También podría gustarte
- Desarrollo seguro en ingeniería del software.: Aplicaciones seguras con Android, NodeJS, Python y C++De EverandDesarrollo seguro en ingeniería del software.: Aplicaciones seguras con Android, NodeJS, Python y C++Aún no hay calificaciones
- Set de Instrucciones de ARMDocumento54 páginasSet de Instrucciones de ARMRafael PerezAún no hay calificaciones
- KNX. Domótica e Inmótica: Guía Práctica para el instaladorDe EverandKNX. Domótica e Inmótica: Guía Práctica para el instaladorCalificación: 5 de 5 estrellas5/5 (1)
- Tipos de ProcesosDocumento119 páginasTipos de ProcesosCarlos MartinezAún no hay calificaciones
- TIGRAN AIVAZIAN - Dentro Del Nucleo Linux 2 4Documento79 páginasTIGRAN AIVAZIAN - Dentro Del Nucleo Linux 2 4María GabrielaAún no hay calificaciones
- Sistope Resumen PEP2Documento17 páginasSistope Resumen PEP2Daniel EguiluzAún no hay calificaciones
- TEMA 2 Procesadores SuperescalaresDocumento11 páginasTEMA 2 Procesadores SuperescalaresJesus Daniel Anaya AlvaradoAún no hay calificaciones
- Guía metodológica de iniciación al programa SAP2000®De EverandGuía metodológica de iniciación al programa SAP2000®Calificación: 5 de 5 estrellas5/5 (3)
- Ruiz Muzquiz - Sistemas OperativosDocumento119 páginasRuiz Muzquiz - Sistemas OperativosMargarita MaguytoAún no hay calificaciones
- Pentesting en Entornos ControladosDocumento56 páginasPentesting en Entornos ControladosSony EscriAún no hay calificaciones
- Computadores para bases de datos. IFCT0310De EverandComputadores para bases de datos. IFCT0310Aún no hay calificaciones
- MICROPROCESADORESDocumento4 páginasMICROPROCESADORESCriz dguezAún no hay calificaciones
- UF0852 - Instalación y actualización de sistemas operativosDe EverandUF0852 - Instalación y actualización de sistemas operativosCalificación: 5 de 5 estrellas5/5 (1)
- Nefestorer AsmDocumento87 páginasNefestorer Asmlos losAún no hay calificaciones
- Instalación, Configuración y Clonación de Equipos con Sistemas OperativosDe EverandInstalación, Configuración y Clonación de Equipos con Sistemas OperativosCalificación: 5 de 5 estrellas5/5 (1)
- 03 - Seguridad en Sistemas OperativosDocumento43 páginas03 - Seguridad en Sistemas OperativosCristhian ThoroAún no hay calificaciones
- Principios básicos de estática y programación aplicados a casos realesDe EverandPrincipios básicos de estática y programación aplicados a casos realesCalificación: 5 de 5 estrellas5/5 (1)
- Procesadores Superescalares: Ciencias Exactas y Naturales y AgrimensuraDocumento9 páginasProcesadores Superescalares: Ciencias Exactas y Naturales y AgrimensuraAdrian BetancourtAún no hay calificaciones
- Hacking & cracking. Redes inalámbricas wifiDe EverandHacking & cracking. Redes inalámbricas wifiCalificación: 4.5 de 5 estrellas4.5/5 (2)
- Practicas Ensamblador Raspberry PiDocumento196 páginasPracticas Ensamblador Raspberry PiJose Carlos Juanos Maculet100% (1)
- 04 Administracion de MemoriaDocumento47 páginas04 Administracion de MemoriaAnonymous sRCxX8Aún no hay calificaciones
- Programación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubeDe EverandProgramación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubeAún no hay calificaciones
- Programacion de Software - OSDocumento139 páginasProgramacion de Software - OSRaúl OpazoAún no hay calificaciones
- Oracle 12c Forms y Reports: Curso práctico de formaciónDe EverandOracle 12c Forms y Reports: Curso práctico de formaciónAún no hay calificaciones
- Implementacion de Operaciones Aritméticas y Lógicas en Una CPU Con Una Unidad de Control MicroprogramadaDocumento31 páginasImplementacion de Operaciones Aritméticas y Lógicas en Una CPU Con Una Unidad de Control MicroprogramadaEliaquin Clavijo ManuttupaAún no hay calificaciones
- Capitulo3 PROCESADORES-SUPERESCALARESDocumento143 páginasCapitulo3 PROCESADORES-SUPERESCALARESPatty Pat100% (2)
- MAN30 Fundamentos Computadores PDFDocumento300 páginasMAN30 Fundamentos Computadores PDFDanielaAún no hay calificaciones
- Libros SooDocumento377 páginasLibros SooSony EscriAún no hay calificaciones
- Preguntas ArquitecturaDocumento3 páginasPreguntas ArquitecturaCésar Malaquías Aguirre PascualAún no hay calificaciones
- TFG FinalDocumento180 páginasTFG FinalOSCAR CONTRERASAún no hay calificaciones
- Balotario Capitulo 3-4Documento13 páginasBalotario Capitulo 3-4Noel HCAún no hay calificaciones
- Módulo 1 - Visión Global Hardware y Software v1Documento43 páginasMódulo 1 - Visión Global Hardware y Software v1Álex Pérez GiménezAún no hay calificaciones
- Diseno e Implementacion de Un SoC en Un FPGA Basado en El ISA de RISC VDocumento294 páginasDiseno e Implementacion de Un SoC en Un FPGA Basado en El ISA de RISC VChristian Hurtado S.Aún no hay calificaciones
- Resumen Arquitectura de ComputadorasDocumento10 páginasResumen Arquitectura de ComputadorasCHRISTIAN GUERREROAún no hay calificaciones
- JajajDocumento2 páginasJajajAdrian OrielAún no hay calificaciones
- ConceptDocumento156 páginasConceptAndres RaymondAún no hay calificaciones
- PL PGSQLDocumento36 páginasPL PGSQLmaxcongoAún no hay calificaciones
- Introducción A La Programación en CDocumento623 páginasIntroducción A La Programación en CSantiago Dorado100% (3)
- Aps cc41bDocumento62 páginasAps cc41bJosue TtitoAún no hay calificaciones
- Estructura de Computadores - Módulo 7 - La Arquitectura CISCADocumento54 páginasEstructura de Computadores - Módulo 7 - La Arquitectura CISCAtin leeAún no hay calificaciones
- Desarrollo de Proyectos Informáticos Con Tecnología Java PDFDocumento268 páginasDesarrollo de Proyectos Informáticos Con Tecnología Java PDFEmerson VeronezAún no hay calificaciones
- Sistema de Memoria: M. Isabel Garc Ia ClementeDocumento73 páginasSistema de Memoria: M. Isabel Garc Ia ClementeFermin RemiroAún no hay calificaciones
- Memoria DinamicaDocumento225 páginasMemoria DinamicaJesus Lopez100% (1)
- Curso-programacion-s7-300-Avanzado EDCAI 2006 Grupo Profesores TecnicosDocumento84 páginasCurso-programacion-s7-300-Avanzado EDCAI 2006 Grupo Profesores Tecnicosinfraestructuras comunesAún no hay calificaciones
- Instrucciones Avanzadas v2 2Documento84 páginasInstrucciones Avanzadas v2 2dega88Aún no hay calificaciones
- Balotario 3 ArquiDocumento7 páginasBalotario 3 ArquiJHORDAM MAXWELL GOMEZ TORRESAún no hay calificaciones
- Capítulo 4 - Gestion de Memoria VirtualDocumento21 páginasCapítulo 4 - Gestion de Memoria VirtualPablo Cesar Medina BarretoAún no hay calificaciones
- Apuntes MATLABMOMDocumento145 páginasApuntes MATLABMOMEnrique Tejada FarfanAún no hay calificaciones
- 11265000-Sew Eurodrive-Buses de CampoDocumento144 páginas11265000-Sew Eurodrive-Buses de CampoLuis Enrique Zamora RomanAún no hay calificaciones
- Modulo 2Documento45 páginasModulo 2gimenez adrianaAún no hay calificaciones
- Capitulo 4 - BalotarioDocumento2 páginasCapitulo 4 - BalotarioEDGAR ANDRE GAMBOA BELTRANAún no hay calificaciones
- SoMachine Basic - Guía de La Biblioteca de Funciones GenericasDocumento262 páginasSoMachine Basic - Guía de La Biblioteca de Funciones GenericasRicky Mclaughlin67% (3)
- TFG Pablo Sayaus CobosDocumento101 páginasTFG Pablo Sayaus CobosVinceMejíasAún no hay calificaciones
- Arquitectura de ComputadorasDocumento269 páginasArquitectura de ComputadorasEder Abraham MendozaAún no hay calificaciones
- Fundamentos SQL OracleDocumento102 páginasFundamentos SQL OracleCarlos Alberto Cabrera EscamillaAún no hay calificaciones
- MySQL PresentacionDocumento30 páginasMySQL PresentacionyopeibAún no hay calificaciones
- Presentacion de Diseño Asistido Por Computadora (Unidad 2)Documento4 páginasPresentacion de Diseño Asistido Por Computadora (Unidad 2)J Rodrigo Castro HAún no hay calificaciones
- IISI - Evaluación Final - D - Ebert ZunigaDocumento4 páginasIISI - Evaluación Final - D - Ebert ZunigaEbert ZunigaAún no hay calificaciones
- Computadores Vectoriales y MatricialesDocumento12 páginasComputadores Vectoriales y MatricialesJoskani MendozaAún no hay calificaciones
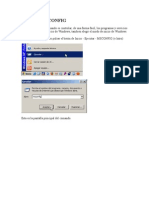
- Comando MSCONFIGDocumento7 páginasComando MSCONFIGTomHDAún no hay calificaciones
- Previo 2 Andrea SerraldeDocumento4 páginasPrevio 2 Andrea SerraldeAndrea Serralde FloresAún no hay calificaciones
- Caso de Aplicacion DRPDocumento3 páginasCaso de Aplicacion DRPRafael Eduardo Paniagua MorenoAún no hay calificaciones
- Mantenimiento Preventivo y Correctivo cOMPLETODocumento20 páginasMantenimiento Preventivo y Correctivo cOMPLETOHugo LewisAún no hay calificaciones
- Actividad 14 - AHRDocumento4 páginasActividad 14 - AHRAlan JuarezAún no hay calificaciones
- Tipos de Memoria RAMDocumento3 páginasTipos de Memoria RAMJhon EstebanAún no hay calificaciones
- Compuertas LogicasDocumento16 páginasCompuertas LogicasDiego Armando Colque BautistaAún no hay calificaciones
- Elettronica MoviliftDocumento54 páginasElettronica MoviliftFelipe Raul Chumpitaz G100% (2)
- 097 - Mini Proyectos en Python - Arturo Elias AntonDocumento10 páginas097 - Mini Proyectos en Python - Arturo Elias AntonCoronel Martinez LAún no hay calificaciones
- Solucionar El Problema de Arranque en Ubuntu y Linux Mint (Initramfs)Documento13 páginasSolucionar El Problema de Arranque en Ubuntu y Linux Mint (Initramfs)Martín LehoczkyAún no hay calificaciones
- Introducción A Los Sistemas de CómputoDocumento3 páginasIntroducción A Los Sistemas de CómputoravitonimacachiAún no hay calificaciones
- EXPERIENCIA #1 Consumo ElectricoDocumento3 páginasEXPERIENCIA #1 Consumo ElectricoSCARLETT MIRANDA RAMIREZAún no hay calificaciones
- T OyM MiNIDDocumento178 páginasT OyM MiNIDAdrian Vázquez CastroAún no hay calificaciones
- LACP (Link Aggregation Control Protocol)Documento8 páginasLACP (Link Aggregation Control Protocol)Xavier Pincay0% (1)
- 4 Javascript & Jquery Examen de Recuperación 2022-2Documento3 páginas4 Javascript & Jquery Examen de Recuperación 2022-2SEBASTIAN BRYAN LOAIZA CAMASCCAAún no hay calificaciones
- M Microcontroladores ITSE 2023 1Documento69 páginasM Microcontroladores ITSE 2023 1CARREÑO VARGAS JUAN ALBERTOAún no hay calificaciones
- Optiplex-960 Service Manual En-UsDocumento149 páginasOptiplex-960 Service Manual En-UsFranklin Miranda RoblesAún no hay calificaciones
- Actividad 3 - Programación EstructuradaDocumento12 páginasActividad 3 - Programación EstructuradaLuis MoraAún no hay calificaciones
- Variables Tipo String Con JoptionpaneDocumento2 páginasVariables Tipo String Con JoptionpaneAlonso AriasAún no hay calificaciones
- ZXBInstaller Version 3.3.1 FinalDocumento11 páginasZXBInstaller Version 3.3.1 Finalmantys55543% (7)
- Guia de Sistema OperativoDocumento9 páginasGuia de Sistema Operativojimenapc02100% (5)
- República Bolivariana de VenezuelaDocumento8 páginasRepública Bolivariana de VenezuelaAngel Marcano100% (1)
- Cuestionario Software LibreDocumento25 páginasCuestionario Software Librejosman fredy bueno lealAún no hay calificaciones
- Mantenimiento Equipos AudiovisualesDocumento4 páginasMantenimiento Equipos AudiovisualesPAULAAún no hay calificaciones
- Evaluacion TransmisonDocumento5 páginasEvaluacion TransmisonRodrigo LopezAún no hay calificaciones
- EB09 Eq3 Practica2Documento12 páginasEB09 Eq3 Practica2Emiliano Isai Granados ValenciaAún no hay calificaciones
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (117)
- Guía de cálculo y diseño de conductos para ventilación y climatizaciónDe EverandGuía de cálculo y diseño de conductos para ventilación y climatizaciónCalificación: 5 de 5 estrellas5/5 (1)
- LAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.De EverandLAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.Calificación: 4.5 de 5 estrellas4.5/5 (54)
- Lógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosDe EverandLógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosCalificación: 3.5 de 5 estrellas3.5/5 (7)
- Excel 2021 y 365 Paso a Paso: Paso a PasoDe EverandExcel 2021 y 365 Paso a Paso: Paso a PasoCalificación: 5 de 5 estrellas5/5 (12)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Inteligencia artificial: Análisis de datos e innovación para principiantesDe EverandInteligencia artificial: Análisis de datos e innovación para principiantesCalificación: 4 de 5 estrellas4/5 (3)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- ¿Cómo piensan las máquinas?: Inteligencia artificial para humanosDe Everand¿Cómo piensan las máquinas?: Inteligencia artificial para humanosCalificación: 5 de 5 estrellas5/5 (1)
- UF2246 - Reparación de pequeños electrodomésticos y herramientas eléctricasDe EverandUF2246 - Reparación de pequeños electrodomésticos y herramientas eléctricasCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Todo Sobre Tecnología Blockchain: La Guía Definitiva Para Principiantes Sobre Monederos BlockchainDe EverandTodo Sobre Tecnología Blockchain: La Guía Definitiva Para Principiantes Sobre Monederos BlockchainAún no hay calificaciones
- Manual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasDe EverandManual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Machine Learning y Deep Learning: Usando Python, Scikit y KerasDe EverandMachine Learning y Deep Learning: Usando Python, Scikit y KerasAún no hay calificaciones
- Comunicaciones industriales y WinCCDe EverandComunicaciones industriales y WinCCCalificación: 5 de 5 estrellas5/5 (4)
- Design Thinking para principiantes: La innovación como factor para el éxito empresarialDe EverandDesign Thinking para principiantes: La innovación como factor para el éxito empresarialCalificación: 4.5 de 5 estrellas4.5/5 (10)
- El mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosDe EverandEl mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosCalificación: 5 de 5 estrellas5/5 (2)
- Ciberseguridad industrial e infraestructuras críticasDe EverandCiberseguridad industrial e infraestructuras críticasAún no hay calificaciones
- La psicología del trading de una forma sencilla: Cómo aplicar las estrategias psicológicas y las actitudes de los comerciantes ganadores para operar con éxito en línea.De EverandLa psicología del trading de una forma sencilla: Cómo aplicar las estrategias psicológicas y las actitudes de los comerciantes ganadores para operar con éxito en línea.Calificación: 4.5 de 5 estrellas4.5/5 (3)
- Metodología básica de instrumentación industrial y electrónicaDe EverandMetodología básica de instrumentación industrial y electrónicaCalificación: 4 de 5 estrellas4/5 (12)
- Curso básico de Python: La guía para principiantes para una introducción en la programación con PythonDe EverandCurso básico de Python: La guía para principiantes para una introducción en la programación con PythonAún no hay calificaciones