También podría gustarte
- La Palabra SilenciadaDocumento512 páginasLa Palabra SilenciadaMaría Clara100% (1)
- c3d277 - Guía de Estudio Unidad 1 - Parte 1 (Historia)Documento7 páginasc3d277 - Guía de Estudio Unidad 1 - Parte 1 (Historia)Lupe CarreraAún no hay calificaciones
- Tarea 3 de Contabilidad 5Documento10 páginasTarea 3 de Contabilidad 5Johanny Reyes BonillaAún no hay calificaciones
- Informe Final - MarketingDocumento28 páginasInforme Final - Marketingbruno rodriguezAún no hay calificaciones
- Apunte Funciones Por TramosDocumento4 páginasApunte Funciones Por TramosBERYLL ZICARELLIAún no hay calificaciones
- Cap 3 DeshidratacionDocumento107 páginasCap 3 DeshidratacionAdemar Cruz MancillaAún no hay calificaciones
- Fisica-Taller Prueba Saber 11°Documento14 páginasFisica-Taller Prueba Saber 11°Breyner Joel Ortiz DiazAún no hay calificaciones
- AzucenaDocumento2 páginasAzucenaGabriela Fierro CarlosAún no hay calificaciones
- Manual Lección Luz de VidaDocumento16 páginasManual Lección Luz de VidaSuzana FernandesAún no hay calificaciones
- Semiótica de La MúsicaDocumento5 páginasSemiótica de La MúsicaCristina CondeAún no hay calificaciones
- Ejemplos de Arreglos UnidimencionalesDocumento3 páginasEjemplos de Arreglos Unidimencionalesjer86Aún no hay calificaciones
- La Personalidad Juridica de La Sucesión Hereditaria Indivisa y Sus Implicaciones en El Derecho Civil y Derecho TributarioDocumento14 páginasLa Personalidad Juridica de La Sucesión Hereditaria Indivisa y Sus Implicaciones en El Derecho Civil y Derecho TributariosegurahAún no hay calificaciones
- Masaje ShiatsuDocumento4 páginasMasaje ShiatsualexcerroblancoAún no hay calificaciones
- Bonifacio Sotos Ochando - Compendio de La Lengua Universal (1885)Documento191 páginasBonifacio Sotos Ochando - Compendio de La Lengua Universal (1885)CarlosJesusAún no hay calificaciones
- Proyecto de Investigacion (Trabajo Final)Documento37 páginasProyecto de Investigacion (Trabajo Final)javier sangeadoAún no hay calificaciones
- Manual de Eval de DesempeñoDocumento20 páginasManual de Eval de DesempeñoestefnypolorAún no hay calificaciones
- Tesis FORESTAL PDFDocumento71 páginasTesis FORESTAL PDFReynaldo LPAún no hay calificaciones
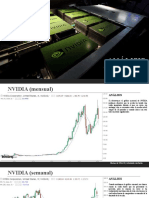
- Estrategia de Inversión Nvidia CorpDocumento11 páginasEstrategia de Inversión Nvidia CorpLuis Miguel Hurtado MayaAún no hay calificaciones
- Informe 3 - Circuitos 3Documento6 páginasInforme 3 - Circuitos 3Daniel J. LopezAún no hay calificaciones
- LepandaDocumento5 páginasLepandaJuan Pablo Macias CAún no hay calificaciones
- Trabajo de FutbolDocumento27 páginasTrabajo de FutbolMartha Elena0% (1)
- Actividad Evaluable (A2) Sistema de Informacion Milagros GaleppiDocumento5 páginasActividad Evaluable (A2) Sistema de Informacion Milagros GaleppiRoxanaAún no hay calificaciones
- PPTTO 02 Aulas VIÑAUYA + SS - HH.Documento167 páginasPPTTO 02 Aulas VIÑAUYA + SS - HH.JACK RONCALAún no hay calificaciones
- David TeniersDocumento5 páginasDavid TeniersAlejandro DoménechAún no hay calificaciones
- G. Bañuls Tesis M TeóricoDocumento42 páginasG. Bañuls Tesis M TeóricoStgo NdAún no hay calificaciones
- Avances de Tesis UtrcDocumento12 páginasAvances de Tesis Utrcdavid arturo oriz rdzAún no hay calificaciones
- Diseño de Un Autómata Con Transiciones VacíasDocumento3 páginasDiseño de Un Autómata Con Transiciones VacíasLeydi Euan Martinez100% (2)
- Clasificaciones Con WekaDocumento15 páginasClasificaciones Con WekaveraluzmgAún no hay calificaciones
- Liderazgo e InnovaciónDocumento38 páginasLiderazgo e InnovaciónIan Dnvn VrtdlAún no hay calificaciones
- Escalera en EspañolDocumento1 páginaEscalera en EspañolMarcos Amador AlbaAún no hay calificaciones