También podría gustarte
- Conexión SQL SERVER & C# (Manual para principiantes)De EverandConexión SQL SERVER & C# (Manual para principiantes)Calificación: 1 de 5 estrellas1/5 (1)
- UF1890 - Desarrollo de componente software y consultas dentro del sistema de almacén de datosDe EverandUF1890 - Desarrollo de componente software y consultas dentro del sistema de almacén de datosAún no hay calificaciones
- Tarea 9 - Carga DSA Con ETLsDocumento20 páginasTarea 9 - Carga DSA Con ETLsTinker gameAún no hay calificaciones
- TIC2 Lab3.1 SSISDocumento12 páginasTIC2 Lab3.1 SSISEstefania Angélica Hernández SilvaAún no hay calificaciones
- Aa5 - Evi 3-Migracion de Base de DatosDocumento53 páginasAa5 - Evi 3-Migracion de Base de DatosJohn OrregoAún no hay calificaciones
- ARTÍCULO: Instalación de La Base de Datos Northwind - PrincipiantesDocumento9 páginasARTÍCULO: Instalación de La Base de Datos Northwind - PrincipiantesKrasis Press100% (5)
- BI Sesion4 Practica SSIS AvanzadoDocumento17 páginasBI Sesion4 Practica SSIS AvanzadoGiancarlo GonzalesAún no hay calificaciones
- Manual-Libro Sobre SSIS PDFDocumento8 páginasManual-Libro Sobre SSIS PDFGustavo A. CondeAún no hay calificaciones
- LAB06Documento23 páginasLAB06Jason AlexanderAún no hay calificaciones
- LECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyDocumento85 páginasLECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyAndy Alva AcostaAún no hay calificaciones
- A2.5 Práctica Procedimiento para La Instalación y Configuración de SGBDDocumento35 páginasA2.5 Práctica Procedimiento para La Instalación y Configuración de SGBDJOSE ALFREDO GUZMAN AVALOSAún no hay calificaciones
- 14 - Desarrollo de SoftwareDocumento27 páginas14 - Desarrollo de SoftwareFrancisco FontecillaAún no hay calificaciones
- Integration Services Pieza Fundamental en Los Proyectos de BI (Parte 1 de 2)Documento6 páginasIntegration Services Pieza Fundamental en Los Proyectos de BI (Parte 1 de 2)Luis Francisco Pérez MendozaAún no hay calificaciones
- Implementación de Un Cubo OlapDocumento16 páginasImplementación de Un Cubo OlapLuis Daniel RiderAún no hay calificaciones
- LaboratoriosBDII PDFDocumento20 páginasLaboratoriosBDII PDFJosué MaidanaAún no hay calificaciones
- Consideraciones para Migrar SQL Server 2000Documento3 páginasConsideraciones para Migrar SQL Server 2000Liliana SanchezAún no hay calificaciones
- Apunte Curso SQL Server ProgramBIDocumento42 páginasApunte Curso SQL Server ProgramBIJOSEAún no hay calificaciones
- Grupo G5-LeapfrogDocumento76 páginasGrupo G5-Leapfrogleydy nataliaAún no hay calificaciones
- Capitulo 3Documento80 páginasCapitulo 3lupitawomanAún no hay calificaciones
- Importar Base de Datos Como Crear Vistas y CubosDocumento15 páginasImportar Base de Datos Como Crear Vistas y CubospatricialuengocarreteroAún no hay calificaciones
- Inteligencia de Negocio (BI)Documento16 páginasInteligencia de Negocio (BI)Edwin CaruajulcaAún no hay calificaciones
- Process MakerDocumento27 páginasProcess MakerWilson DK100% (1)
- Laboratorio-N-04 Poblando Un DW PDFDocumento15 páginasLaboratorio-N-04 Poblando Un DW PDFjenniferAún no hay calificaciones
- Trabajo #4Documento20 páginasTrabajo #4Cris ZepedaAún no hay calificaciones
- SQL SERVER - Importar Exportar Datos Usando DTSDocumento13 páginasSQL SERVER - Importar Exportar Datos Usando DTSOrBatista RutssoAún no hay calificaciones
- SQL Server Net CoreDocumento30 páginasSQL Server Net CoreRicardo Aranibar LeonAún no hay calificaciones
- SQL - Tutorial ETL - Parte 2Documento14 páginasSQL - Tutorial ETL - Parte 2Jose Juan Mayo RiosAún no hay calificaciones
- Conectividad Con Bases de DatosDocumento27 páginasConectividad Con Bases de DatosJoseLudianAún no hay calificaciones
- Actiividad 4.2 Proyecto BiDocumento15 páginasActiividad 4.2 Proyecto BiArturo López PinedaAún no hay calificaciones
- Cómo Copiar Tablas de Una Base de Datos A Otra en SQL ServerDocumento21 páginasCómo Copiar Tablas de Una Base de Datos A Otra en SQL ServeromarAún no hay calificaciones
- Laboratorio BI PDFDocumento47 páginasLaboratorio BI PDFFátima Rodríguez LlicánAún no hay calificaciones
- Microsoft SQL Server Introducción A La MigraciónDocumento12 páginasMicrosoft SQL Server Introducción A La MigraciónAnapenzolAún no hay calificaciones
- Balotario Taller de Base de DatosDocumento6 páginasBalotario Taller de Base de DatosHenry SorianoAún no hay calificaciones
- Guia para Examen de Administracion de Base de Datos Tercer ParcialDocumento11 páginasGuia para Examen de Administracion de Base de Datos Tercer Parcialdavidrey29Aún no hay calificaciones
- Tema 2Documento27 páginasTema 2Luis CuriAún no hay calificaciones
- Ta MicoDocumento33 páginasTa MicoJose MeraAún no hay calificaciones
- BD Con JSPDocumento16 páginasBD Con JSPCristhian Jairo Olaya ZarateAún no hay calificaciones
- Guia para Laboratorio de SQL DeveloperDocumento10 páginasGuia para Laboratorio de SQL DeveloperRodrigo AguileraAún no hay calificaciones
- Actividad Aa8-Ev4 - Bases de Datos de Conocimiento - Gestión y Seguridad de Bases de DatosDocumento15 páginasActividad Aa8-Ev4 - Bases de Datos de Conocimiento - Gestión y Seguridad de Bases de Datoseusevio barcosAún no hay calificaciones
- Implementar Un Proceso EtlDocumento29 páginasImplementar Un Proceso EtlFélix DurangoAún no hay calificaciones
- Lima Norte - Garcia Bermudez Alan AliDocumento59 páginasLima Norte - Garcia Bermudez Alan AliJuan R. E.Aún no hay calificaciones
- MemoriaDocumento51 páginasMemoriaamanecerbo2scribdAún no hay calificaciones
- Modulo 4Documento25 páginasModulo 4Sofia NordforsAún no hay calificaciones
- Trabajo Final ArquitecturaDocumento40 páginasTrabajo Final ArquitecturaWendy1026Aún no hay calificaciones
- Instalacion de Cubos Manual en SQL2012 PDFDocumento80 páginasInstalacion de Cubos Manual en SQL2012 PDFhugotmokAún no hay calificaciones
- Conexion VB A MysqlDocumento11 páginasConexion VB A MysqlNelson Angel NinaAún no hay calificaciones
- Ingeniería en Reversa de DB2 IseriesDocumento5 páginasIngeniería en Reversa de DB2 IserieszuziilaraAún no hay calificaciones
- Oracle - Prctica 1Documento12 páginasOracle - Prctica 1javiersinho08100% (1)
- Automatizacion Del Proceso de Migracion de Bases de DatosDocumento11 páginasAutomatizacion Del Proceso de Migracion de Bases de DatosMario ZeballosAún no hay calificaciones
- Informe Gestion de La InformacionDocumento26 páginasInforme Gestion de La InformacionFelipe CruzAún no hay calificaciones
- Actividad 3.4 Desarrollo de Ejercicio BiDocumento29 páginasActividad 3.4 Desarrollo de Ejercicio BiArturo López PinedaAún no hay calificaciones
- Cargando VarioCargando Varios Flat File en Paralelos Flat File en ParaleloDocumento6 páginasCargando VarioCargando Varios Flat File en Paralelos Flat File en ParaleloAnonymous QcNfJFYxarAún no hay calificaciones
- Conexion BDDocumento8 páginasConexion BDIplanexAún no hay calificaciones
- Informe 804Documento11 páginasInforme 804Alex YanzaAún no hay calificaciones
- Sem05 U3 Plantilla OG01Documento7 páginasSem05 U3 Plantilla OG01Gerardo Mitchell Ugarte MattaAún no hay calificaciones
- Integration Services Pieza Fundamental de Los Proyectos de BI Parte 2 de 2Documento4 páginasIntegration Services Pieza Fundamental de Los Proyectos de BI Parte 2 de 2Jose LuisAún no hay calificaciones
- T4 - U3 - Practica 2 Intalación de SQL Server Con Asignación de Disco - Aldahir Calderón CruzDocumento11 páginasT4 - U3 - Practica 2 Intalación de SQL Server Con Asignación de Disco - Aldahir Calderón Cruzaldahir calderon cruzAún no hay calificaciones
- Examen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2De EverandExamen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2Aún no hay calificaciones
- Tarea 12 - Analisis Con ExcelDocumento14 páginasTarea 12 - Analisis Con ExcelTinker gameAún no hay calificaciones
- Tarea 11 - Analisis Con SQLDocumento4 páginasTarea 11 - Analisis Con SQLTinker gameAún no hay calificaciones
- Tarea 4 - DWHDocumento7 páginasTarea 4 - DWHTinker gameAún no hay calificaciones
- Tarea - Perfilado de Las Fuentes de DatosDocumento12 páginasTarea - Perfilado de Las Fuentes de DatosTinker gameAún no hay calificaciones
- Plataformas Digitales EmergentesDocumento12 páginasPlataformas Digitales EmergenteshulkjoseAún no hay calificaciones
- Identificando Los Objetivos Del SistemaDocumento4 páginasIdentificando Los Objetivos Del SistemaHilda AguirreAún no hay calificaciones
- Cuadro Sipnotico Sistemas de InformacionDocumento1 páginaCuadro Sipnotico Sistemas de Informacioncacm_1982Aún no hay calificaciones
- ODOODocumento32 páginasODOOAndrea Villatoro LópezAún no hay calificaciones
- Nivel 3 PA 2024 Base de DatosDocumento16 páginasNivel 3 PA 2024 Base de DatosMariano InsaurraldeAún no hay calificaciones
- TEMA 2 - Manejo de ConectoresDocumento13 páginasTEMA 2 - Manejo de ConectoresikiturbeAún no hay calificaciones
- Ejercicios SQL PDFDocumento6 páginasEjercicios SQL PDFFerneyAún no hay calificaciones
- Manual CVOSOFT Curso Introduccion A SAP Unidad 1Documento128 páginasManual CVOSOFT Curso Introduccion A SAP Unidad 1MARYELIS NUÑEZAún no hay calificaciones
- Encadenamiento de FilasDocumento2 páginasEncadenamiento de FilasFabio RodriguezAún no hay calificaciones
- Lecciones Aprendidas en Desarrollo de Software - Product Backlog Ejemplo - Social Restaurant Wall - SoReWa - Alejandro ArbelaezDocumento13 páginasLecciones Aprendidas en Desarrollo de Software - Product Backlog Ejemplo - Social Restaurant Wall - SoReWa - Alejandro ArbelaezFederico CórdobaAún no hay calificaciones
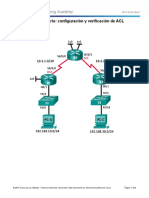
- Actividad 3 - Configuración y Verificación de ACL ExtendidasDocumento9 páginasActividad 3 - Configuración y Verificación de ACL ExtendidasAlvaro TorresAún no hay calificaciones
- Tecnologia de La Informatica Tarea 7Documento9 páginasTecnologia de La Informatica Tarea 7Rafael FelizAún no hay calificaciones
- TroyanoDocumento6 páginasTroyanoSarayAún no hay calificaciones
- Mapa ConceptualDocumento1 páginaMapa ConceptualQuinto05Aún no hay calificaciones
- Tecnologías de La Información y La ComunicaciónDocumento2 páginasTecnologías de La Información y La ComunicaciónferchuacoAún no hay calificaciones
- Instructivo de Ingreso A La Plataforma Virtual SENCICODocumento5 páginasInstructivo de Ingreso A La Plataforma Virtual SENCICOVictor Manuel Rojas SamameAún no hay calificaciones
- Arquitectura Del Sistema Gestor de Bases de DatosDocumento18 páginasArquitectura Del Sistema Gestor de Bases de DatosPolet A.Aún no hay calificaciones
- Articulo de Cadena de Valor en Empresas de Servicios de Tecnologías de Información (TI)Documento6 páginasArticulo de Cadena de Valor en Empresas de Servicios de Tecnologías de Información (TI)Jhor Moscol GarayAún no hay calificaciones
- Proyecto de Investigación de Gestión de Servicios InformáticosDocumento60 páginasProyecto de Investigación de Gestión de Servicios InformáticosDaniel ACAún no hay calificaciones
- Lab07 Consultas Con SQLDocumento11 páginasLab07 Consultas Con SQLPedro PalominoAún no hay calificaciones
- Estructura de Un Sistema de Base de DatosDocumento10 páginasEstructura de Un Sistema de Base de DatosCarlos MaguiñaAún no hay calificaciones
- Fundamentos de La Informática (Mapa Mental)Documento2 páginasFundamentos de La Informática (Mapa Mental)Alejandra GarcíaAún no hay calificaciones
- DFo Practica 1 2Documento3 páginasDFo Practica 1 2emeliAún no hay calificaciones
- Actividad 2 Logistica y OperacionesDocumento8 páginasActividad 2 Logistica y Operacionesnestor beltranAún no hay calificaciones
- Hacia Donde Se Dirige La TGADocumento48 páginasHacia Donde Se Dirige La TGAAnabella CastroAún no hay calificaciones
- Modelo Relacional Estatico y DinamicoDocumento18 páginasModelo Relacional Estatico y DinamicoNorbert Dvj HopAún no hay calificaciones
- Hoja de Vida Analisis y Desarrollo Del SofwareDocumento2 páginasHoja de Vida Analisis y Desarrollo Del SofwareDANIEL BETANCUR CHAVERRAAún no hay calificaciones
- Guía-REPORTE-BEC - CiberseguridadDocumento12 páginasGuía-REPORTE-BEC - CiberseguridadSergio CastañedaAún no hay calificaciones
- Sentencias MYSQLDocumento9 páginasSentencias MYSQLJosselyn VásquezAún no hay calificaciones
- Requerimiento InternetDocumento3 páginasRequerimiento InternetangelAún no hay calificaciones