También podría gustarte
- Prueba TecnicaDocumento3 páginasPrueba TecnicaJOHN CORTES100% (1)
- Java JTable CRUDDocumento5 páginasJava JTable CRUDJuan Pedro Santos FernándezAún no hay calificaciones
- Problemas propuestos de cadenas de caracteres y soluciones en JavaDocumento7 páginasProblemas propuestos de cadenas de caracteres y soluciones en JavaDany Ayrton Santisteban RodriguezAún no hay calificaciones
- ProgramaciónDocumento14 páginasProgramaciónANDREA CAROLINA SERRATO CHINCHILLA100% (2)
- Piero Semana6Documento8 páginasPiero Semana6anarteagabrAún no hay calificaciones
- Reto 5Documento4 páginasReto 5Cesar LopezAún no hay calificaciones
- Creacion de Encriptado en Coneccion de Base de Datos MysqlDocumento7 páginasCreacion de Encriptado en Coneccion de Base de Datos MysqlShubert ChavezAún no hay calificaciones
- Public Class PalindromoDocumento15 páginasPublic Class PalindromoJavier Sneider Porras MedinaAún no hay calificaciones
- Punto 7 y 8 Entrega ProgramaciónDocumento4 páginasPunto 7 y 8 Entrega ProgramaciónANDREA CAROLINA SERRATO CHINCHILLA100% (1)
- Ejercicio 2 PDFDocumento13 páginasEjercicio 2 PDFbolin3001Aún no hay calificaciones
- Laboratorio 06Documento11 páginasLaboratorio 06Renzo Porta CalderonAún no hay calificaciones
- Contraseña seguraDocumento24 páginasContraseña seguraWilson Fernando CorreaAún no hay calificaciones
- Programa Del VideoDocumento2 páginasPrograma Del VideoulisesAún no hay calificaciones
- Validacion y Clasificacion de DatosDocumento5 páginasValidacion y Clasificacion de DatosMauricio Alejandro Riquelme AguirreAún no hay calificaciones
- Control 4 .Net IIDocumento11 páginasControl 4 .Net IIJavier Andres Serrano LeivaAún no hay calificaciones
- Ejercicios_de_programación_en_CDocumento19 páginasEjercicios_de_programación_en_CMAMA GUEBO100% (1)
- Tarea 1 de 5 Programas en Grupo (1)Documento4 páginasTarea 1 de 5 Programas en Grupo (1)diegocelrodriguezAún no hay calificaciones
- Ejemplos Java NetbeansDocumento8 páginasEjemplos Java NetbeansGloria GeronimaAún no hay calificaciones
- Tema IpDocumento50 páginasTema IpArpad NogyAún no hay calificaciones
- Leo ProgramadorDocumento9 páginasLeo ProgramadorKrystopher Gianpablo Correa JuarezAún no hay calificaciones
- FredyyymolinaaaDocumento11 páginasFredyyymolinaaafredyAún no hay calificaciones
- Ejercicio 1: Escribe Una Función en Python Que Revierta Una Cadena de PalabrasDocumento8 páginasEjercicio 1: Escribe Una Función en Python Que Revierta Una Cadena de PalabrasGerman Galdamez OvandoAún no hay calificaciones
- Ejercicios recursividad inversión cadena suma pares rango quitar vocales mayúsculas prohibidaDocumento7 páginasEjercicios recursividad inversión cadena suma pares rango quitar vocales mayúsculas prohibidaAngel Ulises Ortiz RojasAún no hay calificaciones
- Algoritmos 2Documento19 páginasAlgoritmos 2Juan Camilo Peña NeitaAún no hay calificaciones
- Interfaz Grafica para Captura de DatosDocumento8 páginasInterfaz Grafica para Captura de DatosJuan LopezAún no hay calificaciones
- Tarea No. 5 - Ejercicios 3.2 y 3.3Documento7 páginasTarea No. 5 - Ejercicios 3.2 y 3.3LUIS ESTUARDO PATZAN LOPEZAún no hay calificaciones
- Código JavaDocumento42 páginasCódigo JavaRousi Flores VásquezAún no hay calificaciones
- Dev C++Documento13 páginasDev C++Johanna Negrete SanchezAún no hay calificaciones
- Diferencias DivididasDocumento15 páginasDiferencias DivididasKevin SotoAún no hay calificaciones
- AvanceDocumento4 páginasAvanceJOSE SEBASTIAN BRIONES GIRONAún no hay calificaciones
- Lab2 Applets Con InteracciónDocumento25 páginasLab2 Applets Con Interacciónbolin3001Aún no hay calificaciones
- Algoritmos recursivosDocumento28 páginasAlgoritmos recursivosJensen Enmanuel Hernández González100% (1)
- Practica 4 ReporteDocumento14 páginasPractica 4 ReporteChris CastilloAún no hay calificaciones
- El AhorcadoDocumento8 páginasEl AhorcadoRodrigoAún no hay calificaciones
- Ordenamiento de arreglos y búsqueda de estadísticasDocumento8 páginasOrdenamiento de arreglos y búsqueda de estadísticasMiguelRnRcAún no hay calificaciones
- Script TelepizzaDocumento2 páginasScript TelepizzaAdn GenAún no hay calificaciones
- Ejercicios Propuestos Unidad 2Documento22 páginasEjercicios Propuestos Unidad 2Luz Day Torres ReyesAún no hay calificaciones
- GuiaLab5 ProgramacionEnJavaDocumento12 páginasGuiaLab5 ProgramacionEnJavaSofy CastilloAún no hay calificaciones
- Archivos JavaDocumento5 páginasArchivos JavaManuel Alvariño TorresAún no hay calificaciones
- Programa de Los Cuadrados MediosDocumento9 páginasPrograma de Los Cuadrados Mediosmfloza45850% (1)
- Convertir números a letras C# menos deDocumento5 páginasConvertir números a letras C# menos dejose vicenteAún no hay calificaciones
- Instituto Tecnologico Del Istm1Documento19 páginasInstituto Tecnologico Del Istm1josue luisruizAún no hay calificaciones
- Clase Conexion A Base de DatosDocumento9 páginasClase Conexion A Base de DatosMartha ElenaAún no hay calificaciones
- Base de Datos (SQLite) Con PyQt5 - Interfaces Gráficas - Mi Diario PythonDocumento14 páginasBase de Datos (SQLite) Con PyQt5 - Interfaces Gráficas - Mi Diario Pythonalejandro rodriguez nuñezAún no hay calificaciones
- EncriptacionDocumento8 páginasEncriptacionIvan Bancho C. GomezAún no hay calificaciones
- Examen TorresDocumento6 páginasExamen TorresNeji HyugaAún no hay calificaciones
- Entrega Final - Programacion de ComputadoresDocumento18 páginasEntrega Final - Programacion de ComputadoresSofia Galvez IbarraAún no hay calificaciones
- Universidad de CartagenaDocumento23 páginasUniversidad de Cartagenadavinso gonzalesAún no hay calificaciones
- Arreglos de números aleatorios y matrices transpuestasDocumento17 páginasArreglos de números aleatorios y matrices transpuestasFabian IbarraAún no hay calificaciones
- Insertar palabras en matriz CDocumento16 páginasInsertar palabras en matriz CJANN ARTHUR CHAVEZ CASTILLOAún no hay calificaciones
- Entrega Semana 7Documento4 páginasEntrega Semana 7J MINAún no hay calificaciones
- Ejercicios Java vectores y matricesDocumento14 páginasEjercicios Java vectores y matricesherlanchambiAún no hay calificaciones
- Entregas Final ProgramacionDocumento20 páginasEntregas Final ProgramacionRaquelMartinez100% (1)
- Año de la inversión ruralDocumento13 páginasAño de la inversión ruralAndrea Machuca LopezAún no hay calificaciones
- EjsimprimirmasDocumento53 páginasEjsimprimirmasAlejandro Nistal VillarroelAún no hay calificaciones
- Metodos de Organizacion en JavaDocumento8 páginasMetodos de Organizacion en Javaelmer edu ojedaAún no hay calificaciones
- Import Java Clases y FuncionesDocumento11 páginasImport Java Clases y FuncionesAlex ZumaetaAún no hay calificaciones
- Clases de NetsbeansDocumento3 páginasClases de NetsbeansLuis ArteagaAún no hay calificaciones
- 2048Documento4 páginas2048Ivan PinedaAún no hay calificaciones
- Crea y Publica tu App Android: Aprende a programar y crea tu app con Kotlin + Jetpack ComposeDe EverandCrea y Publica tu App Android: Aprende a programar y crea tu app con Kotlin + Jetpack ComposeAún no hay calificaciones
- Reporte de PracticaDocumento12 páginasReporte de PracticaRoberto GarciaAún no hay calificaciones
- Práctica Emmanuel López Guzmán 1Documento33 páginasPráctica Emmanuel López Guzmán 1Roberto GarciaAún no hay calificaciones
- Análisis semántico en compiladoresDocumento12 páginasAnálisis semántico en compiladoresRoberto GarciaAún no hay calificaciones
- Presentación 1Documento5 páginasPresentación 1Roberto GarciaAún no hay calificaciones
- Tema2 Equiposaevaluarparaunareddecomputadoras LuisAlbertoGarcíaTadeoDocumento8 páginasTema2 Equiposaevaluarparaunareddecomputadoras LuisAlbertoGarcíaTadeoRoberto GarciaAún no hay calificaciones
- Investigacion U 4Documento10 páginasInvestigacion U 4Roberto GarciaAún no hay calificaciones
- Generación de código objetoDocumento22 páginasGeneración de código objetoRoberto GarciaAún no hay calificaciones
- Protocolo de Investigación PlantillaDocumento15 páginasProtocolo de Investigación PlantillaRoberto GarciaAún no hay calificaciones
- Cuadro CompararativoDocumento4 páginasCuadro CompararativoRoberto GarciaAún no hay calificaciones
- Planificación Del ProyectoDocumento7 páginasPlanificación Del ProyectoRoberto GarciaAún no hay calificaciones
- Hoja Membretada - AD2022Documento8 páginasHoja Membretada - AD2022Roberto GarciaAún no hay calificaciones
- FichasDocumento2 páginasFichasRoberto GarciaAún no hay calificaciones
- Instrumento de Recopilación de Datos 22BDocumento4 páginasInstrumento de Recopilación de Datos 22BRoberto GarciaAún no hay calificaciones
- Glitter Plotter Eco Solvente 1601 Xp600 211120231Documento6 páginasGlitter Plotter Eco Solvente 1601 Xp600 211120231Gerardo BarreraAún no hay calificaciones
- Presentacion OWASP Seguridad2.0Documento9 páginasPresentacion OWASP Seguridad2.0oscar_o_a6863Aún no hay calificaciones
- Primer Parcial AnalisisDocumento8 páginasPrimer Parcial AnalisisVelásquez Fuentes HarolAún no hay calificaciones
- S01.s1 - MaterialDocumento39 páginasS01.s1 - MaterialEmilio Contreras Sánchez0% (1)
- Factura Electronica - Impresion - 134Documento1 páginaFactura Electronica - Impresion - 134MARCOSAún no hay calificaciones
- Newton-Raphson - Análisis NcoDocumento9 páginasNewton-Raphson - Análisis NcoMaría Fernanda RuízAún no hay calificaciones
- Tarea 1 - Grupo 2 PDFDocumento12 páginasTarea 1 - Grupo 2 PDFLorena Domitila Abad Viejó100% (2)
- Formato Reporte AnalisisDocumento4 páginasFormato Reporte AnalisisIsrael GómezAún no hay calificaciones
- Parts Products UndercarriageDocumento61 páginasParts Products UndercarriageGLOZOYA25Aún no hay calificaciones
- Introducción ExcelDocumento24 páginasIntroducción ExcelAylin MejiaAún no hay calificaciones
- BDUA-G01 Reportes Presuntos Repetidos V01 PDFDocumento12 páginasBDUA-G01 Reportes Presuntos Repetidos V01 PDFTaz EtherBitsAún no hay calificaciones
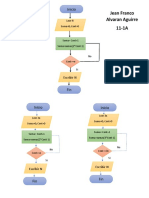
- Diagramas de Flujo, Jean Franco AlvaranDocumento6 páginasDiagramas de Flujo, Jean Franco AlvaranAndres GamboaAún no hay calificaciones
- Gestión de Proyectos WebDocumento15 páginasGestión de Proyectos WebAlbertoAún no hay calificaciones
- Utp Sistemas Ing Software 2018Documento2 páginasUtp Sistemas Ing Software 2018Alanis Akira PeñalbaAún no hay calificaciones
- Instalación SQL/SAP servidores virtualesDocumento17 páginasInstalación SQL/SAP servidores virtualesLuis GarcíaAún no hay calificaciones
- UntitledDocumento48 páginasUntitledAndres MolinaAún no hay calificaciones
- Ensayo Sobre AutoCADDocumento4 páginasEnsayo Sobre AutoCADjuan zarateAún no hay calificaciones
- Distribuidora de Lubricantes Essa Eirl: R.U.C. #20100279003 Factura Electrónica F001 #00028562Documento1 páginaDistribuidora de Lubricantes Essa Eirl: R.U.C. #20100279003 Factura Electrónica F001 #00028562yilberth mejiasAún no hay calificaciones
- Pasos para Filtar La Data Odk Por MunicipioDocumento8 páginasPasos para Filtar La Data Odk Por MunicipiomelissAún no hay calificaciones
- Cuadro Sinoptico Sobre Las Medidas Usadas para El AlmacenamientoDocumento3 páginasCuadro Sinoptico Sobre Las Medidas Usadas para El AlmacenamientoRusmeri PerezAún no hay calificaciones
- Logtransmision 20230627Documento101 páginasLogtransmision 20230627Manuel FloresAún no hay calificaciones
- CFDI carnes finas San Juan La RiojaDocumento1 páginaCFDI carnes finas San Juan La RiojaAlejandro SalasAún no hay calificaciones
- Bases de Datos, Diseño, Implementación Y Administración - 9 Edición PDF - Descargar, Leer DESCARGAR LEER ENGLISH VERSION DOWNLOAD READ.Documento11 páginasBases de Datos, Diseño, Implementación Y Administración - 9 Edición PDF - Descargar, Leer DESCARGAR LEER ENGLISH VERSION DOWNLOAD READ.IT China Jenner NoelAún no hay calificaciones
- Ejercicios HTMLDocumento3 páginasEjercicios HTMLNohelia del cisne Reyes MachucaAún no hay calificaciones
- Control Lógico AvanzadoDocumento23 páginasControl Lógico AvanzadoaleAún no hay calificaciones
- Bloques Ev3ClassroomDocumento35 páginasBloques Ev3ClassroomdatorresjAún no hay calificaciones
- Carta Recomendacion Estandar - Ejemplos de CartaDocumento4 páginasCarta Recomendacion Estandar - Ejemplos de CartaJ Willy Chavez MolinaAún no hay calificaciones
- GherkinDocumento6 páginasGherkinjuanchemoAún no hay calificaciones
- Mendoza Arteaga AlonsoDocumento3 páginasMendoza Arteaga AlonsoAlonsoMendozaAún no hay calificaciones
- Taller de Historias de UsuarioDocumento15 páginasTaller de Historias de UsuarioDiego Plascencia MAún no hay calificaciones