También podría gustarte
- EL LIBRO DE MAAT: El Legado de Hermes TrismegistoDocumento275 páginasEL LIBRO DE MAAT: El Legado de Hermes TrismegistoUndersunset Phcore100% (13)
- Codigos de Falla PCC1301Documento2 páginasCodigos de Falla PCC1301DiegoRomero100% (20)
- Meditacion Luna LlenaDocumento19 páginasMeditacion Luna LlenagaczAún no hay calificaciones
- Actividad # 5 Prehistoria Sexto 2021Documento7 páginasActividad # 5 Prehistoria Sexto 2021oscar duarteAún no hay calificaciones
- Oswaldo Ramón Hevia Araujo, METODOLOGÍA DE ESCENARIOSDocumento15 páginasOswaldo Ramón Hevia Araujo, METODOLOGÍA DE ESCENARIOSMartínSánchezAún no hay calificaciones
- 02.estructuras Algebraicas y Sistemas Numericos VFDocumento24 páginas02.estructuras Algebraicas y Sistemas Numericos VFDussan PalmaAún no hay calificaciones
- Guia MB535 2011 1 TodoDocumento117 páginasGuia MB535 2011 1 TodoValentin Jesus Quezada PorturasAún no hay calificaciones
- Parcial - Escenario 4 - DIVERSIDAD E INCLUSIÓN - (GRUPO B01)Documento8 páginasParcial - Escenario 4 - DIVERSIDAD E INCLUSIÓN - (GRUPO B01)erika espinosaAún no hay calificaciones
- Cuadernillo1 PDFDocumento67 páginasCuadernillo1 PDFVíctor A Hernández Ureña100% (2)
- AmortiguadoDocumento20 páginasAmortiguadoAnonymous az9hzE8Aún no hay calificaciones
- Algoritmos VoracesDocumento9 páginasAlgoritmos VoracesoscarAún no hay calificaciones
- ArreglosDocumento7 páginasArreglosJose Eduardo Gonzalez BarraganAún no hay calificaciones
- MN Senl 22-23 01 02Documento79 páginasMN Senl 22-23 01 02Criss TorresAún no hay calificaciones
- Problemas Mark Spong II Unidad Movimientos Rigidos y Tranformaciones Homogeneas PDFDocumento17 páginasProblemas Mark Spong II Unidad Movimientos Rigidos y Tranformaciones Homogeneas PDFGibranDanielReyesAún no hay calificaciones
- Taller 1 Octave-2023-2Documento13 páginasTaller 1 Octave-2023-2Ever Rafael MosqueraAún no hay calificaciones
- TPG2 Introducción A Matlab PIDocumento5 páginasTPG2 Introducción A Matlab PIpatriciaAún no hay calificaciones
- HOLADocumento10 páginasHOLAnahomyAún no hay calificaciones
- Respuesta de Un Sistema de Ecuaciones A Través de FiltradoDocumento9 páginasRespuesta de Un Sistema de Ecuaciones A Través de FiltradoEduardo PastorAún no hay calificaciones
- Ejercicios PDFDocumento6 páginasEjercicios PDFanon_308927632Aún no hay calificaciones
- Guía Lab Chaotic PendulumDocumento12 páginasGuía Lab Chaotic PendulumAlejandro Mario Mcleman OliveraAún no hay calificaciones
- MatLab. ComandosDocumento9 páginasMatLab. ComandoslioaaguilaAún no hay calificaciones
- Intro MatlabDocumento11 páginasIntro MatlabElibardo J Ballesteros SAún no hay calificaciones
- Ecuación Diferencial De Primer Orden: Dqdt=V R−Qrcdqdt=Vεr−QrcDocumento19 páginasEcuación Diferencial De Primer Orden: Dqdt=V R−Qrcdqdt=Vεr−QrcLuis Carlos Viloria RivasAún no hay calificaciones
- Manual WxmaximaDocumento33 páginasManual WxmaximaAndres BuitragoAún no hay calificaciones
- U2 Ejercicios de EjemploDocumento4 páginasU2 Ejercicios de EjemploLuisa Mee 666Aún no hay calificaciones
- 09.ed - Practica SortDocumento4 páginas09.ed - Practica SortJ'a GuerreroAún no hay calificaciones
- Lab04 521230 2018 PDFDocumento10 páginasLab04 521230 2018 PDFAndres LAún no hay calificaciones
- Ejercicios Primer Capitulo Del Libro LayDocumento20 páginasEjercicios Primer Capitulo Del Libro Layander100% (1)
- Anexo 3. Ejercicios Calculo Resueltos 2Documento6 páginasAnexo 3. Ejercicios Calculo Resueltos 2SIAETAún no hay calificaciones
- Lec3 SolDocumento14 páginasLec3 SolVictor LprdAún no hay calificaciones
- Sistemas Tiempo Continuo y DiscretoDocumento7 páginasSistemas Tiempo Continuo y DiscretoWilliam QuimbitaAún no hay calificaciones
- APUNTES CALCULO II 2021 - Capitulo 1 - Primera ParteDocumento8 páginasAPUNTES CALCULO II 2021 - Capitulo 1 - Primera ParteTorrez Fuentes Johan I.Aún no hay calificaciones
- Union-Find Explicacion PDFDocumento6 páginasUnion-Find Explicacion PDFprogramación de rincónAún no hay calificaciones
- Funciones de MatlabDocumento72 páginasFunciones de MatlabKrloxx AkinoAún no hay calificaciones
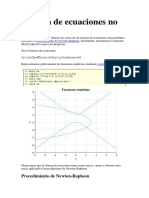
- Sistema de Ecuaciones No LinealesDocumento9 páginasSistema de Ecuaciones No LinealesWanderley Kevin Alccaihuaman Quispe0% (1)
- Semana7-Matematica IDocumento28 páginasSemana7-Matematica IRuth Gomez ChinoAún no hay calificaciones
- 05 Espacios VectorialesDocumento5 páginas05 Espacios VectorialesDaniel antony hernandez aquinoAún no hay calificaciones
- Sist DeEc Lineals-Haeussler (2008,22p)Documento22 páginasSist DeEc Lineals-Haeussler (2008,22p)Roger YvánAún no hay calificaciones
- Prac No LinealDocumento13 páginasPrac No LinealPaul Hernan Sany InquillaAún no hay calificaciones
- 4-Operaciones Con MatricesDocumento11 páginas4-Operaciones Con MatricesKimberlyAún no hay calificaciones
- Funciones Matemáticas 1 A:: EjemploDocumento17 páginasFunciones Matemáticas 1 A:: EjemplonicoleAún no hay calificaciones
- Laboratorio 6.RDocumento9 páginasLaboratorio 6.RImmanuel CristianAún no hay calificaciones
- Ejercicios Resueltos Scilab PDFDocumento32 páginasEjercicios Resueltos Scilab PDFCarlosAntonioSanchezArias100% (1)
- Transformaciones HomogéneasDocumento12 páginasTransformaciones HomogéneasRigoberto XVIIIAún no hay calificaciones
- PenduloDocumento5 páginasPenduloAlejandro Mario Mcleman OliveraAún no hay calificaciones
- Calculo Infinitesimal Trabajo Personal Trinidad Salas JosephDocumento12 páginasCalculo Infinitesimal Trabajo Personal Trinidad Salas JosephYamirAún no hay calificaciones
- Espacios Vectoriales Usil PDFDocumento40 páginasEspacios Vectoriales Usil PDFVICTORPAUFERAún no hay calificaciones
- Act 1. EjemplosDocumento2 páginasAct 1. EjemplosMagally Conde ArandaAún no hay calificaciones
- Lec10 PDFDocumento20 páginasLec10 PDFalicardozoAún no hay calificaciones
- Calculo Integral, EdgarDocumento9 páginasCalculo Integral, EdgaredgarAún no hay calificaciones
- Graficar Con Linspace PDFDocumento7 páginasGraficar Con Linspace PDFJorge Felipe BlancoAún no hay calificaciones
- Actividad 5DDocumento10 páginasActividad 5DMelinaAún no hay calificaciones
- Notas-Geometria DiferencialDocumento66 páginasNotas-Geometria DiferencialDario MatehuAún no hay calificaciones
- Libro Programacion Cap10Documento24 páginasLibro Programacion Cap10gaAún no hay calificaciones
- Ejercicios UnidadIII PDFDocumento7 páginasEjercicios UnidadIII PDFMiguel BotelloAún no hay calificaciones
- A Punt Es OctaveDocumento51 páginasA Punt Es OctaveAlEx HernandezAún no hay calificaciones
- NEWTON RAPHSONaaDocumento11 páginasNEWTON RAPHSONaaHellWalkerAún no hay calificaciones
- Laboratorio 1 MatlabDocumento6 páginasLaboratorio 1 MatlabMarlln BobadillaAún no hay calificaciones
- Laboratorio4 PDFDocumento4 páginasLaboratorio4 PDFconsueloriquelme1Aún no hay calificaciones
- Aplicacion de IntegralesDocumento4 páginasAplicacion de IntegralesRodriguez Vasquez OsvaldoAún no hay calificaciones
- Guia MB536 2009 1separata3Documento111 páginasGuia MB536 2009 1separata3Uni WvillegaspAún no hay calificaciones
- Libro - Programacion Cap12 MatricesDocumento19 páginasLibro - Programacion Cap12 MatricesJeshua PerezAún no hay calificaciones
- Resolver Ecuaciones Lineales y No LinealesDocumento26 páginasResolver Ecuaciones Lineales y No Linealeskillroy72Aún no hay calificaciones
- Gráficos por computadora bidimensionales: Explorando el ámbito visual: gráficos por computadora bidimensionales en visión por computadoraDe EverandGráficos por computadora bidimensionales: Explorando el ámbito visual: gráficos por computadora bidimensionales en visión por computadoraAún no hay calificaciones
- CretaDocumento2 páginasCretaGoro2002Aún no hay calificaciones
- Resolucion General #90Documento8 páginasResolucion General #90Goro2002Aún no hay calificaciones
- Cartilla Informativa Sobre El IRE GENERALDocumento6 páginasCartilla Informativa Sobre El IRE GENERALGoro2002Aún no hay calificaciones
- Resolucion General No 103 AnexoDocumento15 páginasResolucion General No 103 AnexoGoro2002Aún no hay calificaciones
- Especificaciones Técnicas para El Listado de Nóminas SalarialesDocumento113 páginasEspecificaciones Técnicas para El Listado de Nóminas SalarialesGoro2002Aún no hay calificaciones
- Resolución de Actualización #03-17Documento2 páginasResolución de Actualización #03-17Goro2002Aún no hay calificaciones
- Guía Paso A Paso - Software ARANDUKADocumento16 páginasGuía Paso A Paso - Software ARANDUKAAnonymous XILhORMAún no hay calificaciones
- Código de Actividades 2017Documento21 páginasCódigo de Actividades 2017Goro2002Aún no hay calificaciones
- Normas ElectoralesDocumento40 páginasNormas ElectoralesGoro2002Aún no hay calificaciones
- Manual James PDFDocumento29 páginasManual James PDFGoro2002Aún no hay calificaciones
- Resolucion 453/2011Documento18 páginasResolucion 453/2011Goro2002Aún no hay calificaciones
- Resolucion 453Documento18 páginasResolucion 453Goro2002Aún no hay calificaciones
- Ayuda+errores+Marangatu i+Win+Vista Seven 8Documento9 páginasAyuda+errores+Marangatu i+Win+Vista Seven 8Goro2002Aún no hay calificaciones
- CojinetesDocumento19 páginasCojinetesLuisTb100% (1)
- Linea Del Tiempo - Gestion AmbientalDocumento10 páginasLinea Del Tiempo - Gestion Ambientalyeni67% (3)
- Teoría Cinética de Los Gases IdealesDocumento3 páginasTeoría Cinética de Los Gases IdealesJorge Salas ChauAún no hay calificaciones
- Construcción de La FraseDocumento5 páginasConstrucción de La FraseKar ZAún no hay calificaciones
- Calculos de Diseno Camara de CargaDocumento6 páginasCalculos de Diseno Camara de CargaYanethAún no hay calificaciones
- Cuadro ComparativoDocumento3 páginasCuadro ComparativoAnell Chuquitucto100% (1)
- Temario Bienes y Derechos Reales PDFDocumento3 páginasTemario Bienes y Derechos Reales PDFLuis SandovalAún no hay calificaciones
- Estructura Orgánica No. OPA-XOCH-12-160719Documento26 páginasEstructura Orgánica No. OPA-XOCH-12-160719Ricardo González MedinaAún no hay calificaciones
- Aplicacion Jurisprudencial de La Doctrina de Las Cargas Probatorias DinamicasDocumento26 páginasAplicacion Jurisprudencial de La Doctrina de Las Cargas Probatorias DinamicaskarinaAún no hay calificaciones
- Seguridad MaquinaDocumento50 páginasSeguridad MaquinaGerardo Marcelo PizarroAún no hay calificaciones
- Abrasion de Agregados GruesoDocumento12 páginasAbrasion de Agregados GruesoA Ayrton A AHAún no hay calificaciones
- Normas ADIDocumento9 páginasNormas ADIjesus25diteAún no hay calificaciones
- Cómo Compilar El KernelDocumento5 páginasCómo Compilar El KernelVin_DieseltiestoAún no hay calificaciones
- Clase de Lectura Critica Mayo 26Documento6 páginasClase de Lectura Critica Mayo 26Maury BolivarAún no hay calificaciones
- Informe 6Documento5 páginasInforme 6stebanAún no hay calificaciones
- Planificación de Los Parámetros de Un ProyectoDocumento4 páginasPlanificación de Los Parámetros de Un ProyectoJonathan CoptoAún no hay calificaciones
- Examen Copia Primera ParcialDocumento10 páginasExamen Copia Primera ParcialE Leo Blanki AzvlAún no hay calificaciones
- PSL Compra de Oro CoomineralDocumento76 páginasPSL Compra de Oro CoomineralGUILERMO LEON JARAMILLO PATIÑOAún no hay calificaciones
- La Pronunciación de La - e Corta - y - e Larga - en Inglés - IngléDocumento9 páginasLa Pronunciación de La - e Corta - y - e Larga - en Inglés - IngléGraciela MaldonadoAún no hay calificaciones
- Leica Viva Manual GPSDocumento2 páginasLeica Viva Manual GPSEder Jime Mozo CastañedaAún no hay calificaciones
- CUTS - Clave Única de Tramites y Servicios PDFDocumento3 páginasCUTS - Clave Única de Tramites y Servicios PDFYaguen MacedoAún no hay calificaciones
- La Medicalización de La VidaDocumento4 páginasLa Medicalización de La VidaAngeles KumagaeAún no hay calificaciones
- Reglas Del IGTFDocumento6 páginasReglas Del IGTFGerente Administrativo100% (1)
- Prueba Saber MatematicasDocumento3 páginasPrueba Saber MatematicasAlexander Rangel HernandezAún no hay calificaciones
- Filosofia de La Educacion .: Martha Yadira Carolina Sotelo VillegasDocumento3 páginasFilosofia de La Educacion .: Martha Yadira Carolina Sotelo VillegasYadira SoteloAún no hay calificaciones