También podría gustarte
- Actividad 2. Intervalos de Confianza para La Media y ProporciónDocumento5 páginasActividad 2. Intervalos de Confianza para La Media y ProporciónYareli Becerra chavezAún no hay calificaciones
- Estadistica AplicadaDocumento189 páginasEstadistica AplicadainfosamuAún no hay calificaciones
- Inferencia EstadísticaDocumento49 páginasInferencia EstadísticaUSMP FN ARCHIVOSAún no hay calificaciones
- 02 DescriptivaDocumento14 páginas02 DescriptivaVillacis IsraelAún no hay calificaciones
- 2Documento3 páginas2juan brubanoAún no hay calificaciones
- Sesion 4. Estimacion de ParametrosDocumento24 páginasSesion 4. Estimacion de ParametrosAndrew LaltAún no hay calificaciones
- Cómo Seleccionar El Tamaño de MuestraDocumento5 páginasCómo Seleccionar El Tamaño de MuestraAnders OrtixAún no hay calificaciones
- U3 EstimadoresDocumento32 páginasU3 EstimadoresbeatgerAún no hay calificaciones
- Ex s08Documento11 páginasEx s08Jair MontalvoAún no hay calificaciones
- INVESTIGACIÓNDocumento5 páginasINVESTIGACIÓNKevin VenegasAún no hay calificaciones
- Ic NutricionDocumento13 páginasIc Nutricioncamilo100% (1)
- Trabajo EstimacionDocumento8 páginasTrabajo EstimacionLibardo SánchezAún no hay calificaciones
- Estimación de parámetros estadísticosDocumento5 páginasEstimación de parámetros estadísticosPlaza Yesca Miguel AngelAún no hay calificaciones
- Semana 11Documento52 páginasSemana 11Anthony SaldanaAún no hay calificaciones
- Parte Del Trabajo Gabriel CastroDocumento8 páginasParte Del Trabajo Gabriel Castrogabriel castroAún no hay calificaciones
- Estimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesDocumento16 páginasEstimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesleoastorsAún no hay calificaciones
- Ruta EstimaciónDocumento8 páginasRuta EstimaciónpotatochipAún no hay calificaciones
- L05 PDFDocumento7 páginasL05 PDFDiego AntonioAún no hay calificaciones
- 08 - Estimación Por Intervalo de ConfianzaDocumento6 páginas08 - Estimación Por Intervalo de ConfianzaMatias SilveraAún no hay calificaciones
- Estimación Puntual e Interválixa en Media y Proporciones TGDocumento10 páginasEstimación Puntual e Interválixa en Media y Proporciones TGjazmin VallesAún no hay calificaciones
- Estadistica TrabajoDocumento34 páginasEstadistica TrabajoricardoAún no hay calificaciones
- Fase 2 Victor SanchezDocumento10 páginasFase 2 Victor SanchezKevin TorresAún no hay calificaciones
- Estadistica AplicadaDocumento178 páginasEstadistica AplicadaDarrell Baker74% (23)
- Intervalos de confianza para estimación de parámetrosDocumento13 páginasIntervalos de confianza para estimación de parámetrosLucho Enrique0% (1)
- Estadística y ProbabilidadDocumento11 páginasEstadística y ProbabilidadCatherine CastillaAún no hay calificaciones
- Prueba de Suma de RangosDocumento17 páginasPrueba de Suma de RangosmaxiveinteAún no hay calificaciones
- Resumen Intervalos de Confianza y TLCDocumento10 páginasResumen Intervalos de Confianza y TLC_niloAún no hay calificaciones
- Archivo ColeguitaDocumento8 páginasArchivo ColeguitaCesar Rosas TomayllaAún no hay calificaciones
- Intervalos Confianza Ae6 1Documento2 páginasIntervalos Confianza Ae6 1César AvilésAún no hay calificaciones
- ESTIMACIONDocumento3 páginasESTIMACIONmicaelasnopekAún no hay calificaciones
- Estimacion Intervalo de ConfianzaDocumento11 páginasEstimacion Intervalo de ConfianzaBelial PrimathAún no hay calificaciones
- Unidad IDocumento19 páginasUnidad IEli Samuel Regalado GarciaAún no hay calificaciones
- Apuntes Estadística - Tema 2. Intervalos de ProbabilidadDocumento6 páginasApuntes Estadística - Tema 2. Intervalos de ProbabilidadJenny AndujarAún no hay calificaciones
- Estimacion de Parametros - ESTADISTICADocumento7 páginasEstimacion de Parametros - ESTADISTICABryan Thom BarrioshAún no hay calificaciones
- Estimacion de razon y regresionDocumento3 páginasEstimacion de razon y regresioncentronivelacioncontinuaAún no hay calificaciones
- Introducción Al MuestreoDocumento16 páginasIntroducción Al MuestreoNina DecvakAún no hay calificaciones
- Tema 4.2. ApuntesDocumento11 páginasTema 4.2. ApuntesCarlosAún no hay calificaciones
- Distribucion T StudentDocumento19 páginasDistribucion T StudentSheily Roncal MendozaAún no hay calificaciones
- Intervalo de ConfianzaDocumento39 páginasIntervalo de ConfianzaIngridAvilaAún no hay calificaciones
- Lectura Teoria y Ejercicios EstimacionDocumento7 páginasLectura Teoria y Ejercicios Estimacionkeneth portillaAún no hay calificaciones
- Documento PowerPoint Nixon LeeonelDocumento10 páginasDocumento PowerPoint Nixon LeeonelLeonel Nixon Garcia CordovaAún no hay calificaciones
- Clase 15. Estadística IDocumento16 páginasClase 15. Estadística IbreinerAún no hay calificaciones
- Procesamiento Análisis Estadistico e Interpretacion de La InformaciónDocumento6 páginasProcesamiento Análisis Estadistico e Interpretacion de La InformaciónHerbertAún no hay calificaciones
- Estadística InferencialDocumento12 páginasEstadística InferencialAngie Yetzell Rico LópezAún no hay calificaciones
- EstimacionDocumento32 páginasEstimacionAnonymous VfYp64HW6CAún no hay calificaciones
- Estimación Puntual Del Promedio.Documento22 páginasEstimación Puntual Del Promedio.Yuleidys MezaAún no hay calificaciones
- Estimacion PuntualDocumento14 páginasEstimacion PuntualFredo GodofredoAún no hay calificaciones
- Tema 11-12 Inferencia Estadistica Ccss IIDocumento29 páginasTema 11-12 Inferencia Estadistica Ccss IItoya123Aún no hay calificaciones
- 2020 Estimación de Parametros y Pruebas de HipotesisDocumento51 páginas2020 Estimación de Parametros y Pruebas de HipotesisJavi OlmAún no hay calificaciones
- Capitulo 5 EstadisticaDocumento5 páginasCapitulo 5 EstadisticaJeffreyAún no hay calificaciones
- Estadística - Semana 11 v2Documento30 páginasEstadística - Semana 11 v2Violeta SánchezAún no hay calificaciones
- Unidad 2-Estimaciones-HoracioRancesFonsecaCamachoDocumento48 páginasUnidad 2-Estimaciones-HoracioRancesFonsecaCamachoAbraham VelázquezAún no hay calificaciones
- Estadistica Taller 4Documento5 páginasEstadistica Taller 4Felipe MejiaAún no hay calificaciones
- Capítulo Vi - 1Documento53 páginasCapítulo Vi - 1Ayrton Torres BarretoAún no hay calificaciones
- Pruebas estadísticas paramétricas: intervalos de confianzaDocumento36 páginasPruebas estadísticas paramétricas: intervalos de confianzajennifertellomAún no hay calificaciones
- Calibración Instrumental Análisis QuímicoDocumento13 páginasCalibración Instrumental Análisis QuímicoLuis FrancoAún no hay calificaciones
- Estimación de parámetros poblacionales mediante intervalos de confianzaDocumento8 páginasEstimación de parámetros poblacionales mediante intervalos de confianzaJUAN FERNANDO ARESTEGUI HUILLCAAún no hay calificaciones
- Estimación estadística e inferenciaDocumento69 páginasEstimación estadística e inferenciaErnes Zuares OrtegaAún no hay calificaciones
- Trabajo Monografico Calculo T4Documento10 páginasTrabajo Monografico Calculo T4Josue Bonilla ChaconAún no hay calificaciones
- Universidad Privada Antenor Orrego: Escuela Profesional de Ingeniería CivilDocumento21 páginasUniversidad Privada Antenor Orrego: Escuela Profesional de Ingeniería CivilJosue Bonilla ChaconAún no hay calificaciones
- Exam Algebra Vect. 2017 2Documento4 páginasExam Algebra Vect. 2017 2Josue Bonilla ChaconAún no hay calificaciones
- Ecuaciones de La Recta en El Plano y EspacioDocumento7 páginasEcuaciones de La Recta en El Plano y EspacioJosue Bonilla ChaconAún no hay calificaciones
- Mate2 Coleg 3C 2Q2022Documento2 páginasMate2 Coleg 3C 2Q2022Josue Bonilla ChaconAún no hay calificaciones
- GUIA 6 Estudiantes Ecuaciones Diferenciales 2022Documento17 páginasGUIA 6 Estudiantes Ecuaciones Diferenciales 2022Josue Bonilla ChaconAún no hay calificaciones
- Diptico AlimentacionDocumento2 páginasDiptico AlimentaciondenyAún no hay calificaciones
- Libros digitales, exámenes y recursos múltiplesDocumento5 páginasLibros digitales, exámenes y recursos múltiplesJosue Bonilla ChaconAún no hay calificaciones
- 6 Capitulo Vi - Mecanica Estructural Rev 2Documento48 páginas6 Capitulo Vi - Mecanica Estructural Rev 2Josue Bonilla ChaconAún no hay calificaciones
- Curvas InfotoDocumento1 páginaCurvas InfotoJosue Bonilla ChaconAún no hay calificaciones
- 7 Capitulo Vii - Mecanica Estructural Rev 2Documento28 páginas7 Capitulo Vii - Mecanica Estructural Rev 2Josue Bonilla ChaconAún no hay calificaciones
- 5 Capitulo V - Mecanica Estructural Rev2Documento37 páginas5 Capitulo V - Mecanica Estructural Rev2Josue Bonilla ChaconAún no hay calificaciones
- Libros digitales, exámenes y recursos múltiplesDocumento4 páginasLibros digitales, exámenes y recursos múltiplesJosue Bonilla ChaconAún no hay calificaciones
- Exam Algebra Vect. 2018 0Documento5 páginasExam Algebra Vect. 2018 0Josue Bonilla ChaconAún no hay calificaciones
- Img 002Documento1 páginaImg 002Josue Bonilla ChaconAún no hay calificaciones
- Inequidad étnico-racial en el aseguramiento de salud ColombiaDocumento9 páginasInequidad étnico-racial en el aseguramiento de salud ColombiaJosue Bonilla ChaconAún no hay calificaciones
- Tipo 1 Ef G2Documento2 páginasTipo 1 Ef G2Josue Bonilla ChaconAún no hay calificaciones
- Separata Funcion CompressDocumento37 páginasSeparata Funcion CompressJosue Bonilla ChaconAún no hay calificaciones
- CURSO DE MATEMÁTICA BÁSICADocumento3 páginasCURSO DE MATEMÁTICA BÁSICAJosue Bonilla ChaconAún no hay calificaciones
- 8 Capitulo Viii - Mecanica Estructural - Rev2Documento24 páginas8 Capitulo Viii - Mecanica Estructural - Rev2Josue Bonilla ChaconAún no hay calificaciones
- 15 16Documento2 páginas15 16Josue Bonilla ChaconAún no hay calificaciones
- Diptico La Familia - CompressDocumento3 páginasDiptico La Familia - CompressJosue Bonilla ChaconAún no hay calificaciones
- Normas educativas COVID-19Documento3 páginasNormas educativas COVID-19Josue Bonilla ChaconAún no hay calificaciones
- Contrato docente UGEL AmbDocumento2 páginasContrato docente UGEL AmbJosue Bonilla ChaconAún no hay calificaciones
- Statistics Book GaussDocumento9 páginasStatistics Book GaussJosue Bonilla ChaconAún no hay calificaciones
- Anexo 07Documento1 páginaAnexo 07Josue Bonilla ChaconAún no hay calificaciones
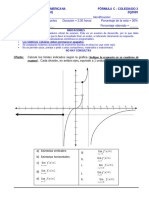
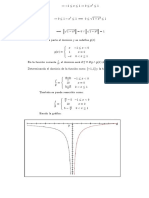
- Funciones f(x) y g(x): dominios, cálculo de f/g y gráficaDocumento2 páginasFunciones f(x) y g(x): dominios, cálculo de f/g y gráficaJosue Bonilla ChaconAún no hay calificaciones
- 4°PC Física 1 2020-1Documento1 página4°PC Física 1 2020-1Josue Bonilla ChaconAún no hay calificaciones
- Min 3Documento14 páginasMin 3Josue Bonilla ChaconAún no hay calificaciones