName>
<UserName>name</UserName>
88
<DatabaseName>name</DatabaseName>
<SchemaName>name</SchemaName>
<ObjectName>name</ObjectName>
<ObjectType>type</ObjectType>
<TSQLCommand>command</TSQLCommand>
</EVENT_INSTANCE>
Utilizando las funciones XML para manipular esa funcin podemos obtener toda la informacin
necesaria para crear TRIGGERS que garanticen que en nuestras bases de datos se siguen los
estndares marcados. Supongamos que uno de esos estndares indica que todas las tablas
deben estar documentadas, su propsito, la fecha de creacin etc en una tabla llamada
TablasDocumentadas, podramos crear un TRIGGER DDL a nivel de base de datos que nos
garantizase que antes de crear la tabla, sta, ya ha sido documentada. El cdigo que lo hace
es el siguiente:
CREATE TRIGGER TablasDocumentadas
ON DATABASE
FOR CREATE_TABLE
AS
BEGIN
DECLARE @TabName Sysname
SELECT
@TabName=EventData().value((/EVENT_INSTANCE/ObjectName)[1],sys
name)
IF NOT EXISTS(SELECT * FROM TablasDocumentadas
WHERE TableName = @TabName)
BEGIN
ROLLBACK
-- Deshacemos la transaccin impidiendo que se
actualize
RAISERROR (No se pueden crear tablas indocumentadas
en nuestro sistema,16,1)
END
END
Si lo miramos en detalle tan solo estamos obteniendo el nombre del objeto que se ha insertado
(en nuestro caso la tabla que se acaba de crear) y estamos comprobando que existe un
registro con ese nombre en la tabla TablasDocumentadas, sin embargo este procedimiento
podra tener mucha ms complejidad y garantizar no solamente que existe sino que los datos
que contiene esa tabla son de cierta calidad.
3.2.4. Triggers DDL: a nivel de servidor
Los triggers DDL a nivel de servidor son muy similares a los triggers a nivel de base de datos
en su concepcin, pero responden a los eventos que son propios del servidor y no a los que
estn en el alcance de base de datos. A esta categora de eventos pertenecen entre otros los
de CREATE LOGIN o CREATE/ALTER/DROP Database y los relativos por ejemplo a los nuevos
ENDPOINTS. Las utilidades de este tipo de TRIGGERS tambin estn muy alineadas con las de
los que son a nivel de base de datos e incluso la informacin
Como ejemplo de uso vamos a crear un TRIGGER que se encarge de garantizar que todos los
LOGINS comienzan con tres letras y un guin bajo, esto podra servir para organizarlos por
aplicaciones o por polticas de seguridad o por cualquier otro concepto.
CREATE TRIGGER LoginsConTresLetrasYGuionBajo
ON ALL SERVER
FOR DDL_LOGIN_EVENTS
AS
BEGIN
DECLARE @ObjName Sysname
89
SELECT
@ObjName=EventData().value((/EVENT_INSTANCE/ObjectName)[1],sys
name)
IF NOT @ObjName LIKE [A-Z][A-Z][A-Z][_]%
BEGIN
ROLLBACK
RAISERROR (Todos los logins deben comenzar por tres letras
y un guin bajo,16,1)
END
END
La clusula ON en la instruccin CREATE TRIGGER indica el alcance al que el trigger afectar,
ALL SERVER o bien DATABASE, el comando que se sita detrs de FOR, en el ejemplo
DDL_LOGIN_EVENTS puede indicar un evento o un grupo de eventos a los que se responder,
en nuestro caso es un grupo de eventos, en concreto todos los relacionados con LOGIN.
3.3. Funciones definidas de usuario
Una herramienta adicional dentro de la programacin de base de datos son las funciones definidas
por el usuario. Estas funciones, que pueden ser de tres tipos, reciben parmetros como los
procedimientos almacenados, y adems pueden ser usadas como valores escalares o como tablas
dentro de clusulas FROM, lo que las hace tremendamente tiles en determinadas circunstancias.
3.3.1. Funciones escalares
Las funciones escalares son aquellas que devuelven un nico valor en funcin de los
parmetros que reciben. Pueden servir en mltiples circunstancias haciendo de la
programacin una experiencia ms agradable. Un ejemplo de funcin escalar podra ser la
siguiente:
CREATE FUNCTION Rangos (@id tinyint)
RETURNS nvarchar(10)
AS
BEGIN
DECLARE @Valor nvarchar(10)
SELECT @Valor = CASE WHEN @id<20 THEN '1-19'
WHEN @id>=20 AND @id<40 THEN '20-39'
WHEN @id>=40 AND @id<60 THEN '40-59'
WHEN @id>=60 AND @id<80 THEN '60-79'
WHEN @id>=80 AND @id<100 THEN '80-99'
ELSE '>100'
END
RETURN @Valor
END
Esta funcin devolver un string que contiene el rango al que pertenece el nmero que recibe
como parmetro.
Desde las funciones se puede acceder a tablas tambin, pero siempre cuando se hace hay que
ser muy cuidadoso para no implementar lo que se llaman lookups dentro de las udfs por que
eso puede ser muy peligroso para el rendimiento ya que por cada fila devuelta se ejecutar
una sentencia sin que el optimizador de consultas pueda hacer nada para mejorar la forma de
ejecutarse.
3.3.2. Funciones de tabla en lnea
Las funciones de tabla en lnea son muy parecidas a las vistas, con la excepcin de que
admiten parmetros de tal forma que pueden resultar tremendamente tiles en determinadas
circunstancias. Veamos un ejemplo:
CREATE FUNCTION ClientesPorTipo (@Tipo tinyint)
RETURNS TABLE
90
AS
RETURN (SELECT * FROM Clientes WHERE Tipo = @tipo)
Esta funcin puede ser usada en sentencias ms complejas, un ejemplo de uso podra ser el
siguiente:
SELECT * FROM ClientesPorTipo(1) Cl
INNER JOIN Facturas F ON CL.idcliente = F.IdCliente
De esta forma podemos parametrizar consultas que vamos a usar en clusulas FROM, de esta
forma escribir cdigo T-SQL resulta ms sencillo y el resultado es ms comprensible. Si
adems combinamos esta funcionalidad con las nuevas funciones APPLY podemos obtener
funcionalidades an ms interesantes, ya que podemos conseguir que las funciones en lnea o
de tipo tabla reciban los parmetros desde los valores de otra tabla, la sintaxis sera algo as:
SELECT * FROM ClientesSeleccionados C
CROSS APPLY ClientesPorTipo(C.tipo)
Esta consulta devolver todos los registros de la tabla Clientes Seleccionados y los regritros de
la vista ClientesPortipo para cada Tipo de la tabla primaria.
3.3.3. Funciones de tabla multi-sentencia
Sin embargo, algunas veces necesitamos cierta manipulacin de la informacin dentro de las
funciones para poder devolver los datos tal y como necesitamos, esto puede hacerse tambin
dentro de las funciones definidas por el usuario en las llamadas funciones de tabla o funciones
de tabla multi-sentencia. Bsicamente se comportan igual que un procedimiento almacenado
pero devuelven una tabla que puede ser usada en clusulas FROM o ser usadas como veamos
anteriormente combinadas con funciones APPLY.
Un ejemplo de funcin de tabla multisentencia puede ser el siguiente:
CREATE FUNCTION ClientesPorTipoConSaldos (@Tipo tinyint)
RETURNS @T TABLE (idCliente Int, NombreCliente nvarchar(100), Saldo
money)
AS
BEGIN
INSERT INTO @t (idCliente, NombreCliente) SELECT idCliente,Nombre
FROM Clientes WHERE Tipo = @Tipo
UPDATE T
SET Saldo = Total
FROM @T T
INNER JOIN (SELECT idCliente, SUM(Saldo) Total
FROM Recibos
GROUP BY idCliente) S
ON T.idCliente = S.idCliente
RETURN
END
Esta funcin se encarga de devolver todos los clientes por tipo, pero adems les aporta el
Saldo en su cuenta sumando los recibos. Toda esta funcionalidad puede ponerse en una sola
sentencia, pero de esta forma queda mucho ms clara para el ejemplo. Cualquier manipulacin
sobre la variable de tipo tabla @t podra ser hecha dentro del cuerpo de la funcin que se
comportara igual que un procedimiento almacenado, estando precompilada y pudiendo
reaprovechar los planes de la ejecucin en determinadas circunstancias.
Nota: Las funciones definidas por el usuario son una magnfica herramienta de programacin,
pero no son tiles para todas las circunstancias, simplemente cada vez que necesite realizar
una implementacin piense en que recurso es el ms adecuado para resolver la problemtica
que se le presenta y selo.
91
4. Conceptos avanzados
En este mdulo se vern las novedades relativas a seguridad en SQL Server 2005 Express;
adems daremos un repaso por los niveles de aislamiento, y conoceremos en qu consiste el
nuevo nivel de aislamiento de instantnea introducido en esta nueva versin. Para finalizar el
curso, veremos dos novedades importantes: el soporte nativo de XML, y la integracin del CLR en
SQL Server. En qu consiste la integracin del CLR? Pues bsicamente que desde la versin
2005, se pueden crear objetos tales como procedimientos almacenados, funciones, etc. con un
lenguaje orientado a objetos como VB.NET, o C#.
4.1. Seguridad
La Arquitectura de seguridad es uno de los aspectos que ms cambios ha sufrido y en el que ms
mejoras se han introducido en SQL Server 2005. En el presente apartado veremos los aspectos
bsicos de seguridad que ser necesario tener en cuenta a la hora de acceder a una base de datos
SQL Server Express.
4.1.1. Seleccionar un Modo de Autenticacin
SQL Server 2005 soporta dos modos de autenticacin, tal y como vimos en el apartado de
instalacin: Autenticacin Windows y Autenticacin Mixta. Cuando trabajamos en modo
Autenticacin Windows, que es el predeterminado y aconsejado, solo los usuarios autorizados
de sistema operativo podrn conectarse al servidor SQL Server. En el modo de Autenticacin
Windows, podemos proporcionar acceso tanto a usuarios, como a grupos de sistema operativo.
Para cambiar el Modo de Autenticacin, una vez instalada la instancia de SQL Server Express,
lo ms sencillo es utilizar la herramienta SQL Server Management Studio Express. Para ello
debes de seguir los siguientes pasos como muestra la figura:
1. Inicia SQL Server Management Studio Express desde el Men Inicio.
2. Desde el Object Explorer, haz clic con el botn de la derecha en la instancia y selecciona
Propiedades.
3. Desde la pestaa de Security podrs modificar el Modo de Autenticacin.
92
Nota: Para que este cambio surta efecto debers de reiniciar el servicio de SQL Server.
Para decidir que Modo de Autenticacin es el ms conveniente, debers de tener en cuenta:
El Modo de Autenticacin Windows es el ms seguro y el recomendado. En este modo de
Autenticacin, SQL Server confa en la autenticacin realizada por el Sistema Operativo. En
el Modo de Autenticacin Windows no viajan contraseas por la red, ni ser necesario
especificarlas en una cadena de conexin.
El Modo de Autenticacin Mixto deberemos de utilizarlo nicamente en aquellos casos en
los que, por la estructura de nuestra red, no podamos utilizar autenticacin Windows.
4.1.2. Acceso a una Base de Datos SQL Server
SQL Server utiliza una autenticacin en dos pasos: En primer lugar, la cadena de conexin
especifica una autenticacin a nivel de Instancia de SQL Server Express. Una vez se ha
autenticado el inicio de sesin, se comprueba si ese inicio de sesin tiene acceso a la base de
datos a la que se pretende acceder. Para ello, SQL Server mantiene una asociacin entre Inicio
de Sesin a nivel de Instancia y Usuario a nivel de Base de Datos.
4.1.2.1. Crear Inicios de Sesin
El primer paso, para proporcionar acceso a una Base de Datos es crear un inicio de sesin
para el usuario que necesita el acceso. Podemos crear dos tipos de inicio de sesin: Inicio
de Sesin Windows (usuarios o grupos) e Inicios de Sesin SQL Server (que solo podrn
crearse en Autenticacin Mixta).
Para crear un Inicio de Sesin Windows:
CREATE LOGIN [EXPRESS\Usuario] FROM WINDOWS
93
En este ejemplo EXPRESS hace referencia al nombre de Dominio o Equipo en el que est
instalado SQL Server Express y Usuario hace referencia a un usuario de Sistema Operativo.
Nota: Para que el anterior ejemplo funcione correctamente es necesario que el usuario
Usuario exista a nivel de Sistema Operativo.
Para crear un Inicio de Sesin SQL Server:
CREATE LOGIN SQLUser WITH PASSWORD = 'Pa$$w0rd'
Tambin podemos utilizar SQL Server Management Studio Express. En Object Explorer,
despliega la Instancia, despliega la carpeta de Security y haz clic en Logins. Si haces clic
con botn de la derecha, New Login En la figura puedes ver el cuadro de dilogo.
4.1.2.2. Crear Usuarios de Base de Datos
Una vez hemos creado el Inicio de Sesin para poder acceder a la instancia, debemos de
proporcionar acceso a ese Inicio de Sesin a la base de datos deseada. Para ello deberemos
de crear un usuario en la base de datos y asociarlo al inicio de sesin. El siguiente cdigo
es un ejemplo de este proceso, en el que estamos proporcionando acceso al Inicio de
Sesin [EXPRESS\Usuario] a la base de datos DemoMSDN:
USE DemoMSDN
GO
CREATE USER Usuario FOR LOGIN [EXPRESS\Usuario]
Desde SQL Management Studio podemos realizar esta operacin de de formas. Desde las
Propiedades del Inicio de Sesin o en la base de datos, creando un usuario. LA forma ms
sencilla es realizarlo desde las propiedades del Inicio de Sesin. Para ello en las
94
propiedades de un Inicio de Sesin vete a la opcin de User Mapping y selecciona las bases
de datos a las que quieres proporcionar acceso. La siguiente figura muestra dicha opcin:
4.1.3. Esquemas de Base de Datos
SQL Server 2005 introduce el concepto ANSI de Esquema, a travs del cual podemos agrupar
los objetos de base de datos, tablas, vistas, procedimientos almacenados, etc., siguiendo el
criterio que mejor se adecue a nuestras necesidades. El nombre de esquema formar parte del
nombre completo de los objetos que pertenecen a dicho esquema. Por ejemplo, si creamos un
Esquema denominado Ventas, y dentro de l una tabla denominada Pedidos, deberemos de
calificar la tabla utilizando el nombre del esquema, al estilo Ventas.Pedidos. Otra de las
grandes ventajas del uso de Esquemas, es que podremos asignar permisos a este nivel, en
lugar de tener que asignar permisos a los diferentes objetos de forma individual. Las
siguientes sentencias ilustran este ejemplo
USE MASTER
GO
-- Creamos un Inicio de Sesin de SQL Server
CREATE LOGIN Alumno WITH PASSWORD = 'Pa$$w0rd'
GO
-- Creamos una Base de Datos para pruebas
CREATE DATABASE TestDB
GO
-- Nos conectamos a la Base de Datos
USE TestDB
GO
-- Creamos el Schema Ventas
CREATE SCHEMA Ventas
95
GO
--Creamos la Tabla Pedidos en el Esquema Ventas
CREATE TABLE Ventas.Pedidos (idPedido int primary key, FechaPedido
smalldatetime, idCliente int, Estado tinyint)
GO
-- Creamos el usuario alumno enlazado con el Inicio de Sesin Alumno
CREATE USER Alumno FOR LOGIN Alumno
GO
-- Otorgamos el permiso de Select al usuario Alumno sobre el Esquema
Ventas.
GRANT SELECT ON SCHEMA::Ventas TO Alumno
Nota: Para ejecutar este ejemplo, la instancia de SQL Server Express debe de estar
ejecutndose en modo Autenticacin Mixta.
4.2. Niveles de aislamiento
Cuando trabajamos con bases de datos tenemos que tener en cuenta que no estamos solos, es
decir hay ms usuarios accediendo a los mismos datos, y manipulando los mismos datos. Esta
concurrencia ha de ser administrada por los sistemas gestores de base de datos, dotando a las
bases de datos de las cuatro caractersticas ACID, es decir Atomicidad, dentro de una transaccin
las operaciones que se realizan deben poder considerarse como una sola; C. Consistencia,
cualquier operacin que sea validada o cancelada no puede dejar datos inconsistentes (por
ejemplo violando reglas de integridad referencial). I (Isolation en ingls) Aislamiento, El gestor de
la base de datos debe aislar los datos 'sucios' para evitar que otros usuarios usen informacin no
confirmada o validada. D. Durabilidad, los datos confirmados no pueden perderse.
4.2.1. Niveles de aislamiento
Si nos detenemos en la definicin de aislamiento podemos observar que no es muy concreta,
es decir que da lugar a distintas interpretaciones o implementaciones de ese aislamiento. Esos
niveles y exactamente lo que significa el aislamiento es lo que vamos a tratar en los siguientes
apartados.
4.2.1.1. READ UNCOMMITED
Lecturas no confirmadas, realmente lo que sucede en este nivel de aislamiento es que los
usuarios pueden leer datos que an no estn confirmados, y que por tanto pueden llegar a
no existir nunca. Los problemas que presenta este nivel de aislamiento son los siguientes:
Lecturas sucias: Lee datos que no han llegado a validarse.
Lecturas no repetibles: Dos sentencias SELECT iguales y consecutivas podran devolver
datos diferentes.
Datos fantasmas: En dos sentencias SELECT iguales y consecutivas podran aparecer y
desaparecer filas.
Hay que ser muy cuidadoso si se utiliza este nivel de aislamiento ya que podra hacer que
los usuarios se basen en datos que realmente no han existido nunca y que por tanto son
errneos. En muchas ocasiones se usa para evitar bloqueos, si as lo hacemos hemos de
estar seguros que las consecuencias son admisibles.
4.2.1.2. READ COMMITED
Lecturas confirmadas, este es el nivel de aislamiento por defecto en SQL Server, no lee
datos que no estn confirmados, sino que esperara (se quedara bloqueado) a que esos
datos estn confirmados. Los bloqueos que establece mientras se lee informacin, tan solo
permanecen activos durante el tiempo de la ejecucin no durante toda la transaccin y no
se ve bloqueado por lecturas. Los problemas que tiene este nivel de aislamiento son:
Lecturas no repetibles: Dos sentencias SELECT iguales y consecutivas podran
devolver datos diferentes.
96
Datos fantasmas: En dos sentencias SELECT iguales y consecutivas podran aparecer
y desaparecer filas.
En este nivel de aislamiento las lecturas solo se ven bloqueadas por las escrituras, y las
escrituras rara vez se ven bloqueadas por lecturas y adems solo durante un muy corto
periodo de tiempo de tal forma que no suelen producirse muchos interbloqueos.
4.2.1.3. REPETEABLE READ
Lecturas repetibles. Este nivel de aislamiento garantiza que dos select consecutivas dentro
de una transaccin devolvern la misma informacin, y lo hace creando bloqueos
compartidos sobre los registros que lee de tal forma que no pueden ser modificados. El
nico problema que presenta es:
Datos fantasmas: En dos sentencias SELECT iguales y consecutivas podran aparecer
filas.
En este nivel de aislamiento las lecturas solo se ven bloqueadas por las escrituras, pero las
escrituras se ven bloqueadas por lecturas durante el tiempo que dura la transaccin que lee
de tal forma que es ms frecuente encontrar problemas de bloqueos.
4.2.1.4. SERIALIZABLE
Serializable. Este nivel de aislamiento no tiene ni siquiera el problema de datos fantasma,
por que cuando realiza un select crea bloqueos compartidos no solamente sobre los
registros que existen sino sobre los nuevos que pudiesen llegar (inserts) de tal forma que
dos instrucciones select consecutivas dentro de la misma transaccin devolvern
exactamente los mismos datos. En muchas ocasiones los desarrolladores eligen este nivel
por que es lo ms parecido a estar solo en el sistema, sin embargo este nivel de
aislamiento necesita crear un nmero considerable de bloqueos para poder garantizar estas
lecturas repetibles evitando datos fantasma.
En este nivel de aislamiento las lecturas solo se ven bloqueadas por las escrituras, pero las
escrituras se ven bloqueadas por lecturas incluso escrituras de tipo INSERT que en el nivel
de aislamiento REPEATABLE READ no se veran afectas.
Este es el nivel mximo de aislamiento y tambin genera el nivel mximo de bloqueos,
analice si realmente necesita estas caractersticas antes de usarlo.
4.2.2. Nuevo nivel de aislamiento de instantnea
El nuevo nivel de aislamiento de instantnea (el SNAPSHOT Isolation Level), cumple los
mismos requisitos que el serializable es decir no tiene ninguno de los problemas de lecturas
sucias, ni lecturas no repetibles ni lecturas fantasma, pero no se basa en una estrategia de
bloqueo para conseguirlo sino en una estrategia de versiones de las filas. Esta estrategia
permite evitar todos los problemas descritos, sin necesidad de bloquear las filas, de tal forma
que una sentencia SELECT devolver exactamente los mismos datos cada vez que se ejecute.
Dentro de estos nuevos niveles de aislamiento existen dos versiones, el propiamente llamado
SNAPSHOT ISOLATION y el READ COMMITTED SNAPSHOT.
Para habilitarlos debemos usar el comando:
ALTER DATABASE <Base de Datos> SET ALLOW_SNAPSHOT_ISOLATION ON o
ALTER DATABASE <Base de Datos> SET READ_COMMITTED_SNAPSHOT ON
El nivel de aislamiento de instantneas puede mostrar conflictos en actualizaciones, el motivo
es sencillo, si las sentencias select devuelven siempre la misma informacin pero no han
impedido que otros usuarios cambien la informacin, en el momento en que la transaccin
actual vaya a cambiar algn dato, debe comprobar que los datos que estn validados en la
base de datos son los mismos que existan cuando fueron ledos y versionados la primera vez,
en caso contrario podramos sobrescribir modificaciones de otros usuarios pero basados en
datos que ya no existen.
97
Nota: Como el lector habr podido observar no hay un nivel de aislamiento perfecto para
todas las situaciones, sino que cada uno presenta ventajas e inconvenientes diferentes, lo
importante en este caso es ser capaz de entender como funciona cada uno de ellos y poder
elegir el ms adecuado para la problemtica que estemos resolviendo.
4.3. Soporte XML
SQL 2005 aporta el nuevo tipo de datos XML nativo; ste nuevo tipo de datos puede formar parte
de columnas de una tabla, ser una variable, o ser argumento de un procedimiento almacenado;
antes de seguir adelante, debers quitarte la idea de que por el hecho de que el XML se
represente como una cadena de caracteres, internamente vaya ser guardado como texto: SQL
Server 2005 lo guardar internamente en formato binario, siendo su acceso ms efectivo y
teniendo la posibilidad de definir la estructura de los datos de manera ms eficiente. Por qu
esto? Parece que no est de acuerdo con W3C? Pues no es as W3C se encarga de definir la
estructura del lenguaje XML, no la estructura de su almacenamiento.
4.3.1. Tipo de datos XML
El tipo de datos xml permite almacenar documentos y fragmentos XML en SQL Server. Desde
la versin 2005, se pueden crear columnas y variables de tipo xml y almacenar instancias XML
en las mismas. Como nica limitacin el tamao de la columna XML puede ser superior a 2 GB.
Tambin se puede asociar una coleccin de esquemas XML con una columna, un parmetro o
una variable del tipo de datos XML. Los esquemas de la coleccin se utilizan para validar y
asignar un tipo a las instancias XML. En este caso, se dice que el XML tiene un tipo. En caso de
no estar validado contra un esquema XML, la implementacin de XML en SQL Server garantiza
que la columna est bien formada ("well-formed") ( http://www.w3.org/TR/REC-xml/#sec-
well-formed ).
Empezaremos con las columnas XML sin validar contra ningn esquema XML.
4.3.1.1. XML Nativo
El tipo de datos XML nativo, es un tipo de datos de SQL Server al igual que lo es int, char,
varchar, o bigint. Con este tipo de datos, se pueden crear variables, o columnas para
tablas. Un ejemplo de cmo crear una columna de tipo XML en una tabla sera lo siguiente:
CREATE TABLE EjemploXML (id int, valor xml)
Para insertar una fila en la tabla, podremos hacerlo a travs de un valor tipo tabla, o
podremos usar un valor de tipo caracter que se convierta de manera explcita a tipo xml:
-- conversin explcita
insert EjemploXML values (1, cast('<pedido cliente="1">1</pedido>' as
xml))
-- conversin implcita
insert EjemploXML values (2, '<pedido cliente="1">2</pedido>')
Estas dos inserciones se han realizado correctamente porque el valor de lacolumna XML
est bien formado; sin embargo, si intentas insertar la siguiente fila:
-- error en columna XML
insert EjemploXML values ( 3, '<pedido cliente="1">2</pedidos>')
Mostrando el error que se muestra a continuacin que indica que el XML no est bien
formado; fjate que el elemento pedido no est cerrado (se intenta cerrar con un elemento
pedidos:
Msg 9436, Level 16, State 1, Line 2
XML parsing: line 1, character 31, end tag does not match start tag
98
Parte del beneficio de usar columna XML nativa, es que la aplicacin cliente no necesitar
parsear el dato XML con los correspondientes objetos de .NET Framework, porque forma
parte del proceso de insercin del dato. Fjate en el error anterior: el servidor devuelve una
excepcin a la aplicacin cliente que tendr que ser gestionado de la manera adecuada.
En cuanto al almacenamiento del dato, en comparacin a guardarlo como texto "plano", la
columna XML nativa sin asociacin a esquema XML, el espacio utilizado es menor porque
slo se guardar una ocurrencia del valor de la etiqueta (o atributo) por cada fila; por
ejemplo, si un atributo se llama Pedidos_Realizados_Por_Cliente, el coste de
almacenamiento de guardar esa clave ser mayor cuanto mayor sea la clave. SQL Server
guardar la clave una vez en la fila, y para el resto de ocurrencias en la misma fila, en
lugar del valor de la clave se usar un puntero a la posicin donde est almacenada la
clave.
En el siguiente punto veremos la diferencia entre asociar la columna a un esquema XML o
no.
4.3.1.2. XML Nativo con Esquemas
Asociar un esquema XML a la columna de tipo XML aporta la posibilidad de hacer ms
"restrictiva" la validacin de la columna XML. Un buen ejemplo para aplicar con este
modelo de esquema-columnaXML es la comunicacin que realizan clientes y proveedores a
travs de un modelo de documentos XML estandarizados: ambas partes conocen el modelo,
y basndose en dicho modelo realizan la gestin del proceso definido.
Aqu aparece un punto discrepante entre el modelo relacional y el modelo XML; si se es
capaz de modelar un proceso, es muy posible que se pueda definir un modelo relacional
que lo cumpla: SQL Server es un servidor de bases de datos relacionales, y te encontrars
con casos que a pesar de poder implementar el esquema relacional, debido a la
complejidad del modelo, haya partes que deban implementarse siguiendo un esquema
XML; por ejemplo, XML es muy eficiente gestionando jerarquas, mientras que SQL Server,
acaba de introducirlas con las Expresiones de Tablas Comunes.
Para crear un esquema XML lo haremos de la siguiente forma:
CREATE XML SCHEMA COLLECTION schema1
AS
N'<?xml version="1.0" ?>
<xsd:schema targetNamespace="http://schemas.mi_base.com/schema1"
xmlns="http://schemas. mi_base.com/schema1"
elementFormDefault="qualified" attributeFormDefault="unqualified"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="Pedido">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="Numero" type="xsd:string" minOccurs="1"
maxOccurs="1"/>
<xsd:element name="Cliente" type="xsd:string" minOccurs="1"
maxOccurs="1"/>
<xsd:element name="Importe" type="xsd:int" minOccurs="1"
maxOccurs="1"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>'
Fjate que el esquema define la estructura de cmo ser el documento XML; llega hasta tal
nivel de detalle que especifica, el nmero de ocurrencias que deber tener cada atributo,
los nombres de los atributos, y elementos, e incluso los tipos de datos de cada uno de
ellos.
99
Y a continuacin se crea una tabla que use el esquema recin creado:
CREATE TABLE dbo.EjemploEsquema (Pedido xml (schema1))
Fjate que en el tipo de datos que se define para la columna Pedido, se especifica el
esquema XML creado anteriormente. A partir de este momento, se podrn insertar filas en
la tabla, haciendo referencia al esquema XML asociado al documento:
INSERT INTO dbo.EjemploEsquema (Pedido) VALUES
('<?xml version="1.0" ?>
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>2231-AX</Numero>
<Cliente>Microsoft</Cliente>
<Importe>250</Importe>
</Pedido>');
INSERT INTO dbo.EjemploEsquema (Pedido) VALUES
('<?xml version="1.0" ?>
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>3533-SQ</Numero>
<Cliente>Solid Quality Learning</Cliente>
<Importe>750</Importe>
</Pedido>');
De forma similar a como hemos visto anteriormente, si intentamos insertar un importe que
no es nmero entero (por ejemplo un caracter, o un valor numrico):
INSERT INTO dbo.EjemploEsquema (Pedido) VALUES
('<?xml version="1.0" ?>
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>3533-SQ</Numero>
<Cliente>Solid Quality Learning Iberoamericana</Cliente>
<Importe>750AA</Importe>
</Pedido>');
La insercin no se realizar, y adems obtendremos el siguiente mensaje de error, que nos
indica que el valor 750aa no es un tipo de datos vlido para el elemento Importe:
Msg 6926, Level 16, State 1, Line 1
XML Validation: Invalid simple type value: '750aa'. Location:
/*:Pedido[1]/*:Importe[1]
Lo mismo suceder si se intenta insertar un XML cuyo esquema no se ajusta al definido.
Por ejemplo, qu pasara si el documento XML tuviera un elemento llamado fecha?:
INSERT INTO dbo.EjemploEsquema (Pedido VALUES
('<?xml version="1.0" ?>
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>3538-SQ</Numero>
<Cliente>Solid Quality Learning Iberoamericana</Cliente>
<Importe>750</Importe>
<FechaPedido>2006-07-25</FechaPedido>
</Pedido>');
Aunque el XML est bien formado (fjate que el elemento FechaPedido est correctamente
definido), obtendremos la siguiente excepcin indicando que el elemento FechaPedido no se
esperaba en el XML:
Msg 6923, Level 16, State 1, Line 2
XML Validation: Unexpected element(s):
http://schemas.mi_base.com/schema1:FechaPedido. Location:
/*:Pedido[1]/*:FechaPedido[1]
100
Desde el punto de vista de almacenamiento, el uso de esquemas XML, ayuda a SQL Server
a no tener que almacenar en las columnas donde se almacenan los datos informacin
relativa a los atributos, y elementos del dato XML porque dicha informacin se encuentra
en el esquema XML.
4.3.2. ndices XML
Las columnas XML pueden indexarse para optimizar el acceso a las columnas XML, y mejorar
el rendimiento de las consultas XQuery que veremos a continuacin.
Para resolver consultas XQuery, si no existe ndice XML, SQL Server, tiene que crear la
estructura jerrquica la columna XML en memoria de cada columna, mientras que si est
indexado, dicha estructura jerrquica se encuentra ya serializada en el ndice, por lo que no
ser necesaria dicha "jerarquizacin" en memoria, con el consiguiente ahorro de uso de CPU.
Para poder indexar columnas XML, por diseo, es necesario que la tabla tenga definida un
ndice agrupado por la clave primaria de la tabla; ste requerimiento se debe a que en caso de
que la tabla se encuentra particionada (consultar particionado de datos en la documentacin
del producto), el ndice primario XML se pueda particionar usando el mismo esquema y funcin
de particionado.
Para definir el ndice XML primario, en la tabla EjemploEsquema aadiremos una columna
entera con la propiedad identity, que haremos clave primaria, sobre la que definiremos el
ndice agrupado:
ALTER TABLE dbo.EjemploEsquema
ADD identificador int IDENTITY
GO
ALTER TABLE dbo.EjemploEsquema
ADD CONSTRAINT ci_EjemploEsquema
PRIMARY KEY CLUSTERED
(identificador)
GO
4.3.2.1. ndice Primario
El ndice primario XML indexa la columna XML manteniendo referencias al dato XML, y al
ndice agrupado (el que indica la posicin de la fila de datos).
Para ello, usaremos la sentencia CREATE INDEX como en el siguiente ejemplo:
CREATE PRIMARY XML INDEX xml_index_EjemploEsquema
ON dbo.EjemploEsquema (Pedido)
GO
Una vez creado el ndice primario XML, el ndice agrupado (el que hemos creado para la
clave primaria), no podr modificarse; en caso de necesitar cambiar el ndice agrupado,
ser necesario borrar antes los ndices XML.
Una columna XML no puede formar parte de un ndice "normal" (los tradicionales ndices
agrupado, no agrupado). Adems, si la columna XML forma parte de una vista, no se podr
indexar la columna XML, es decir, las vistas indexadas no soportan ndices XML
4.3.2.2. ndice Secundario
Los ndices secundarios XML requieren que se haya creado un ndice primario XML. ste
tipo de ndices se definen para optimizar tipos de consultas XQuery; el ndice XML
secundario se definir para optimizar tipos de consultas concretos:
VALUE: cuando la consulta XQuery hace referencia a cualquier elemento del nodo; por
ejemplo, //Cliente=Microsoft: este caso devolvera todos los elementos cuyo autor sea
Jos Antonio, independientemente de que sea hijo de artculo u otro elemento.
101
PATH: beneficiar consultas XQuery que usan consultas tipo que buscan por el path del
XML, por ejemplo, /Pedido[Cliente=Solid Quality Learning]
PROPERTY: cuando se accede a propiedades del primer elemento de un nodo XML; por
ejemplo /Pedido/@Fecha
Por ejemplo, si queremos definir un ndice secundario para optimizar las consultas XQuery
que busquen valor de los ele
CREATE XML INDEX Path_EjemploEsquema_xml_index
ON dbo.EjemploEsquema(Pedido)
USING XML INDEX xml_index_EjemploEsquema
FOR PATH
GO
4.3.3. XQuery
XQuery es el lenguaje utilizado para realizar consultas sobre instancias XML. Al igual que T-
SQL se utiliza para realizar consultas sobre tablas de la base de datos, XQuery se utiliza para
consultar sobre datos de instancias XML nativas; es un lenguaje estandarizado por los
fabricantes y sus especificaciones se pueden consultar en W3C
(http://www.w3.org/XML/Query);
Algunos de los mtodos que se implementan en el lenguaje son:
query() para realizar consultas sobre una instancia XML; el valor devuelto no se ajusta a
ningn esquema, pero si es bien formado; por ejemplo:
select Pedido.query ('
declare namespace my="http://schemas.mi_base.com/schema1";
/my:Pedido/my:Cliente')
from dbo.EjemploEsquema
Devolver:
<my:Cliente xmlns:my="http://schemas.mi_base.com/schema1">
Microsoft<my:/Cliente>
<my:Cliente xmlns:my="http://schemas.mi_base.com/schema1">
Solid Quality Learning</my:Cliente>
value() para recuperar valores de la instancia XML.
exist() para comprobar si una consultas devuelve un resultado no vaci; por ejemplo:
select Pedido
from dbo.EjemploEsquema
where Pedido.exist ('
declare namespace my="http://schemas.mi_base.com/schema1";
/my:Pedido[(my:Cliente = "Microsoft")]') = 1
Devolver:
<my:Cliente xmlns:my="http://schemas.mi_base.com/schema1">
Microsoft<my:/Cliente>
modify() para hacer modificaciones; podremos usar las funciones XQuery insert, delete y
replace value of; veamos un ejemplo; reemplazar el nombre de cliente Solid Quality
Learning por Solid Quality Learning Iberoamericana en la columna Pedido de la tabla
EjemploEsquema:
update dbo.EjemploEsquema
set Pedido.modify ('
declare namespace my="http://schemas.mi_base.com/schema1";
replace value of (/my:Pedido/my:Cliente)[1]
with "Solid Quality Learning Iberoamericana" ')
where Pedido.exist ( '
102
declare namespace my="http://schemas.mi_base.com/schema1";
/my:Pedido[(my:Cliente = "Solid Quality Learning")]') = 1
Que indicar que se ha modificado una fila; el contenido de la tabla quedar como sigue:
select Pedido from dbo.EjemploEsquema
GO
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>2231-AX</Numero>
<Cliente>Microsoft</Cliente>
<Importe>250</Importe>
</Pedido>
<Pedido xmlns="http://schemas.mi_base.com/schema1">
<Numero>2232-SQ</Numero>
<Cliente>Solid Quality Learning Iberoamericana</Cliente>
<Importe>250</Importe>
</Pedido>
4.4. Integracin del CLR
Una de las novedades ms sonadas de SQL Server 2005 (tambin incluida en la versin Express)
es la integracin de .NET Framework en el gestor de bases de datos, en otras palabras, la
posibilidad de implementar cdigo manejado con cualquier lenguaje .NET (VB.NET, C#, J#, ...)
dentro del servidor.
Con esta nueva caracterstica habr dos tipos de reacciones "inconscientes" dependiendo del perfil
del profesional:
Desarrollador: Qu bien!! por fin podr crear esas rutinas de acceso a base de datos, y
procesos complejos dentro del servidor :-).
Administrador de bases de datos: Madre ma, la que se me viene encima!! Me van a meter
procesos increblemente complejos dentro del servidor, y no va haber manera de dar soporte a
cientos de conexiones concurrentes de usuario :-(
La integracin del .NET Framework, ha creado una polmica que se resuelve con una frase: "Cada
cosa para lo que es"; es decir, .NET Framework tiene cualidades envidiables por el motor de base
de datos, mientras que el motor de base de datos tiene caractersticas en las que no es eficiente
.NET Framework. Usemos ambas tecnologas para obtener lo mejor de ambas caractersticas
integradas !!
Nota: Otros fabricantes de bases de datos tambin ofrecen integracin de .NET (u otros lenguajes
como Java) en sus motores relacionales; desde nuestro punto de vista, la ms importante
diferencia entre la integracin de .NET Framework en SQL Server frente al resto de fabricantes, es
que el propio motor relacional (SQL Server) se encarga de gestionar el acceso y uso de recursos
de los componentes .NET integrados; es decir, SQL Server conoce las necesidades de cada
recurso, y dinmicamente gestiona su asignacin de recursos.
4.4.1. Beneficios
4.4.1.1. Modelo de programacin mejorado
Los lenguajes .NET son lenguajes orientados a objeto, y a diferencia de T-SQL son ms
fciles de aprender, y su curva de aprendizaje es relativamente menor. Por otra parte son
lenguajes de programacin en los que su capacidad para realizar bucles, iteraciones, y
clculos es ms potente que T-SQL.
4.4.1.2. Seguridad
Se ofrece un nivel de seguridad completo desde el momento en que se integra la librera
.NET (assembly) en el servidor. Se especificar el modelo de seguridad en el momento de
insertar el assembly en la base de datos. En el punto de Creacin y uso de objetos CLR en
la base de datos veremos ms en detalle cada uno de los modelos.
103
4.4.1.3. Nuevos tipos de datos y agregados
La integracin del CLR ofrece la posibilidad de crear tipos de datos con .NET Framework;
como veremos ms adelante al desarrollar el assembly tendrs que ajustarte a unas reglas
para poder implementar el tipo de datos, o agregado.
4.4.1.4. til para mejorar rendimiento de procesos
.NET es un lenguaje muy eficiente realizando clculos complejos que requiere de mucho
uso de recursos como CPU; .NET viene a cubrir un hueco en el que T-SQL no es tan
eficiente.
4.4.2. Cuando usar cada modelo
4.4.2.1. T-SQL
T-SQL es un lenguaje muy efectivo accediendo a conjuntos de datos; est diseado para
tratar grandes conjuntos de datos, aunque no es tan efectivo con clculos complejos, o
realizando complicadas operaciones lgicas. Adems, T-SQL no soporta arrays, operaciones
iterativas (for-each), ni tiene la posibilidad de definir clases.
4.4.2.2. .NET Framework: Cdigo manejado
Los lenguajes .NET son muy efectivos realizando clculos complejos, y complejas
operaciones lgicas. Adems, el CLR ofrece la posibilidad de acceder a la gran mayora de
las libreras de .NET Framework.
Por ejemplo, acceso al sistema de ficheros, complejas operaciones matemticas con las
libreras .NET, manejo de cadenas, operaciones con expresiones regulares; en definitiva,
usar las libreras de .NET.
4.4.3. Modelo de seguridad
Cuando se aade la referencia de un assembly en la base de datos, se debe definir el modelo
de seguridad que seguir el assembly; bsicamente es decirle a SQL Server cuales sern los
recursos/operaciones para las que tiene permiso el assembly.
4.4.3.1. SAFE
Es el permiso por defecto. El assembly no puede acceder a recursos externos de SQL
Server como ficheros, red, variables de entorno, etc. El assembly slo podr realizar
operaciones de acceso a datos en la base de datos en la que se instale.
4.4.3.2. EXTERNAL_ACCESS
Se permite el acceso a ciertos recursos externos del sistema como ficheros, red, servicios
Web, variables de entorno, y entradas del registro. Adems se podr acceder a las libreras
de .NET Framework que estn marcadas como seguras. Bajo este modelo de seguridad, el
acceso a los recursos se hace a travs de la cuenta que inici el servicio SQL Server, a
menos que explcitamente se haga impersonacin).
4.4.3.3. UNSAFE
Bajo este nivel de seguridad, el acceso a los recursos del sistema es ilimitado y se puede
hacer llamadas a cdigo no manejado. Este modelo de seguridad es el modelo de seguridad
que en la versin 2000 de SQL Server utilizan los procedimientos almacenados extendidos
(XPs). Slo los miembros del grupo de usuarios sysadmin tienen permiso para insertar
assemblies de este tipo en la base de datos.
4.4.4. Qu se puede crear?
Funciones definidas de usuario (UDFs).
Funciones escalares (scalar UDF).
104
Funciones de tabla (TVF).
Procedimientos almacenados (UDP).
Tipos de datos definidos de usuario (UDDTs).
Triggers.
Funciones de agregado.
4.4.5. Creacin y uso de objetos CLR en la base de datos
Las versiones Express de Visual Studio no ofrecen la integracin completa del proceso de
desarrollo, e implementacin que ofrecen el resto de versiones de Visual Studio. Aunque es un
inconveniente para el proceso rpido de aplicaciones (RAD), a nivel didctico es til para
comprender ms afondo el proceso de implementacin.
Eso en cuanto a la parte de las herramientas de Visual Studio Express que consistira en
generar una DLL del ensamblado, y posteriormente, desplegar el ensamblado en la base de
datos. En cuanto a la parte de SQL Server 2005 Express, SQL Server 2005 Management Studio
Express, ofrece la posibilidad de integrar el assembly en la base de datos de manera "visual",
para que mediante sentencias T-SQL se cree el tipo de datos, funcin, procedimiento, etc.
desde una ventana del Editor de consultas.
4.4.5.1. Creacin del cdigo .NET
Para hacer un ejemplo completo, vamos a implementar un tipo definido de usuario que
implemente un objeto de tipo punto: un punto ser un objeto que tiene una coordenada X
y otra coordenada Y. Para ello en primer lugar implementaremos el objeto punto desde
VB.NET y lo generaremos la DLL correspondiente.
En primer lugar crearemos un proyecto del tipo librera de clases que le llamaremos Punto.
A continuacin copia el siguiente cdigo en la clase Punto recin creada (explicaremos
ahora los mtodos):
Imports System
Imports System.Data
Imports System.Data.SqlClient
Imports System.Data.SqlTypes
Imports Microsoft.SqlServer.Server
<Serializable()>
_
<Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)>
_
Public Structure Punto
Implements INullable
Public X As Integer
Public Y As Integer
Private m_Null As Boolean
Public Overrides Function ToString() As String
' Put your code here
Return X.ToString() + ", " + Y.ToString()
End Function
Public ReadOnly Property IsNull() As Boolean
Implements INullable.IsNull
Get
' Put your code here
Return m_Null
105
End Get
End Property
Public Shared ReadOnly Property Null As Punto
Get
Dim p As New Punto()
p.m_Null = True
Return p
End Get
End Property
Public Shared Function Parse(ByVal s As SqlString) As Punto
If s.IsNull Then
Return Null
End If
Dim p As Punto = New Punto
' Put your code here
Dim s2() As String = CType(s, String).Split
p.X = Convert.ToInt32(s2(0))
p.Y = Convert.ToInt32(s2(1))
Return p
End Function
End Structure
Si te fijas en el cdigo de la clase Punto, podrs ver que tiene definido un mtodo llamado
Parse que lo que hace es dado un string de tipo SqlString lo convierte a un objeto de tipo
Punto; el mtodo que implementa es recibir por valor una variable string que contiene dos
valores enteros separados por un espacio en blanco; si recibe un valor '1 3', en "modo"
objeto ser Punto.X = 1, y Punto.Y = 3.
Tambin debes notar el mtodo ToString que hace precisamente el proceso inverso, que es
convertir un objeto Punto a un string
Adicionalmente hay que implementar el interfaz IsNull porque debemos definir cmo va a
interpretar SQL Server la nulabilidad del objeto.
Se han definido como pblicas las variables X e Y para que como veremos despus se
pueda "interrogar" mtodos/o variables del objeto.
A continuacin debers generar la dll: Men Proyect, Generar Punto (que es el nombre de
la clase).
Localiza la ruta donde se ha generado la dll porque deber hacrsele referencia en el
siguiente punto.
4.4.5.2. Insercin del assembly en la base de datos
Una vez generados los binarios del objeto punto, debemos aadir la referencia al objeto en
la base de datos. Para ello existen la sentencia CREATE ASSEMBLY cuyo ejemplo sera el
siguiente:
CREATE [nombre_del_assembly]
FROM 'ruta_al_fichero_dll'
WITH PERMISSION_SET = <Tipo_de_permiso>;
106
En lugar de crear la referencia con la sentencia T-SQL, lo vamos a hacer desde las
Management Studio. Para ello, expande la base de datos MSDNDemo, expande el nodo
programabilidad, y selecciona la opcin New Assembly como se muestra en la imagen
siguiente:
107
A continuacin, debers, rellenar los valores que aparecen en el recuadro de la siguiente
imagen; debers localizar la ruta a la dll (en el ejemplo de la imagen est ubicado en
C:\ejemplos\Punto\Punto\bin\Release\Punto.dll:
Pulsa en aceptar, y el assembly quedar "grabado" en la base de datos.
Una vez aadida la referencia del assembly en la base de datos, la dll original puede ser
eliminada porque los binarios del assembly se encuentran almacenados en la base de
datos.
Si deseas consultar los assemblies que hay en una base de datos puedes consultas la vista
de sistema sys.assemblies.
El siguiente paso ser crear un objeto en la base de datos que haga referencia a la dll
recin insertada: recuerda que todava no hemos definido el tipo de objeto que existir en
la base de datos... es decir tenemos que crear el procedimiento almacenado, en tipo de
datos, el trigger, etc.
4.4.5.3. Creacin del objeto
Lo que hemos hecho hasta ahora ha sido generar una dll, y "poner" esa dll dentro de la
base de datos. Ahora es el momento en que se crear el objeto de base de datos que haga
referencia al assembly creado.
En SQL Server 2005 (todas las versiones), el uso de la integracin del CLR est
deshabilitada por defecto. Para habilitarla hay que ejecutar un procedimiento almacenado
de sistema:
EXEC sp_configure 'show advanced options', 1
GO
108
RECONFIGURE
GO
sp_configure 'clr enabled', 1
GO
RECONFIGURE
GO
Nota: Esta operacin tambin se puede realizar desde la herramienta SAC (Configuracin
de Superficie de SQL Server), vista en la leccin de instalacin del mdulo 1.
Una vez habilitada la integracin del CLR, procederemos en nuestro caso a crear el tipo de
datos punto:
CREATE TYPE Punto
EXTERNAL NAME Punto.[Punto.Punto];
GO
Con esta operacin hemos aadido un nuevo tipo de datos a la lista de tipos de datos de
sistema que se llama Punto, e implementar la funcionalidad que hemos definido en el
assembly que hemos generado en VB.NET.
4.4.5.4. Llamada al objeto
Dependiendo del tipo de objeto creado, la llamada al objeto se har de formas diferentes;
en nuestro caso, como hemos creado un tipo de datos crearemos una tabla que utilice el
tipo punto que acabamos de crear. Lo haremos de la siguiente forma:
CREATE TABLE dbo.Posiciones (
id int IDENTITY,
pos Punto NOT NULL);
GO
Y a continuacin insertaremos unas cuantas filas:
-- conversin implcita
INSERT dbo.Posiciones
VALUES ('1 2');
GO
-- conversin explicita
INSERT dbo.Posiciones (pos)
VALUES (CAST('1 3' as Punto))
GO
Y ahora haremos unas cuantas consultas al objeto:
-- conversin implcita
SELECT * FROM dbo.Posiciones
GO
Devolver:
id Punto
1 0x800000018000000200
2 0x800000018000000300
Ese valor binario es la representacin "real" del objeto
SELECT
pos.X as PosicionX,
pos.Y as PosicionY
FROM dbo.Posiciones
Que devolver:
PosicionX PosicionY
1 2
109
1 3
Tambin podremos llamar al mtodo ToString() de la siguiente forma:
SELECT CAST(pos AS varchar(10)) v1, pos.ToString() v2
FROM dbo.Posiciones
Que devolver:
v1 v2
1, 2 1, 2
1, 3 1, 3
Conclusiones: Hemos implementado un tipo de datos, que SQL Server no incorpora de
forma nativa; tambin se podra implementar un tipo de datos para definir la fecha el
formato UTC.
Nunca deberan usarse tipos de datos CLR para implementar funcionalidades de negocio;
por ejemplo, un objeto Cliente que tenga mtodos Nombre, NIF, Direccin, etc. Este es un
caso que no ser eficiente debido a la sobrecarga que supone el almacenamiento del tipo, y
el coste y complejidad de la estrategia de indexacin.
4.4.6. Otras implementaciones
Veamos como sera el caso de un procedimiento almacenado desarrollado con .NET:
Este ejemplo es vlido a nivel didctico para conocer la funcionalidad pero debido a que hace
uso "exclusivo" de acceso a datos, ser ms eficiente realizarlo desde T-SQL.
Partial Public Class StoredProcedures
<Microsoft.SqlServer.Server.SqlProcedure()> _
Public Shared Sub Clientes_GetAllVB()
Using connection As New SqlConnection("context connection=true")
Dim Command As New SqlCommand("SELECT * FROM dbo.Clientes")
SqlContext.Pipe.ExecuteAndSend(Command)
End Using
End Sub
End Class
Dos novedades:
En lugar de especificar una cadena de conexin, se ha definido un string como "context
connection=true". Lo que hace ste mtodo es usar la conexin del proceso llamador en
lugar de crear una conexin nueva de acceso a base de datos.
El mtodo ExecuteAndSend enva el resultado del comando a travs del Pipe abierto por la
conexin.
La clase StoredProcedures est decorada con el atributo
Microsoft.SqlServer.Server.SqlProcedure()
Se crear la referencia al assembly:
CREATE ASSEMBLY Procedimientos
FROM
'C:\ejemplos\Procedimientos\Procedimientos\bin\Release\Procedimientos.dll'
Y ahora se crear la referencia al procedimiento almacenado con el cdigo:
CREATE PROCEDURE Clientes_GetAllVB AS EXTERNAL NAME
Procedimientos.[Procedimientos.StoredProcedures].Clientes_GetAllVB;
Y la llamada se hara de la misma manera que vimos en el captulo 1 del mdulo 3:
EXEC Clientes_GetAllVB
También podría gustarte
- UF2406 - El cliclo de vida del desarrollo de aplicacionesDe EverandUF2406 - El cliclo de vida del desarrollo de aplicacionesAún no hay calificaciones
- Servidor OPC para La Importación de Datos A ExcelDocumento8 páginasServidor OPC para La Importación de Datos A ExcelDouglas SotezAún no hay calificaciones
- Manual 2014-I 02 Base de Datos - Laboratorio (0031)Documento147 páginasManual 2014-I 02 Base de Datos - Laboratorio (0031)GoLdFrAnKMaNAún no hay calificaciones
- Programación Java - Una Guía para Principiantes para Aprender Java Paso a PasoDe EverandProgramación Java - Una Guía para Principiantes para Aprender Java Paso a PasoCalificación: 3 de 5 estrellas3/5 (7)
- A1 1dlrmfcojavDocumento11 páginasA1 1dlrmfcojavfranciscoAún no hay calificaciones
- Reporte Instalacion SQL ServerDocumento14 páginasReporte Instalacion SQL ServerMartin PérezAún no hay calificaciones
- Introducción A SQL Server 2005Documento41 páginasIntroducción A SQL Server 2005pilladaAún no hay calificaciones
- IMVB2005Documento164 páginasIMVB2005Janina Muñoz LayAún no hay calificaciones
- Capitulo 1Documento13 páginasCapitulo 1Cesar SandovalAún no hay calificaciones
- Módulo 2: Planes para La Instalación de SQL Server: ContenidoDocumento62 páginasMódulo 2: Planes para La Instalación de SQL Server: ContenidonicolasAún no hay calificaciones
- Consideraciones para Migrar SQL Server 2000Documento3 páginasConsideraciones para Migrar SQL Server 2000Liliana SanchezAún no hay calificaciones
- Reporte de Instalacion.Documento8 páginasReporte de Instalacion.ARELIAún no hay calificaciones
- TIP para Conectar SQL Server 2008Documento126 páginasTIP para Conectar SQL Server 200814mpadillaAún no hay calificaciones
- Manual de Microsoft SQL Server TRANSACT SQLDocumento127 páginasManual de Microsoft SQL Server TRANSACT SQLJose Augusto Peña CabreraAún no hay calificaciones
- Curso 20764-C Administering A SQL Database InfrastructureDocumento13 páginasCurso 20764-C Administering A SQL Database Infrastructurecarlos rafhael satizabal sanchezAún no hay calificaciones
- Tutorial de SQL Server 2005Documento29 páginasTutorial de SQL Server 2005chino_2803Aún no hay calificaciones
- SQL DesinstalarDocumento28 páginasSQL Desinstalarsilver92Aún no hay calificaciones
- Manual de Configuracion Aspel Sae 4Documento15 páginasManual de Configuracion Aspel Sae 4Felipe Contreras HernandezAún no hay calificaciones
- Migración A SQL Server 2008 R2Documento4 páginasMigración A SQL Server 2008 R2Juan Francisco Painen MeloAún no hay calificaciones
- Manual de Microsoft SQL Server-TRANSACT SQLDocumento127 páginasManual de Microsoft SQL Server-TRANSACT SQLAnonymous C0SJ9crAún no hay calificaciones
- Requisitos de Instalacion MySqlDocumento51 páginasRequisitos de Instalacion MySqlmilcl031933% (3)
- Manual de Instalacion SQL Server 2008Documento10 páginasManual de Instalacion SQL Server 2008CarmeloAún no hay calificaciones
- Microsoft SQL ServerDocumento5 páginasMicrosoft SQL ServerRitsuFujiokaAún no hay calificaciones
- Manual de SQL Server 2014Documento37 páginasManual de SQL Server 2014JorgeBeristain100% (1)
- Introduccion SQL Server 2000Documento192 páginasIntroduccion SQL Server 2000Edwin Medina0% (1)
- Respuestas Actividad 01 BigData - Opc2Documento30 páginasRespuestas Actividad 01 BigData - Opc2Jhan Hader Muñoz BermudezAún no hay calificaciones
- Fundamentos de Base de Datos1Documento44 páginasFundamentos de Base de Datos1Pao LitaAún no hay calificaciones
- Fundamentos de Base de Datos1.odtDocumento44 páginasFundamentos de Base de Datos1.odtPao LitaAún no hay calificaciones
- Respuestas de La Actividad 01 de Big DataDocumento12 páginasRespuestas de La Actividad 01 de Big DataJhan Hader Muñoz BermudezAún no hay calificaciones
- SQL Server 2005 - Curso 5 EstrellasDocumento206 páginasSQL Server 2005 - Curso 5 EstrellasImportacionesPuquiAún no hay calificaciones
- Curso 70-410 Win 2012Documento207 páginasCurso 70-410 Win 2012Fer SSz100% (1)
- Instalar SQL Server 2017Documento19 páginasInstalar SQL Server 2017Franco ChavezAún no hay calificaciones
- Componentes de MySQL, Workbench Control 7Documento20 páginasComponentes de MySQL, Workbench Control 7Alexander DjForever CarocaAún no hay calificaciones
- Tutorial OracleDocumento60 páginasTutorial OracleJavier Pazos Tilves100% (1)
- LECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyDocumento85 páginasLECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyAndy Alva AcostaAún no hay calificaciones
- Curso 6822ADocumento512 páginasCurso 6822AJuan Miguel Mendoza PerezAún no hay calificaciones
- R n1 Que Es PL SQLDocumento27 páginasR n1 Que Es PL SQLjorgeAún no hay calificaciones
- Manual de SQL Server 2008 OkeyDocumento131 páginasManual de SQL Server 2008 Okeynetos86xAún no hay calificaciones
- 01 - Unidad 01 - SQL Server - Instalación y Configuración Inicial v4Documento24 páginas01 - Unidad 01 - SQL Server - Instalación y Configuración Inicial v4José Miguel GarcíaAún no hay calificaciones
- Descargar e Instalar SQL Server Express 2008Documento5 páginasDescargar e Instalar SQL Server Express 2008Karla CruzAún no hay calificaciones
- Examen Final-Instalación de SQLDocumento10 páginasExamen Final-Instalación de SQLCESAR HERNAN PATRICIO PERALTAAún no hay calificaciones
- Practica 5 AmdDocumento4 páginasPractica 5 Amdedwin briosoAún no hay calificaciones
- Manual InstalacionDocumento9 páginasManual InstalacionSofia Quintana GutierrezAún no hay calificaciones
- Capacitacion SQLServer 2014 Administracion PDFDocumento9 páginasCapacitacion SQLServer 2014 Administracion PDFEber Rafael Ruiz ZamoraAún no hay calificaciones
- Instalación de SQL ServerDocumento15 páginasInstalación de SQL ServerEunhae 97Aún no hay calificaciones
- Instalación y Administración de SQL Server 2000Documento13 páginasInstalación y Administración de SQL Server 2000Italo MirandaAún no hay calificaciones
- Tutorial Forms 9iDocumento47 páginasTutorial Forms 9iJavier Luján Esquivia100% (1)
- Aegxxi - Desarrollo Revisando SQL Server 2008, Definición, Cursos, Manuales - 09-10-2012Documento11 páginasAegxxi - Desarrollo Revisando SQL Server 2008, Definición, Cursos, Manuales - 09-10-2012GcTronic BCAún no hay calificaciones
- UF1271 - Instalación y configuración del software de servidor webDe EverandUF1271 - Instalación y configuración del software de servidor webAún no hay calificaciones
- Instalación y configuración del software de servidor web. IFCT0509De EverandInstalación y configuración del software de servidor web. IFCT0509Aún no hay calificaciones
- Desarrollo de aplicaciones web en el entorno servidor. IFCD0210De EverandDesarrollo de aplicaciones web en el entorno servidor. IFCD0210Aún no hay calificaciones
- Despliegue y puesta en funcionamiento de componentes software. IFCT0609De EverandDespliegue y puesta en funcionamiento de componentes software. IFCT0609Aún no hay calificaciones
- Conexión SQL SERVER & C# (Manual para principiantes)De EverandConexión SQL SERVER & C# (Manual para principiantes)Calificación: 1 de 5 estrellas1/5 (1)
- Dominando PowerShell: Una Guía Paso a Paso: La colección de TIDe EverandDominando PowerShell: Una Guía Paso a Paso: La colección de TIAún no hay calificaciones
- Administración y auditoría de los servicios de mensajería electrónica. IFCT0509De EverandAdministración y auditoría de los servicios de mensajería electrónica. IFCT0509Aún no hay calificaciones
- Examen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2De EverandExamen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2Aún no hay calificaciones
- Manual de Supervivencia del Administrador de Bases de DatosDe EverandManual de Supervivencia del Administrador de Bases de DatosAún no hay calificaciones
- Examen Profesional Certificado de Nube AWS Guía de éxito 1: Examen Profesional Certificado de Nube AWS Guía de Éxito, #1De EverandExamen Profesional Certificado de Nube AWS Guía de éxito 1: Examen Profesional Certificado de Nube AWS Guía de Éxito, #1Aún no hay calificaciones
- 04 JavaScriptDocumento26 páginas04 JavaScriptArmando HerreraAún no hay calificaciones
- Linea de Las ComputadorasDocumento7 páginasLinea de Las ComputadorasKarina GarciaAún no hay calificaciones
- Instrucciones PPSSPPDocumento12 páginasInstrucciones PPSSPPCkarlos Mtz hdezAún no hay calificaciones
- Examen ParcialDocumento2 páginasExamen ParcialHERLIN HAMED LUDEÑA MORENOAún no hay calificaciones
- Tabla de Ventajas y DesventajasDocumento1 páginaTabla de Ventajas y DesventajasJOSE DAVID VILLALBA MARRUGO0% (1)
- Metodologia AUPDocumento3 páginasMetodologia AUPdayvicitoAún no hay calificaciones
- Programación Reactiva Con React NodeJS MongoDB DemoDocumento67 páginasProgramación Reactiva Con React NodeJS MongoDB DemoGonzalo100% (1)
- Material de Apoyo - Acelerador de Carrera Con Power BIDocumento11 páginasMaterial de Apoyo - Acelerador de Carrera Con Power BIlaura cortesAún no hay calificaciones
- Programas Hack para JuegosDocumento3 páginasProgramas Hack para JuegosSantiago BautistaAún no hay calificaciones
- Tutorial de Sublime Text 2Documento53 páginasTutorial de Sublime Text 2ehavella055Aún no hay calificaciones
- Actividad 02Documento2 páginasActividad 02Lizbeth Estefany Chalco QuispeAún no hay calificaciones
- Educaplay PDFDocumento8 páginasEducaplay PDFALEXANDRA VIZCAINOAún no hay calificaciones
- Caracteristicas de Word (Examen Final Word)Documento2 páginasCaracteristicas de Word (Examen Final Word)centro integralAún no hay calificaciones
- Unidad 4 Sistema OperativoDocumento7 páginasUnidad 4 Sistema Operativo123eduardo123Aún no hay calificaciones
- INFORME Practica Configuración RouterDocumento8 páginasINFORME Practica Configuración RouterSilviaAún no hay calificaciones
- Seguridad 22 FebreroDocumento30 páginasSeguridad 22 FebreroRaymundo LiraAún no hay calificaciones
- Seguimiento de Alertas de Antivirus - SophosDocumento469 páginasSeguimiento de Alertas de Antivirus - SophosNicolas MendezAún no hay calificaciones
- Tarea 06Documento5 páginasTarea 06Jose Luis Mercado Gurtubay0% (1)
- Biblioteca DigitalDocumento11 páginasBiblioteca DigitalAmparo Yauri SuarezAún no hay calificaciones
- Cotizacion Catalogo Dominios Paginas de Aterrizaje y Logotipo LrsMuyco 12Agosto2013V1 PDFDocumento4 páginasCotizacion Catalogo Dominios Paginas de Aterrizaje y Logotipo LrsMuyco 12Agosto2013V1 PDFRaúl Del Angel MendozaAún no hay calificaciones
- Manual de Firma Avanzada para MacDocumento16 páginasManual de Firma Avanzada para MacHernán Maluk ManzanoAún no hay calificaciones
- Qué Es Metasploitable3Documento16 páginasQué Es Metasploitable3Hans Erick Neumann OyarzoAún no hay calificaciones
- Plataformas de Contenido DigitalDocumento3 páginasPlataformas de Contenido Digitalelmer garciaAún no hay calificaciones
- Java Siace - Triptico (Configuracion)Documento2 páginasJava Siace - Triptico (Configuracion)David GaitanAún no hay calificaciones
- Lab1 Footprinting P1Documento7 páginasLab1 Footprinting P1merealtxd durellaAún no hay calificaciones
- Introducción A Unity 3DDocumento7 páginasIntroducción A Unity 3DJonathanHerreraAún no hay calificaciones
- La NiñaDocumento6 páginasLa NiñaValeria Torres martinezAún no hay calificaciones
- Ficha Resumen de Sistema de InformacionDocumento2 páginasFicha Resumen de Sistema de InformacionMujerVirtuosaAún no hay calificaciones
- Top Value Computing Oct2014Documento19 páginasTop Value Computing Oct2014gonzaordAún no hay calificaciones
- Genially 6579e51990a1a600147b6278Documento46 páginasGenially 6579e51990a1a600147b6278sandra.escobar1005Aún no hay calificaciones