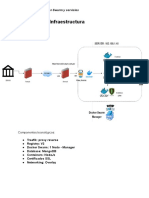
También podría gustarte
- Compilador C CCS y Simulador Proteus para Microcontroladores PICDe EverandCompilador C CCS y Simulador Proteus para Microcontroladores PICCalificación: 2.5 de 5 estrellas2.5/5 (5)
- Entrega 3 Sist - DistribuidosDocumento10 páginasEntrega 3 Sist - DistribuidosSebastián MontealegreAún no hay calificaciones
- Processing: Desarrollo de interfaces de usuario, aplicaciones de visión artificial e IoT para Arduino y ESP8266De EverandProcessing: Desarrollo de interfaces de usuario, aplicaciones de visión artificial e IoT para Arduino y ESP8266Calificación: 5 de 5 estrellas5/5 (1)
- Visión ArtificialDocumento13 páginasVisión ArtificialAlvarezz Ana MariaAún no hay calificaciones
- UF1249 - Programación del proyecto audiovisual multimediaDe EverandUF1249 - Programación del proyecto audiovisual multimediaAún no hay calificaciones
- Manual Del ProgramadorDocumento11 páginasManual Del ProgramadorLuis FelipeAún no hay calificaciones
- 22 Práctica Docker Compose Mean StackDocumento12 páginas22 Práctica Docker Compose Mean StackBrando Jahir Toma la VincesAún no hay calificaciones
- Seguimiento de Personas, Animales y Objetos Con OpenCV en Delphi - Delphi MagicDocumento5 páginasSeguimiento de Personas, Animales y Objetos Con OpenCV en Delphi - Delphi MagicJeremiah MartinezAún no hay calificaciones
- LibreriasDocumento13 páginasLibreriasLuis Fernando MaronAún no hay calificaciones
- Tutorial API REST Con Python y FlaskDocumento8 páginasTutorial API REST Con Python y FlaskEmmanuel RodriguezAún no hay calificaciones
- Documentacion SwarmDocumento8 páginasDocumentacion SwarmJorge Luis Villavicencio MezaAún no hay calificaciones
- DocumenyguyftDocumento18 páginasDocumenyguyftHelen OtisAún no hay calificaciones
- Angular Typescript PDFDocumento250 páginasAngular Typescript PDFGerardo MartinezAún no hay calificaciones
- Informe Procesamiento de ImagenesDocumento11 páginasInforme Procesamiento de ImagenesAngel Rosendo Condori CoaquiraAún no hay calificaciones
- SQL Proyecto de Lecturas para Base de DatosDocumento44 páginasSQL Proyecto de Lecturas para Base de DatosAlejandro BeltranAún no hay calificaciones
- Examen SO FDI UCM Junio-2022Documento7 páginasExamen SO FDI UCM Junio-2022Nacho N S KAún no hay calificaciones
- Control Lectura CUDA Felipe RiañoDocumento10 páginasControl Lectura CUDA Felipe RiañoDavid LeonAún no hay calificaciones
- Problemas Alumnos 2021Documento48 páginasProblemas Alumnos 2021adrianzgz10Aún no hay calificaciones
- Practicas RealizadasDocumento28 páginasPracticas RealizadasRaysha Ross Enciso RaveloAún no hay calificaciones
- Practica 1Documento5 páginasPractica 1Gabriel Martínez RodríguezAún no hay calificaciones
- Plantilla Paso4Documento31 páginasPlantilla Paso4EddieAún no hay calificaciones
- Manuscript Numbers With openCV PDFDocumento13 páginasManuscript Numbers With openCV PDFAlberto IztatikAún no hay calificaciones
- CD07 EjMPI PDFDocumento35 páginasCD07 EjMPI PDFRamón FernandezAún no hay calificaciones
- Manual Expresiones RegularesDocumento21 páginasManual Expresiones RegulareslopgreAún no hay calificaciones
- Prueba ApliicacionesDocumento10 páginasPrueba ApliicacionesGabriela_MorilloAún no hay calificaciones
- Lab 05Documento9 páginasLab 05jorge.silva.yAún no hay calificaciones
- Lab 05Documento7 páginasLab 05leonardo guzmanAún no hay calificaciones
- SOS-Practica 3 RGarciaCarmona 2014Documento11 páginasSOS-Practica 3 RGarciaCarmona 2014EDENY SHARON FERNANDEZ QUISPEAún no hay calificaciones
- Lab 05Documento8 páginasLab 05jorge.silva.yAún no hay calificaciones
- Geant 4Documento37 páginasGeant 4RoyerAún no hay calificaciones
- 7 Molinux Aplicaciones EducativasDocumento34 páginas7 Molinux Aplicaciones EducativasgeolliurexAún no hay calificaciones
- Resumen Cursos PlatziDocumento4 páginasResumen Cursos Platzijesus villegas galvanAún no hay calificaciones
- Curso WxpythonDocumento41 páginasCurso WxpythonvaleriaehAún no hay calificaciones
- C4A Libro3Documento46 páginasC4A Libro3VMSPAún no hay calificaciones
- Lab 02Documento17 páginasLab 02leonardo guzmanAún no hay calificaciones
- Practica1 ACDocumento9 páginasPractica1 ACFrancisco Sanchez MolineroAún no hay calificaciones
- Práctica No.30 Node - JS, ESP32, Comunicación Serial, Mysql y Sensor LM35 - NuevoDocumento12 páginasPráctica No.30 Node - JS, ESP32, Comunicación Serial, Mysql y Sensor LM35 - NuevoXchel Adrian Hernandez AlvarezAún no hay calificaciones
- Practica AXSO 2022 1 CASDocumento15 páginasPractica AXSO 2022 1 CASMiguel Ángel Luján PrietoAún no hay calificaciones
- Guia Implementacion de Base de Datos Laravel 8Documento7 páginasGuia Implementacion de Base de Datos Laravel 8Jonel Albert Correa CotrinaAún no hay calificaciones
- Manual Expresiones Regulares-AdfDocumento28 páginasManual Expresiones Regulares-Adfmauro_carreroAún no hay calificaciones
- Integrantes Del Grupo 17:: Tania Pachuca Solares Ventura Meza MartínezDocumento28 páginasIntegrantes Del Grupo 17:: Tania Pachuca Solares Ventura Meza Martíneztaniapachuca9Aún no hay calificaciones
- OpenStack Introduccion A DockerDocumento32 páginasOpenStack Introduccion A DockerErika Apaza VilcaAún no hay calificaciones
- Proyecto Sistemas Operacionales Distribuidos-20191-1Documento4 páginasProyecto Sistemas Operacionales Distribuidos-20191-1Angel Yesid Cardozo LopezAún no hay calificaciones
- P4 RPCDocumento8 páginasP4 RPCRoyroy Ram RubAún no hay calificaciones
- Test Gestión Operativa - Básico (Voolkia)Documento2 páginasTest Gestión Operativa - Básico (Voolkia)Luis CarvajalAún no hay calificaciones
- 4 Saxpy PDFDocumento3 páginas4 Saxpy PDFzhero7Aún no hay calificaciones
- Creación de API REST NodeJS - TypeScript - MongoDB - MongooseDocumento12 páginasCreación de API REST NodeJS - TypeScript - MongoDB - MongooseMauricio Josué AreasAún no hay calificaciones
- Requisitos de Los Escenarios para Realización de Las PrácticasDocumento5 páginasRequisitos de Los Escenarios para Realización de Las PrácticasMiguel GlezAún no hay calificaciones
- PHP Toolkit IBM I en Codeigniter PDFDocumento5 páginasPHP Toolkit IBM I en Codeigniter PDFHenry ArelaAún no hay calificaciones
- Prueba Tecnica LinuxDocumento6 páginasPrueba Tecnica LinuxTatiana PalaciosAún no hay calificaciones
- Notas Interconectividad LenguajesDocumento27 páginasNotas Interconectividad LenguajesMiguel HRAún no hay calificaciones
- MYMSE Doxygen Basico v2 0Documento22 páginasMYMSE Doxygen Basico v2 0Mauricio SalamancaAún no hay calificaciones
- Proycto de Sistemas Distribuidos 2020-2-1 PDFDocumento5 páginasProycto de Sistemas Distribuidos 2020-2-1 PDFBrigith Yamile Castiblanco LopezAún no hay calificaciones
- MisionTIC Ciclo4 ReactJS Ecommerce V5Documento77 páginasMisionTIC Ciclo4 ReactJS Ecommerce V5Camilo CastilloAún no hay calificaciones
- Manual para Acceder A La Base de Datos Del EcmwfDocumento7 páginasManual para Acceder A La Base de Datos Del EcmwfLaura PacciniAún no hay calificaciones
- Libro Shellcodes - HackingDocumento107 páginasLibro Shellcodes - Hackingjose_1059Aún no hay calificaciones
- LogMonitor - Programando Un Sistema de Alertas para Logs Con Node - Js - Back End - Front & BackDocumento4 páginasLogMonitor - Programando Un Sistema de Alertas para Logs Con Node - Js - Back End - Front & BackVero MigAún no hay calificaciones
- T3bis Azure DACDocumento102 páginasT3bis Azure DACSpinbusterAún no hay calificaciones
- Actividad 2Documento8 páginasActividad 2afahcompanyAún no hay calificaciones
- csr1000v Hav2 Configuration Guide On MicDocumento8 páginascsr1000v Hav2 Configuration Guide On MicYuleski PaezAún no hay calificaciones
- M.calculo - Fosa ESCUELA MacalDocumento5 páginasM.calculo - Fosa ESCUELA MacalCristian Barría AlmonacidAún no hay calificaciones
- Resumen Reglas Ratas en Las ParedesDocumento3 páginasResumen Reglas Ratas en Las Paredesjuan luis GarciaAún no hay calificaciones
- Mas Allá de Lo Que Tú Sabes - Intro y Cap 1Documento17 páginasMas Allá de Lo Que Tú Sabes - Intro y Cap 1gabiyiAún no hay calificaciones
- Proyecto FinalDocumento27 páginasProyecto FinalJuan Carlos Apaza RiveraAún no hay calificaciones
- Instalaciones de Baja Tensión para Bar CafeteríaDocumento146 páginasInstalaciones de Baja Tensión para Bar CafeteríaEDUARDO ABRAHAM AVILA SANCHEZAún no hay calificaciones
- Camino Real Eje ComunicacionDocumento32 páginasCamino Real Eje ComunicacionMari MoViAún no hay calificaciones
- CancionesDocumento5 páginasCancionesEDGAR RAMOSAún no hay calificaciones
- Manual de Montador de Sistemas de Andamios de FachadaDocumento56 páginasManual de Montador de Sistemas de Andamios de FachadaJorge Chavez100% (1)
- Linea de TiempoDocumento26 páginasLinea de TiempoLuis CovarrubiasAún no hay calificaciones
- Ejercicios. Fisica II. Hidroestatica e HidrodinamicaDocumento7 páginasEjercicios. Fisica II. Hidroestatica e HidrodinamicaChris GuzmanAún no hay calificaciones
- Secuencia Didáctica Tecnología 1er AñoDocumento5 páginasSecuencia Didáctica Tecnología 1er AñoLiliana VivasAún no hay calificaciones
- Libro Logoterapia.2 PDFDocumento113 páginasLibro Logoterapia.2 PDFDiana Patricia Avila Grijalba100% (1)
- Transmision de Video 20-01-23 GEORGE FULCADODocumento4 páginasTransmision de Video 20-01-23 GEORGE FULCADOAnna Futa Amante de TodasAún no hay calificaciones
- Sesión1 Wendy Nájera PDFDocumento5 páginasSesión1 Wendy Nájera PDFSelene GonzalezAún no hay calificaciones
- Tarea 3. Proceso de Expansión IsobáricaDocumento32 páginasTarea 3. Proceso de Expansión IsobáricaAlfredo LopezAún no hay calificaciones
- Quimica General Laboratorio#4Documento13 páginasQuimica General Laboratorio#4RodriguezLuis2604Aún no hay calificaciones
- Congruencia y SemejanzaDocumento3 páginasCongruencia y Semejanzamarlene1234Aún no hay calificaciones
- Semáforo de 4 Intersecciones - HBDocumento11 páginasSemáforo de 4 Intersecciones - HBHubert Berrio FuentesAún no hay calificaciones
- 10 Formas de Incorporar El Conocimiento Tradicional Indigena Iii Uni. Ciencia y TecnologiaDocumento2 páginas10 Formas de Incorporar El Conocimiento Tradicional Indigena Iii Uni. Ciencia y TecnologiaALDRYN MANUEL RAMOS AJINAún no hay calificaciones
- Ensayo II Quinto BásicoDocumento15 páginasEnsayo II Quinto BásicomakarenaAún no hay calificaciones
- Tablas HunterDocumento6 páginasTablas HunterffingenieriaAún no hay calificaciones
- Cálculo de Huella de Carbono Actividad 2Documento4 páginasCálculo de Huella de Carbono Actividad 2Cesar Enrique Ramírez DuranAún no hay calificaciones
- Informe de Laboratorio Nº. 4 Física ElectrónicaDocumento15 páginasInforme de Laboratorio Nº. 4 Física ElectrónicaANGELITO240100% (1)
- ExtintoresDocumento146 páginasExtintoresMarcello Ross100% (1)
- Informe Previo #3Documento10 páginasInforme Previo #3Elian Esteban Chuquillanqui HuamanAún no hay calificaciones
- A La Caza Del Príncipe Dracula - Kerri ManiscalcoDocumento415 páginasA La Caza Del Príncipe Dracula - Kerri ManiscalcoSRAM2070100% (1)
- FertilizantesDocumento8 páginasFertilizantesEliana Martínez SilveroAún no hay calificaciones
- Ejercicios para Practicar para El ParcialDocumento2 páginasEjercicios para Practicar para El ParcialGabriela Alejandra LunaAún no hay calificaciones
- Resumen WalterLippmannDocumento8 páginasResumen WalterLippmannMartina DigheroAún no hay calificaciones
- ESTAMPADODocumento1 páginaESTAMPADOMedaly GodoyAún no hay calificaciones
- 44 Apps Inteligentes para Ejercitar su Cerebro: Apps Gratuitas, Juegos, y Herramientas para iPhone, iPad, Google Play, Kindle Fire, Navegadores de Internet, Windows Phone, & Apple WatchDe Everand44 Apps Inteligentes para Ejercitar su Cerebro: Apps Gratuitas, Juegos, y Herramientas para iPhone, iPad, Google Play, Kindle Fire, Navegadores de Internet, Windows Phone, & Apple WatchCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Inteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroDe EverandInteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroCalificación: 4 de 5 estrellas4/5 (1)
- UF0513 - Gestión auxiliar de archivo en soporte convencional o informáticoDe EverandUF0513 - Gestión auxiliar de archivo en soporte convencional o informáticoCalificación: 1 de 5 estrellas1/5 (1)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- La biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetDe EverandLa biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetCalificación: 5 de 5 estrellas5/5 (7)
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressDe EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressCalificación: 5 de 5 estrellas5/5 (1)
- Toma de decisiones en las empresas: Entre el arte y la técnica: Metodologías, modelos y herramientasDe EverandToma de decisiones en las empresas: Entre el arte y la técnica: Metodologías, modelos y herramientasAún no hay calificaciones
- GuíaBurros Microsoft Excel: Todo lo que necesitas saber sobre esta potente hoja de cálculoDe EverandGuíaBurros Microsoft Excel: Todo lo que necesitas saber sobre esta potente hoja de cálculoCalificación: 3.5 de 5 estrellas3.5/5 (6)
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Python Deep Learning: Introducción práctica con Keras y TensorFlow 2De EverandPython Deep Learning: Introducción práctica con Keras y TensorFlow 2Calificación: 3.5 de 5 estrellas3.5/5 (5)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- Cultura y clima: fundamentos para el cambio en la organizaciónDe EverandCultura y clima: fundamentos para el cambio en la organizaciónAún no hay calificaciones
- Kanban: La guía definitiva de la metodología Kanban para el desarrollo de software ágil (Libro en Español/Kanban Spanish Book)De EverandKanban: La guía definitiva de la metodología Kanban para el desarrollo de software ágil (Libro en Español/Kanban Spanish Book)Calificación: 4.5 de 5 estrellas4.5/5 (6)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Sistema de gestión lean para principiantes: Fundamentos del sistema de gestión lean para pequeñas y medianas empresas - con muchos ejemplos prácticosDe EverandSistema de gestión lean para principiantes: Fundamentos del sistema de gestión lean para pequeñas y medianas empresas - con muchos ejemplos prácticosCalificación: 4 de 5 estrellas4/5 (16)
- Aprender Docker, un enfoque prácticoDe EverandAprender Docker, un enfoque prácticoCalificación: 5 de 5 estrellas5/5 (3)
- Agile: Una guía para la Gestión de Proyectos Agile con Scrum, Kanban y LeanDe EverandAgile: Una guía para la Gestión de Proyectos Agile con Scrum, Kanban y LeanCalificación: 5 de 5 estrellas5/5 (1)
- Criptografía sin secretos con Python: Spyware/Programa espíaDe EverandCriptografía sin secretos con Python: Spyware/Programa espíaCalificación: 5 de 5 estrellas5/5 (4)
- Guía De Hacking De Computadora Para Principiantes: Cómo Hackear Una Red Inalámbrica Seguridad Básica Y Pruebas De Penetración Kali Linux Su Primer HackDe EverandGuía De Hacking De Computadora Para Principiantes: Cómo Hackear Una Red Inalámbrica Seguridad Básica Y Pruebas De Penetración Kali Linux Su Primer HackAún no hay calificaciones
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (117)
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- Fundamentos de bases de datos: Notas de referenciaDe EverandFundamentos de bases de datos: Notas de referenciaAún no hay calificaciones