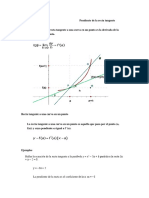
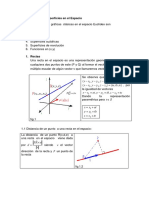
También podría gustarte
- Sistemas MultivariableDocumento34 páginasSistemas MultivariableMidwar ValenciaAún no hay calificaciones
- Adicionales Ampliaciones de Plazo EnfermedadDocumento14 páginasAdicionales Ampliaciones de Plazo EnfermedadJean Nahuamel DelgadoAún no hay calificaciones
- Problemas de LGRDocumento5 páginasProblemas de LGRMidwar ValenciaAún no hay calificaciones
- Diseño de ControladoresDocumento89 páginasDiseño de ControladoresMidwar ValenciaAún no hay calificaciones
- Yolanda GuerraDocumento3 páginasYolanda GuerraMidwar ValenciaAún no hay calificaciones
- Historia GloriaDocumento5 páginasHistoria GloriaMidwar ValenciaAún no hay calificaciones
- Con A VanDocumento473 páginasCon A VanRigan Eloy Pérez PacoriAún no hay calificaciones
- Integrales Por Sustitucion TrigonometricaDocumento17 páginasIntegrales Por Sustitucion TrigonometricaEsteven MolinaAún no hay calificaciones
- Guia Didactica 7mo Numeros Racionales 1Documento8 páginasGuia Didactica 7mo Numeros Racionales 1Jaiker Jesus Sira PeñaAún no hay calificaciones
- A MatricesDocumento4 páginasA Matricestonysolis202220Aún no hay calificaciones
- Convergencia Del Método de JacobiDocumento5 páginasConvergencia Del Método de JacobiFreddy Chuquipuma PumaAún no hay calificaciones
- Interpolacion de Terminos PDFDocumento2 páginasInterpolacion de Terminos PDFSF CesarAún no hay calificaciones
- Pendiente de La Recta TangenteDocumento9 páginasPendiente de La Recta TangenteJairo IsraelAún no hay calificaciones
- Ejercicios Resueltos Funciones Trigonométricas Inversas. 21-12-30.Documento4 páginasEjercicios Resueltos Funciones Trigonométricas Inversas. 21-12-30.Vladimil MellaAún no hay calificaciones
- Proyecto de ControlDocumento3 páginasProyecto de Controlbyron alaAún no hay calificaciones
- 7mo-Actividades - Esc 347Documento20 páginas7mo-Actividades - Esc 347SOLE NumbelatoAún no hay calificaciones
- Calculo de La DeterminanteDocumento11 páginasCalculo de La DeterminanteRenzoTRAún no hay calificaciones
- Prueba Angulos CircunferenciaDocumento6 páginasPrueba Angulos CircunferenciaFre Cuevas100% (1)
- Practica Metodos NumericosDocumento14 páginasPractica Metodos Numericoshastune RollAún no hay calificaciones
- Ecuaciones Diferenciales 2 Semestre Ingenieria CivilDocumento1 páginaEcuaciones Diferenciales 2 Semestre Ingenieria Civilkasandra guerreroAún no hay calificaciones
- 95 - Fase 4 - TrabajoDocumento14 páginas95 - Fase 4 - TrabajoJessika SuAlvaAún no hay calificaciones
- Series de FourierDocumento2 páginasSeries de Fourierel balletAún no hay calificaciones
- Sistema de Ecuaciones Parte 3Documento6 páginasSistema de Ecuaciones Parte 3Lau DancosoAún no hay calificaciones
- MÉTODO DEL PUNTO FIJO y NEWTON RAPHSONDocumento34 páginasMÉTODO DEL PUNTO FIJO y NEWTON RAPHSONThomas Romero100% (1)
- Actividad2 Algebra LinealDocumento4 páginasActividad2 Algebra LinealMARIO ANDRES RODRIGUEZ LEONAún no hay calificaciones
- Aritmética Cepre-UniDocumento2 páginasAritmética Cepre-UniPaulo Cesar Carhuancho Vera0% (4)
- BD - Taller3 - Rojas - SharonDocumento27 páginasBD - Taller3 - Rojas - SharonValentina RojasAún no hay calificaciones
- Practica Unidad No 04 y 05 - Matematica Basica - Septiembre - Diciembre 2021Documento5 páginasPractica Unidad No 04 y 05 - Matematica Basica - Septiembre - Diciembre 2021francis vilorioAún no hay calificaciones
- Superficies en El EspacioDocumento10 páginasSuperficies en El EspacioDany CéspedesAún no hay calificaciones
- Diapositiva DecimalesDocumento11 páginasDiapositiva DecimalesCesar DpqAún no hay calificaciones
- Secuencia DidácticaDocumento18 páginasSecuencia DidácticaCarlos Alfredo LópezAún no hay calificaciones
- Pa3 Algebra MatricialDocumento10 páginasPa3 Algebra MatricialJOE MARINO LUNA CABRERAAún no hay calificaciones
- Guia # 2 - 2P Algebra NovenoDocumento5 páginasGuia # 2 - 2P Algebra NovenoXavier TafurAún no hay calificaciones
- Tdeyu - TggiDocumento7 páginasTdeyu - TggiJuNiiOR 582Aún no hay calificaciones
- Control Introduccion Discreto V3 PDFDocumento23 páginasControl Introduccion Discreto V3 PDFDiana CienduaAún no hay calificaciones
- Analisis IvDocumento24 páginasAnalisis IvYohn Quispe RodriguezAún no hay calificaciones
- 20 Tema 52Documento13 páginas20 Tema 52Concha Pereira Hernández100% (1)