También podría gustarte
- Preludium - Johann Sebastian BachDocumento3 páginasPreludium - Johann Sebastian BachVíctor VargasAún no hay calificaciones
- Ej. Resueltos P3 (2da Parte)Documento6 páginasEj. Resueltos P3 (2da Parte)erikAún no hay calificaciones
- Es NavidadDocumento2 páginasEs NavidadDiego CondeAún no hay calificaciones
- El Danzarin Del SolDocumento4 páginasEl Danzarin Del SolJuan Méndez LopezAún no hay calificaciones
- 01 - Anexo ChacatoDocumento1 página01 - Anexo ChacatoCiro ValdezAún no hay calificaciones
- Reporte Valores de SensorDocumento1 páginaReporte Valores de SensorRAUL GONSALESAún no hay calificaciones
- RumbleDocumento1 páginaRumbleNarfindor MéndezAún no hay calificaciones
- El Condor PasaDocumento2 páginasEl Condor PasaJan MictuAún no hay calificaciones
- 05 - Fast Track - 4Documento1 página05 - Fast Track - 4ozyAún no hay calificaciones
- Et LM 103 No PavimentadoDocumento106 páginasEt LM 103 No PavimentadoJessy Espinoza SalasAún no hay calificaciones
- Curvas para determinar el tirante normal en hidráulica de tuberías y canalesDocumento1 páginaCurvas para determinar el tirante normal en hidráulica de tuberías y canalesChristianAún no hay calificaciones
- Alcantarillas Tramo I - Del 5+930 Al 8+684Documento19 páginasAlcantarillas Tramo I - Del 5+930 Al 8+684Moises del AguilaAún no hay calificaciones
- Planta de trazado de carretera de 1/2.000Documento1 páginaPlanta de trazado de carretera de 1/2.000RICHARD PADILLA TOCTOAún no hay calificaciones
- 00capilla - Planos Modificados-A-1Documento1 página00capilla - Planos Modificados-A-1LUIS ADOLFO REATEGUI MORIAún no hay calificaciones
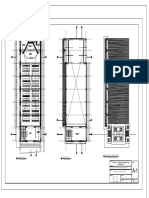
- Plano de planta de edificioDocumento16 páginasPlano de planta de edificioWilder R. Flores QuezadaAún no hay calificaciones
- Plano - Distribuidor InferiorDocumento1 páginaPlano - Distribuidor InferiorYeison Benites GuzmanAún no hay calificaciones
- Billie Jean Uke 3Documento2 páginasBillie Jean Uke 3Matías GarcíaAún no hay calificaciones
- El Vito-TabDocumento1 páginaEl Vito-TabHarry Jones100% (1)
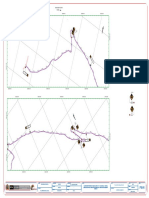
- Plano de PtarDocumento1 páginaPlano de PtarJoprAún no hay calificaciones
- Evaluacion de Entrada 2021-00Documento3 páginasEvaluacion de Entrada 2021-00José Patiño RodriguezAún no hay calificaciones
- Nota de Entrada de CementosDocumento3 páginasNota de Entrada de CementosLuis PerezAún no hay calificaciones
- Diagrama Psicrometrico Pendiente H WDocumento1 páginaDiagrama Psicrometrico Pendiente H WGabriel Jonas Martel HernandezAún no hay calificaciones
- Bochica Cuarteto-Bajo - Electrico - (Tablatura)Documento1 páginaBochica Cuarteto-Bajo - Electrico - (Tablatura)Juanka RikkoAún no hay calificaciones
- Tab DesperadoDocumento4 páginasTab Desperadoalireza babaei100% (1)
- Noche de Paz + TABDocumento1 páginaNoche de Paz + TABandrea100% (5)
- Guia Numeros Hasta El 100Documento3 páginasGuia Numeros Hasta El 100Elizabeth Carvajal100% (1)
- ExamenC2 - Analisis EstructuralDocumento4 páginasExamenC2 - Analisis EstructuralEduardo DionisioAún no hay calificaciones
- El Aguacate - Pasillo EcuatorianoDocumento2 páginasEl Aguacate - Pasillo EcuatorianoFatino Rich HardtAún no hay calificaciones
- Conexion PLC Secadora de Yuca SDocumento1 páginaConexion PLC Secadora de Yuca SAnonymous aFdwmEyAún no hay calificaciones
- Flautas de lavado de telas -Documento1 páginaFlautas de lavado de telas -nicolas oliveroAún no hay calificaciones
- Marca TIL 19-11-22Documento40 páginasMarca TIL 19-11-22Milito LeftAún no hay calificaciones
- El Bimbo TabDocumento2 páginasEl Bimbo TabApollo Nieves HiladoAún no hay calificaciones
- Currículum ClásicoDocumento1 páginaCurrículum ClásicorobertoespressoAún no hay calificaciones
- 120 A Introducción: Standard TuningDocumento2 páginas120 A Introducción: Standard TuningAlejandro González HernándezAún no hay calificaciones
- Guía de Planificación de Mi Grupo-EDITDocumento1 páginaGuía de Planificación de Mi Grupo-EDITMagui SerriAún no hay calificaciones
- Rodolfo el Reno en Sol MayorDocumento2 páginasRodolfo el Reno en Sol MayorAntonio HernándezAún no hay calificaciones
- Rodolfo el Reno en Sol MayorDocumento2 páginasRodolfo el Reno en Sol MayorAntonio Hernández100% (1)
- Rodolfo El RenoDocumento2 páginasRodolfo El RenoAntonio Hernández100% (1)
- Estudiantina Madrileña GuitarraDocumento14 páginasEstudiantina Madrileña GuitarraOscar Leonardo Molina SierraAún no hay calificaciones
- Parametros MorfometricosDocumento9 páginasParametros MorfometricosROJAS URRUTIA HUGO WILMERAún no hay calificaciones
- Plano Eje PrincipalDocumento1 páginaPlano Eje PrincipalgluzardoAún no hay calificaciones
- P-Cv-Hl-15-Relleno Estructural-9Documento1 páginaP-Cv-Hl-15-Relleno Estructural-9Jhon SilesAún no hay calificaciones
- Himne Del Barça UkuleleDocumento1 páginaHimne Del Barça UkuleleAdrià Barranco FernándezAún no hay calificaciones
- Tuna Compostelana GuitarraDocumento1 páginaTuna Compostelana GuitarrasimeticonaAún no hay calificaciones
- Formato Guardias Enfermeras Periodo 2023Documento1 páginaFormato Guardias Enfermeras Periodo 2023JielAún no hay calificaciones
- Plano UbicaciónDocumento1 páginaPlano Ubicacióntelekinesis23Aún no hay calificaciones
- Prado A 2023-PlantaDocumento1 páginaPrado A 2023-PlantaELIU JOSUE PULIDO PEREIRAAún no hay calificaciones
- FormatoDocumento3 páginasFormatoDidier Urrutia MosqueraAún no hay calificaciones
- 4° EscrituraDocumento6 páginas4° EscrituraNadia ChavezAún no hay calificaciones
- Programador de ContenidosDocumento3 páginasProgramador de ContenidosJuan David Corrales AranaAún no hay calificaciones
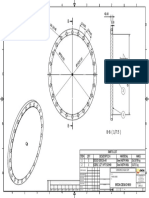
- Brida Ciega DN800Documento1 páginaBrida Ciega DN800jarryAún no hay calificaciones
- Casa 1-1 MecanicaDocumento1 páginaCasa 1-1 MecanicaSamuel Eulises Peraza ArangoAún no hay calificaciones
- Diseño de RotopalaDocumento16 páginasDiseño de RotopalaJhoseph La FuenteAún no hay calificaciones
- CANCION - Yvonne BloorDocumento1 páginaCANCION - Yvonne BloorAg MorenoAún no hay calificaciones
- Geo Pa 07Documento1 páginaGeo Pa 07susualanya72Aún no hay calificaciones
- BuzonesDocumento1 páginaBuzonesLuis Meza RomeroAún no hay calificaciones
- Let It Be Guit 5Documento1 páginaLet It Be Guit 5Mafalda MagalhãesAún no hay calificaciones
- Aconcagua - GuitarraDocumento1 páginaAconcagua - GuitarraDanielYefeHernándezAún no hay calificaciones
- CV ClásicoDocumento1 páginaCV ClásicoYoAún no hay calificaciones
- Unidad 2. Exploraciòn y Muestreo de SuelosDocumento15 páginasUnidad 2. Exploraciòn y Muestreo de SuelosDaniel MirandaAún no hay calificaciones
- Estadistica 2Documento5 páginasEstadistica 2Gianfranco Sumozo100% (1)
- 2 Formato de Tesis Orlando SamaniegoDocumento56 páginas2 Formato de Tesis Orlando SamaniegoJuan Moisés Alvarez PalominoAún no hay calificaciones
- Estadistica Basica 2010 LibroDocumento164 páginasEstadistica Basica 2010 LibroJuan David HerreraAún no hay calificaciones
- Espiral CientificoDocumento5 páginasEspiral CientificoDiego AndradeAún no hay calificaciones
- Kriging Con Deriva de GeoestadisticaDocumento25 páginasKriging Con Deriva de GeoestadisticaMichael Elvis QuispeAún no hay calificaciones
- Analisis de Auditoria OperacionalDocumento13 páginasAnalisis de Auditoria OperacionalNohelia Pilcomayo PlataAún no hay calificaciones
- Tipos de Análisis de RegresiónDocumento4 páginasTipos de Análisis de RegresiónCarolinaAún no hay calificaciones
- Guia 1 P2 Grado 7 2021 Tablas de Frecuencia y Unidades de LongitudDocumento4 páginasGuia 1 P2 Grado 7 2021 Tablas de Frecuencia y Unidades de Longitudglenda bravoAún no hay calificaciones
- Enfoque de La InvestigaciónDocumento7 páginasEnfoque de La InvestigaciónhaloAún no hay calificaciones
- Partículas Magnéticas - Piñon PDFDocumento4 páginasPartículas Magnéticas - Piñon PDFpamelataboadalozanoAún no hay calificaciones
- Gestión máquinas industrialesDocumento6 páginasGestión máquinas industrialesYisusAún no hay calificaciones
- Regresión lineal y probabilidadDocumento4 páginasRegresión lineal y probabilidadStiven ValderramaAún no hay calificaciones
- Auditoria de SistemasDocumento10 páginasAuditoria de SistemasMaría Claudia RodriguezAún no hay calificaciones
- Diseño de Investigacion ExploratoriaDocumento16 páginasDiseño de Investigacion ExploratoriaSofía CristanchoAún no hay calificaciones
- Clases Del 23 Al 27 de Agosto 7mo AñoDocumento2 páginasClases Del 23 Al 27 de Agosto 7mo AñoLorenaAún no hay calificaciones
- Liliana: Autor: Tar - (ZonaDocumento129 páginasLiliana: Autor: Tar - (ZonaJulio C. Sierra PalominoAún no hay calificaciones
- 01.-Carta Gantt Aplicación Suseso Istas 21 RECICLAJEDocumento1 página01.-Carta Gantt Aplicación Suseso Istas 21 RECICLAJEJose Hernan Cheuque Salinas50% (2)
- Trabajo Final .5Documento37 páginasTrabajo Final .5forest windAún no hay calificaciones
- 2019 Estrategias Crecimiento CompetitividadDocumento55 páginas2019 Estrategias Crecimiento CompetitividadYina PatronAún no hay calificaciones
- Riesgos calculados y aceptación de incertidumbre en emprendimientosDocumento8 páginasRiesgos calculados y aceptación de incertidumbre en emprendimientosLady Rodriguez100% (1)
- Examen - (AAB01) Cuestionario 2 - Responda El Cuestionario 2 Sobre La Confiablidad y Validez de Los TestsDocumento4 páginasExamen - (AAB01) Cuestionario 2 - Responda El Cuestionario 2 Sobre La Confiablidad y Validez de Los Testsisrael idrovoAún no hay calificaciones
- Malhotra Mr05 PPT 11Documento40 páginasMalhotra Mr05 PPT 11Meny ChaviraAún no hay calificaciones
- Informe KPIDocumento10 páginasInforme KPIMatias Ricardo Alarcon MolinaAún no hay calificaciones
- La Inteligencia Emocional y Su Influencia en La Gestión Personal y Productiva de Los MicroempresariosDocumento9 páginasLa Inteligencia Emocional y Su Influencia en La Gestión Personal y Productiva de Los MicroempresariosEristefyAún no hay calificaciones
- Unidad II Metodos EstadisticosDocumento19 páginasUnidad II Metodos EstadisticosRosalbaMendezAún no hay calificaciones
- Definiciones Básicas en Programación LinealDocumento23 páginasDefiniciones Básicas en Programación Linealjorgehernandezh100% (2)
- ET123 - 3 GPA1111 - (ET - Teìcnico)Documento5 páginasET123 - 3 GPA1111 - (ET - Teìcnico)YARI NADIELLE RIASCOS HERNANDEZAún no hay calificaciones
- Investigación e Innovación I Versión Final Febrero 2014Documento17 páginasInvestigación e Innovación I Versión Final Febrero 2014Roxana MarcanoAún no hay calificaciones
- Municipios Del Valle Del Cauca: Encuesta PolíticaDocumento4 páginasMunicipios Del Valle Del Cauca: Encuesta PolíticaCARLOS FERNANDO GONZALEZ GUERREROAún no hay calificaciones