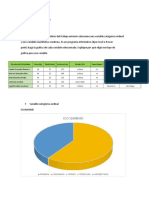
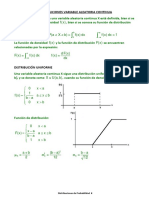
También podría gustarte
- ESTADiSTICA DESCRIPTIVADocumento128 páginasESTADiSTICA DESCRIPTIVAiseram2007Aún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Sesion 6 Medidas de Dispersion 2018 IIDocumento30 páginasSesion 6 Medidas de Dispersion 2018 IIDavid EscobedoAún no hay calificaciones
- Medidas de DispersionDocumento19 páginasMedidas de DispersionRoberto Tirado Mendoza100% (2)
- Clase 3 - Comparación de Dos Medias Con Prueba TDocumento50 páginasClase 3 - Comparación de Dos Medias Con Prueba TFrancisca CalderónAún no hay calificaciones
- Analisis de Datos Cuantitativos Dra. AlvarezDocumento30 páginasAnalisis de Datos Cuantitativos Dra. AlvarezAnndy Choque ValenciaAún no hay calificaciones
- Tema 4 BioestDocumento43 páginasTema 4 BioestKatty BohorquezAún no hay calificaciones
- Estadística RESUMENDocumento62 páginasEstadística RESUMENDenisse AguirreAún no hay calificaciones
- DispersionyformaDocumento47 páginasDispersionyformaIgor Sadaba100% (1)
- Medidas de Tendencia CentralDocumento27 páginasMedidas de Tendencia Centralkeitlyn castilloAún no hay calificaciones
- Estadistica Aplicada y Pronostico ProyectoDocumento17 páginasEstadistica Aplicada y Pronostico ProyectoTellez ArielAún no hay calificaciones
- Tema 2 Estimación de ParámetrosDocumento41 páginasTema 2 Estimación de ParámetrosMeryori Santos MedinaAún no hay calificaciones
- Guia 2 de Aprendizaje Estadistica Grado.9Documento10 páginasGuia 2 de Aprendizaje Estadistica Grado.9facc27Aún no hay calificaciones
- Tesis 6 Medidas de Posición y VariabilidadDocumento21 páginasTesis 6 Medidas de Posición y VariabilidadHellen RiveraAún no hay calificaciones
- Ejemplos - Estadistica (Parte 2)Documento11 páginasEjemplos - Estadistica (Parte 2)Janni SantosAún no hay calificaciones
- 08 Curva NormalDocumento50 páginas08 Curva NormalGuerrera de LuzAún no hay calificaciones
- Despliegue de Datos PDFDocumento13 páginasDespliegue de Datos PDFJaneth ErasoAún no hay calificaciones
- Prob y EstadisticaDocumento5 páginasProb y EstadisticaKatty Sherlyn Ramos HernándezAún no hay calificaciones
- Documento de Cátedra Unidad 4 PDFDocumento9 páginasDocumento de Cátedra Unidad 4 PDFGuillermo Alexander Hernandez HernandezAún no hay calificaciones
- Unidad Curva Normal 2020Documento15 páginasUnidad Curva Normal 2020Vale ComasAún no hay calificaciones
- Inv Teo 6Documento22 páginasInv Teo 6kevin zurita riosAún no hay calificaciones
- TEMA 2 Herramientas de Tendencia CentralDocumento14 páginasTEMA 2 Herramientas de Tendencia CentralanahiescobaralanocaAún no hay calificaciones
- Tema 4: Parámetros Estadísticos: Ainhoa Romero Castillo Laura Marín MiraveteDocumento12 páginasTema 4: Parámetros Estadísticos: Ainhoa Romero Castillo Laura Marín MiraveteLaura Marín MiraveteAún no hay calificaciones
- Exposicion Sabado 20 Estadistica - Capitulo 3Documento25 páginasExposicion Sabado 20 Estadistica - Capitulo 3Gloricel EstevezAún no hay calificaciones
- Final EstadisticaDocumento4 páginasFinal EstadisticaGiulianaAún no hay calificaciones
- 1.-3capitulo 3. Descripción de Datos IIDocumento29 páginas1.-3capitulo 3. Descripción de Datos IIManuel CamposAún no hay calificaciones
- Reporte de Teleclase 2 - EstadisticaDocumento6 páginasReporte de Teleclase 2 - EstadisticaIsanne Thomas AguirreAún no hay calificaciones
- Distribución NormalDocumento37 páginasDistribución NormalJavier RuaAún no hay calificaciones
- Fase 2 - Generalidades EstadísticasDocumento24 páginasFase 2 - Generalidades EstadísticasAna Maria Bernal Mora100% (1)
- Resumen Tema 5Documento9 páginasResumen Tema 5nereaAún no hay calificaciones
- EstadisticaDocumento8 páginasEstadisticaIvanova GonzálezAún no hay calificaciones
- EstadísticasDocumento13 páginasEstadísticasJunior HoppeAún no hay calificaciones
- Distribucion Muestral de La Media, Limite Central y Intervalo de ConfianzaDocumento59 páginasDistribucion Muestral de La Media, Limite Central y Intervalo de ConfianzaSebastian SalazarAún no hay calificaciones
- Expo-1. EstadísticaDocumento12 páginasExpo-1. EstadísticaPAOLA GRISELDA CASTILLO PAIZAún no hay calificaciones
- ESTADISTICA INFERENCIAL Tema2Documento14 páginasESTADISTICA INFERENCIAL Tema2carol viviana soliz ibañezAún no hay calificaciones
- S01.S1 - IC para La Media - Varianza ConocidaDocumento32 páginasS01.S1 - IC para La Media - Varianza ConocidaLelyLaBorrasha 2Aún no hay calificaciones
- Estadística en Química Analítica OKDocumento102 páginasEstadística en Química Analítica OKKARIMCHOAún no hay calificaciones
- INVESTIGACIÓNDocumento10 páginasINVESTIGACIÓNAnyi GarciaAún no hay calificaciones
- SolucionDocumento8 páginasSolucionJeisson Andrés Pinilla ReyesAún no hay calificaciones
- Universidad EstatalDocumento8 páginasUniversidad EstatalLlego el TommyAún no hay calificaciones
- Diapositiva 0Documento27 páginasDiapositiva 0EstebanAún no hay calificaciones
- EstadisticaDocumento73 páginasEstadisticaMatiasLugoAún no hay calificaciones
- Estadistica y Manejo de DatosDocumento35 páginasEstadistica y Manejo de DatosleosalleAún no hay calificaciones
- 3 Estadi - Sticos+descriptivosDocumento38 páginas3 Estadi - Sticos+descriptivosArroyo Martínez José GabrielAún no hay calificaciones
- Medidas de Tendencia CentralDocumento2 páginasMedidas de Tendencia CentralKimberly Castro67% (3)
- Material 2023F1 MED215 01 248384Documento20 páginasMaterial 2023F1 MED215 01 248384genesisAún no hay calificaciones
- Desviación Estándar (Autoguardado) PDFDocumento15 páginasDesviación Estándar (Autoguardado) PDFHuesos GamerAún no hay calificaciones
- EST INFO Unidad 1 Estadística DescriptivaDocumento37 páginasEST INFO Unidad 1 Estadística DescriptivaSebastian VazquezAún no hay calificaciones
- Unidad 3. PuntuaciónDocumento5 páginasUnidad 3. PuntuaciónPao RacighAún no hay calificaciones
- Reporte Estadistica 2Documento9 páginasReporte Estadistica 2ncampos311298Aún no hay calificaciones
- Estadística DescriptivaDocumento4 páginasEstadística DescriptivaGabriel Hurtado LópezAún no hay calificaciones
- Valores Z y La Regla EmpiricaDocumento5 páginasValores Z y La Regla EmpiricaKelvyn TeleguarioAún no hay calificaciones
- Estadistica DescriptivaDocumento33 páginasEstadistica DescriptivaMarcelo RojasAún no hay calificaciones
- Estadistica 2Documento69 páginasEstadistica 2SanchoAún no hay calificaciones
- Media Moda EstadisticaDocumento9 páginasMedia Moda EstadisticaJoan Manuel ZabalaAún no hay calificaciones
- Tema4 LA INFERENCIA ESTADISTICA Y EL CONTRASTE DE HIPOTESISDocumento13 páginasTema4 LA INFERENCIA ESTADISTICA Y EL CONTRASTE DE HIPOTESISLivi ManzanoAún no hay calificaciones
- Probabilidad y EstadisticaDocumento6 páginasProbabilidad y EstadisticaUltimateBuld399Aún no hay calificaciones
- 3.3. Teorema ChebyshevDocumento7 páginas3.3. Teorema Chebyshevbladimir.mejiahernandezAún no hay calificaciones
- Nccu-202 FormatoalumnotrabajofinalDocumento11 páginasNccu-202 FormatoalumnotrabajofinalKaren HCAún no hay calificaciones
- INVESTIGACIÓNDocumento60 páginasINVESTIGACIÓNlasalashAún no hay calificaciones
- Matematica Semana 28Documento12 páginasMatematica Semana 28Cabanillas AguilarAún no hay calificaciones
- Tatea 5 de EstadisticaDocumento10 páginasTatea 5 de EstadisticaLeonel Dur�n S�nchezAún no hay calificaciones
- Estadistica Aplicada TeoriaDocumento422 páginasEstadistica Aplicada TeoriaJOSÉ EDUARDOAún no hay calificaciones
- Clase 14-Control Estadístico de Procesos-Modelos Probabilisticos Io IIDocumento10 páginasClase 14-Control Estadístico de Procesos-Modelos Probabilisticos Io IIJOSE FERNANDO MUGURUZA VASQUEZAún no hay calificaciones
- 1.4 Distribuciones Fundamentales para El MuestreoDocumento8 páginas1.4 Distribuciones Fundamentales para El MuestreoLuis Antonio Diaz RomeroAún no hay calificaciones
- Guia 09 TDS115Documento2 páginasGuia 09 TDS115AlejandroMendezAún no hay calificaciones
- Est. de ParametrosDocumento8 páginasEst. de ParametrosCelene Alanis PerezAún no hay calificaciones
- Distribuciones Muéstrales ExposicionDocumento10 páginasDistribuciones Muéstrales Exposicionمالوريك موديراAún no hay calificaciones
- Estadistica ComercialDocumento8 páginasEstadistica ComercialBenjamin ByrAún no hay calificaciones
- Silabo Inferencia Estadistica (2021 A)Documento6 páginasSilabo Inferencia Estadistica (2021 A)Edward ZarateAún no hay calificaciones
- Estad Descrip Tallos y Hojas Promedio AritmeticoDocumento44 páginasEstad Descrip Tallos y Hojas Promedio AritmeticoYou KikaAún no hay calificaciones
- Distribucio Hipergeométrica EstadisticaDocumento17 páginasDistribucio Hipergeométrica EstadisticaDulce ArismendyAún no hay calificaciones
- Parcial3 PYE Ago 2021 IC v4Documento4 páginasParcial3 PYE Ago 2021 IC v4Akari Tuz GarcíaAún no hay calificaciones
- Estadistica Aplicada PrevencionDocumento20 páginasEstadistica Aplicada PrevencionJhonny GHAún no hay calificaciones
- Tarea Uno-Tercer ParcialDocumento5 páginasTarea Uno-Tercer ParcialRicardo MuñozAún no hay calificaciones
- Factores y NivelesDocumento5 páginasFactores y NivelesAlejandro Vargas0% (1)
- Regresión Lineal SimpleDocumento27 páginasRegresión Lineal SimpleEnzo GonzalesAún no hay calificaciones
- Taller - Introduccion A Los PronosticosDocumento4 páginasTaller - Introduccion A Los PronosticosJorge AlfonsoAún no hay calificaciones
- Trabajo GrupalDocumento7 páginasTrabajo GrupalnatanaelAún no hay calificaciones
- Apoyo Prueba 1 Estadistica Aplicada PDFDocumento52 páginasApoyo Prueba 1 Estadistica Aplicada PDFMaikel RamirezAún no hay calificaciones
- Tema3. Medidas de Tendencia Central - PARCIALDocumento21 páginasTema3. Medidas de Tendencia Central - PARCIALPriscila LuceroAún no hay calificaciones
- Examen T2 Tecnologia Aplicada - VirtualDocumento8 páginasExamen T2 Tecnologia Aplicada - VirtualJeicy HcAún no hay calificaciones
- Taller Estadistica Basica A La Guia ClaudiaDocumento17 páginasTaller Estadistica Basica A La Guia ClaudiaBibiana ReyesAún no hay calificaciones
- Distribución Muestral de MediasDocumento4 páginasDistribución Muestral de MediasrdsilvaAún no hay calificaciones
- Clasificación de Variables - UNSA - TelecomunicacionesDocumento6 páginasClasificación de Variables - UNSA - TelecomunicacionesPaul Fernando Porcel FelipeAún no hay calificaciones
- C.C MatemáticasDocumento40 páginasC.C Matemáticasedna mendez sanchezAún no hay calificaciones
- Semana 01-01Documento17 páginasSemana 01-01yovany manrique ramosAún no hay calificaciones
- Estadística Ii: Universidad de La RepúblicaDocumento3 páginasEstadística Ii: Universidad de La RepúblicaAlvaro CamañoAún no hay calificaciones
- Funciones - Por Categorías - en ExcelDocumento11 páginasFunciones - Por Categorías - en ExcelDavid Paz BordaAún no hay calificaciones