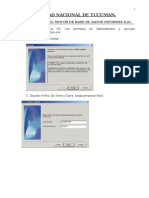
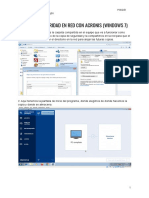
También podría gustarte
- Testeo y verificación de equipos y periféricos microinformáticos. IFCT0108De EverandTesteo y verificación de equipos y periféricos microinformáticos. IFCT0108Aún no hay calificaciones
- Laboratorio SIEMDocumento10 páginasLaboratorio SIEMWilmer EspinosaAún no hay calificaciones
- Actividad de Aprendizaje 4 Implantación de Sistemas de Software LibreDocumento26 páginasActividad de Aprendizaje 4 Implantación de Sistemas de Software Libreelmer villagranAún no hay calificaciones
- Dimensionar, instalar y optimizar el hardware. IFCT0510De EverandDimensionar, instalar y optimizar el hardware. IFCT0510Aún no hay calificaciones
- UF0864 - Resolución de averías lógicas en equipos microinformáticosDe EverandUF0864 - Resolución de averías lógicas en equipos microinformáticosAún no hay calificaciones
- UF0853 - Explotación de las funcionalidades del sistema microinformáticoDe EverandUF0853 - Explotación de las funcionalidades del sistema microinformáticoAún no hay calificaciones
- Elk Elastic Kibana PDFDocumento16 páginasElk Elastic Kibana PDFJohn CardAún no hay calificaciones
- Felk Elastic Kibana PDFDocumento16 páginasFelk Elastic Kibana PDFJohn CardAún no hay calificaciones
- Instalación y Configuración de Un Ambiente de Desarrollo LAMPDocumento17 páginasInstalación y Configuración de Un Ambiente de Desarrollo LAMPJeenn JeenAún no hay calificaciones
- Instalacion SONARDocumento12 páginasInstalacion SONARindex007Aún no hay calificaciones
- Logs Analisis Logs Patricio VacaDocumento9 páginasLogs Analisis Logs Patricio VacaPatricio Vaca EscobarAún no hay calificaciones
- Laboratorio - MetaexploitDocumento7 páginasLaboratorio - MetaexploitGustavo RivasAún no hay calificaciones
- Herramienta de Monitoreo de Red ICINGADocumento18 páginasHerramienta de Monitoreo de Red ICINGAMary SanchezAún no hay calificaciones
- LinuxDocumento14 páginasLinuxCesar GonzalezAún no hay calificaciones
- Manual Técnico Del Sistema Reloj ChecadorDocumento7 páginasManual Técnico Del Sistema Reloj ChecadorCuauhtemoc Hernandez FloresAún no hay calificaciones
- Manual de Instalacion y Configuracion de Apache, JBoss y Mod - ClusterDocumento13 páginasManual de Instalacion y Configuracion de Apache, JBoss y Mod - Clusterbrandon ramirezAún no hay calificaciones
- 30002-S02-Material ComplementarioDocumento5 páginas30002-S02-Material ComplementarioRenzo MedranoAún no hay calificaciones
- 5 2-FilebeatDocumento2 páginas5 2-FilebeatMiguel ChaparroAún no hay calificaciones
- Manual Ténico - CXR Covid DetectorDocumento9 páginasManual Ténico - CXR Covid DetectorFelipe Buitrago CarmonaAún no hay calificaciones
- Servidor de Aplicaciones-Glassfish PDFDocumento24 páginasServidor de Aplicaciones-Glassfish PDFonominooooAún no hay calificaciones
- Instalación de Limesurvey en UbuntuDocumento15 páginasInstalación de Limesurvey en UbuntuAlonso AriasAún no hay calificaciones
- Tutorial Spring SecurityDocumento6 páginasTutorial Spring SecurityMariela Pérez HernàndezAún no hay calificaciones
- InstruccionesDocumento2 páginasInstruccionesJuan Carlos Mamani HuaytaAún no hay calificaciones
- Actividad 4 Implantacion de Sistemas de Software LibreDocumento27 páginasActividad 4 Implantacion de Sistemas de Software LibreLuis Gerardo SanchezAún no hay calificaciones
- Rsyslog-Loganalyzer (Manual)Documento14 páginasRsyslog-Loganalyzer (Manual)Jandir Ayrton VENTOCILLA MARTINEZAún no hay calificaciones
- Manual de Process CarsoftDocumento47 páginasManual de Process CarsoftalejoalzatesenaAún no hay calificaciones
- Instalación Tryton 3.4 Ubuntu 14.04Documento6 páginasInstalación Tryton 3.4 Ubuntu 14.04Benshy ManriqueAún no hay calificaciones
- Manual SAWMILL-LINUX SOBRE PROXMOXDocumento8 páginasManual SAWMILL-LINUX SOBRE PROXMOXGilmarAún no hay calificaciones
- TPF Virtualizacion-Issolio TomasDocumento31 páginasTPF Virtualizacion-Issolio TomasJavier RozaAún no hay calificaciones
- Instalacion Informix 9.21 UntDocumento19 páginasInstalacion Informix 9.21 UntSebastianAndradeAún no hay calificaciones
- Guía Subir Aplicacion Web A Un ServidorDocumento2 páginasGuía Subir Aplicacion Web A Un ServidorjuanAún no hay calificaciones
- Guia de Instalacion EncuestasDocumento10 páginasGuia de Instalacion EncuestasbuhomayhemAún no hay calificaciones
- Guía de Instalación y Configuración de Cacti en CentOS7Documento16 páginasGuía de Instalación y Configuración de Cacti en CentOS7Jose Luis RiveraAún no hay calificaciones
- Manual de Instalación y Configuración Del Sistema de InformaciónDocumento7 páginasManual de Instalación y Configuración Del Sistema de InformaciónNathaly SAún no hay calificaciones
- Manual de Instalación y Configuración de Liferay SODocumento40 páginasManual de Instalación y Configuración de Liferay SOJuan Carlos Quispe ZapataAún no hay calificaciones
- Sar ConsolidadoDocumento7 páginasSar ConsolidadoWilmer RonAún no hay calificaciones
- Manual MySQLDocumento11 páginasManual MySQLAndres bedonAún no hay calificaciones
- Manual de Instalacion y Configuracion Dspace-CybertesisDocumento31 páginasManual de Instalacion y Configuracion Dspace-CybertesisShinkò BoanerguesAún no hay calificaciones
- Instalar Cacti en Un Servidor CentOS 7Documento10 páginasInstalar Cacti en Un Servidor CentOS 7Arnulfo RiveraAún no hay calificaciones
- Smoothwall ProfesionalDocumento10 páginasSmoothwall ProfesionalagnusdarkAún no hay calificaciones
- Sar ConsolidadoDocumento7 páginasSar ConsolidadoWilmer RonAún no hay calificaciones
- ManualDocumento19 páginasManualMarvinAún no hay calificaciones
- OCS InventoryDocumento31 páginasOCS InventoryRafael del Castillo Gomariz75% (4)
- Manual de Instalacion de Owncloud TerminadoDocumento29 páginasManual de Instalacion de Owncloud TerminadoZe SergioAún no hay calificaciones
- Manualfinalnagios 110624170020 Phpapp02Documento63 páginasManualfinalnagios 110624170020 Phpapp02marnaglayamarnaAún no hay calificaciones
- Comandos Meterpreter (Utiles)Documento4 páginasComandos Meterpreter (Utiles)Juan Carlos Angeles VazquezAún no hay calificaciones
- Instalacion y Configuracion - PentahoDocumento12 páginasInstalacion y Configuracion - PentahoMarvin AnchetaAún no hay calificaciones
- Erick - Vazquez - ACTIVIDAD 4 - Sistemas Abiertos de SoftwareDocumento31 páginasErick - Vazquez - ACTIVIDAD 4 - Sistemas Abiertos de SoftwareErick VázquezAún no hay calificaciones
- Guía de Estudio BackendDocumento74 páginasGuía de Estudio BackendHernan Dario Diaz PeraltaAún no hay calificaciones
- Instalar Server Tacacs + Centos 6 + GNS3 + CiscoDocumento4 páginasInstalar Server Tacacs + Centos 6 + GNS3 + Ciscosivi laAún no hay calificaciones
- Servidor de Aplicaciones-Glassfish (Preinforme 2) PDFDocumento18 páginasServidor de Aplicaciones-Glassfish (Preinforme 2) PDFonominooooAún no hay calificaciones
- Manual Instalacion Quipux 2Documento11 páginasManual Instalacion Quipux 2Jm NéjerAún no hay calificaciones
- Informe Ieee Autodiagnostico y EnrutamientoDocumento5 páginasInforme Ieee Autodiagnostico y EnrutamientoNatalyAún no hay calificaciones
- Guía de Instalación Rápida Opengts-WindowsDocumento5 páginasGuía de Instalación Rápida Opengts-Windowsge-ed100% (2)
- Actividad Software DistribuidoDocumento10 páginasActividad Software DistribuidoCristian Andrés Torres CardozoAún no hay calificaciones
- Tarea 6Documento8 páginasTarea 6Alberto GonzalezAún no hay calificaciones
- Desarrollo y optimización de componentes software para tareas administrativas de sistemas. IFCT0609De EverandDesarrollo y optimización de componentes software para tareas administrativas de sistemas. IFCT0609Aún no hay calificaciones
- Resolución de averías lógicas en equipos microinformáticos. IFCT0309De EverandResolución de averías lógicas en equipos microinformáticos. IFCT0309Aún no hay calificaciones
- Desarrollo de componentes software para el manejo de dispositivos. IFCT0609De EverandDesarrollo de componentes software para el manejo de dispositivos. IFCT0609Aún no hay calificaciones
- Informe Seguridad Argumentos NRPEDocumento6 páginasInforme Seguridad Argumentos NRPEnoseAún no hay calificaciones
- Test Examen 5 Itil v4Documento8 páginasTest Examen 5 Itil v4noseAún no hay calificaciones
- Cuaderno Del Participante - DISCDocumento14 páginasCuaderno Del Participante - DISCnoseAún no hay calificaciones
- Test Examen 1 Itil v4Documento8 páginasTest Examen 1 Itil v4noseAún no hay calificaciones
- Ticket TMB3M2 3Documento2 páginasTicket TMB3M2 3noseAún no hay calificaciones
- Borrador TFG OKDocumento20 páginasBorrador TFG OKnoseAún no hay calificaciones
- Scrum Foundations Professional - Jose Manuel Garrido PerejonDocumento1 páginaScrum Foundations Professional - Jose Manuel Garrido PerejonnoseAún no hay calificaciones
- Instalación y Configuración de Nagios Core 4.0.4 PDFDocumento58 páginasInstalación y Configuración de Nagios Core 4.0.4 PDFHectorPelaezAún no hay calificaciones
- Normativa Proyecto Fin de CicloDocumento6 páginasNormativa Proyecto Fin de CiclonoseAún no hay calificaciones
- Resumen y ObjetivosDocumento2 páginasResumen y ObjetivosnoseAún no hay calificaciones
- Antecedentes PFC - Jose Manuel GarridoDocumento7 páginasAntecedentes PFC - Jose Manuel GarridonoseAún no hay calificaciones
- PROCEDIMIENTO PARA PONER EN DOWNTIME VARIOS HOST A LA VEZ (En Proceso)Documento2 páginasPROCEDIMIENTO PARA PONER EN DOWNTIME VARIOS HOST A LA VEZ (En Proceso)noseAún no hay calificaciones
- TFGDocumento2 páginasTFGnoseAún no hay calificaciones
- Monitorizacion Desporletizacion V2Documento3 páginasMonitorizacion Desporletizacion V2noseAún no hay calificaciones
- Propuesta PFC - Jose Manuel Garrido PerejonDocumento1 páginaPropuesta PFC - Jose Manuel Garrido PerejonnoseAún no hay calificaciones
- CosasDocumento1 páginaCosasnoseAún no hay calificaciones
- P17 - Pandora-FMS - Escaneo de RedDocumento7 páginasP17 - Pandora-FMS - Escaneo de RednoseAún no hay calificaciones
- P16 Pandora-FMS Instalación DebianDocumento5 páginasP16 Pandora-FMS Instalación DebiannoseAún no hay calificaciones
- P01 WS-DHCPDocumento3 páginasP01 WS-DHCPnoseAún no hay calificaciones
- P20 - OpenNMS-vs-Angry IP Scanner - LDocumento5 páginasP20 - OpenNMS-vs-Angry IP Scanner - LnoseAún no hay calificaciones
- Configuracion de Pulse de Informatica Ayuntamiento de MadridDocumento1 páginaConfiguracion de Pulse de Informatica Ayuntamiento de MadridnoseAún no hay calificaciones
- P19 - Advanced IP Scanner-vs-SpiceWorks - WDocumento5 páginasP19 - Advanced IP Scanner-vs-SpiceWorks - WnoseAún no hay calificaciones
- P14 - Nagios - Centos7-Monitoriza-LinuxDocumento2 páginasP14 - Nagios - Centos7-Monitoriza-LinuxnoseAún no hay calificaciones
- MarcasDocumento8 páginasMarcasnoseAún no hay calificaciones
- Comandos Ut13Documento5 páginasComandos Ut13noseAún no hay calificaciones
- SwitchingDocumento15 páginasSwitchingnoseAún no hay calificaciones
- P03 - SSH WireSharkDocumento2 páginasP03 - SSH WireSharknoseAún no hay calificaciones
- P04 Retardo Pérdidas WireSharkDocumento2 páginasP04 Retardo Pérdidas WireSharknoseAún no hay calificaciones
- COPIA DE SEGURIDAD EN RED CON ACRONIS - Jose Manuel Garrido y Manuel Ruiz TorresDocumento8 páginasCOPIA DE SEGURIDAD EN RED CON ACRONIS - Jose Manuel Garrido y Manuel Ruiz TorresnoseAún no hay calificaciones
- Software Como Servicio (SaaS), Plataforma Como Servicio (PaaS) e Infraestructura Como Servicio (IaaS)Documento36 páginasSoftware Como Servicio (SaaS), Plataforma Como Servicio (PaaS) e Infraestructura Como Servicio (IaaS)Omar VlogsAún no hay calificaciones
- Texto Ingenieria SocialDocumento38 páginasTexto Ingenieria Socialapi-3835755Aún no hay calificaciones
- Leyes, Acuerdos, Creacion Usuario SicoinDocumento4 páginasLeyes, Acuerdos, Creacion Usuario SicoinErick SaulAún no hay calificaciones
- Instructivo Software AbbyDocumento6 páginasInstructivo Software AbbyBruno Barra PezoAún no hay calificaciones
- Secuencia de Ensamble Del Servidor y de Instalación de UBUNTU - GHLDocumento7 páginasSecuencia de Ensamble Del Servidor y de Instalación de UBUNTU - GHLGerardo Hernández LópezAún no hay calificaciones
- 2018-II - Vii - Administración de RedesDocumento5 páginas2018-II - Vii - Administración de RedesReyler Chavez GaonaAún no hay calificaciones
- Digital Journey From Monolith To Microservices Español-Final PDFDocumento99 páginasDigital Journey From Monolith To Microservices Español-Final PDFwwilka90Aún no hay calificaciones
- Implantación FOG v1.2.0Documento26 páginasImplantación FOG v1.2.0Jeffrey CerpaAún no hay calificaciones
- ManualPyAfipWs - SistemasAgiles PDFDocumento82 páginasManualPyAfipWs - SistemasAgiles PDF.docAún no hay calificaciones
- AES - Caso TalibankDocumento8 páginasAES - Caso TalibankVictor Manuel RamosAún no hay calificaciones
- Normativa HURPDocumento9 páginasNormativa HURPJoan BatleAún no hay calificaciones
- Politicas y Procedimientos de Seguridad PUBLICADODocumento44 páginasPoliticas y Procedimientos de Seguridad PUBLICADOFreed Sajami VasquezAún no hay calificaciones
- 7.3.2.5 Lab - Reading Server LogsDocumento8 páginas7.3.2.5 Lab - Reading Server LogscesarAún no hay calificaciones
- 01 Cap04apuntes InstanciaDeLaBaseDeDatosV3Documento22 páginas01 Cap04apuntes InstanciaDeLaBaseDeDatosV3Adolfo SaltoAún no hay calificaciones
- TensorFlow Machine Learning Coo - McClure, NickDocumento100 páginasTensorFlow Machine Learning Coo - McClure, NickJohnjhas90Aún no hay calificaciones
- Scop OsinergminDocumento6 páginasScop Osinergminalumnopitagoras0% (1)
- GD Informatica Programacion ConcurrenteDocumento16 páginasGD Informatica Programacion Concurrentealbertof00Aún no hay calificaciones
- Tarea Virtual # 6 REDES 2Documento5 páginasTarea Virtual # 6 REDES 2David Triguero GarciaAún no hay calificaciones
- Manual Thinware en EspañolDocumento29 páginasManual Thinware en EspañolBenjamín Garzón OteroAún no hay calificaciones
- Tema 6 El Alcance Del Proyecto Flow Chart PDFDocumento12 páginasTema 6 El Alcance Del Proyecto Flow Chart PDFMiguel LópezAún no hay calificaciones
- PDF Monografia Data Center CompressDocumento72 páginasPDF Monografia Data Center Compressarnold kevinAún no hay calificaciones
- Vacantes 2023 ICBFDocumento15 páginasVacantes 2023 ICBFMariana CárdenasAún no hay calificaciones
- Base de Datos DgraphDocumento5 páginasBase de Datos DgraphIsabella OlivarAún no hay calificaciones
- Configuracion Software Control de Acceso SOYALDocumento0 páginasConfiguracion Software Control de Acceso SOYALRaulinoRAún no hay calificaciones
- Herramientas de Bases de Datos DistribuidasDocumento19 páginasHerramientas de Bases de Datos Distribuidasald0_cp0% (1)
- Perfil y CV EmpleadosDocumento79 páginasPerfil y CV EmpleadosKennia VelazquezAún no hay calificaciones
- 09 Taller 1Documento47 páginas09 Taller 1QueTeDenPolCulooAún no hay calificaciones
- Sistemas de Storage para Data CenterDocumento4 páginasSistemas de Storage para Data CenterAlvaro BaldiviezoAún no hay calificaciones
- Investigacion Tipos de Servidores y Archivos de RedDocumento8 páginasInvestigacion Tipos de Servidores y Archivos de RedStalin Karakras MenaAún no hay calificaciones
- Guía de Instalación de HelpnexDocumento17 páginasGuía de Instalación de HelpnexMiguel Andino AlonsoAún no hay calificaciones