
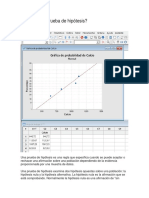
Prueba de Corridas Ó de Rach
Prueba de Corridas Ó de Rach
También podría gustarte
- Actividad 7 Estadistica InferencialDocumento10 páginasActividad 7 Estadistica InferencialVictor Martinez100% (3)
- Entregable 1Documento5 páginasEntregable 1Victor Hugo SdAún no hay calificaciones
- Prueba de HipótesisDocumento8 páginasPrueba de HipótesisdavidAún no hay calificaciones
- Prueba de Hipotesis 1Documento30 páginasPrueba de Hipotesis 1Paul SánchezAún no hay calificaciones
- Actividad Complementaria 2 Caso Practico Equipo 10Documento6 páginasActividad Complementaria 2 Caso Practico Equipo 10Roxssana GuardiolaAún no hay calificaciones
- CAPITULO10RHDocumento24 páginasCAPITULO10RHRoxssana GuardiolaAún no hay calificaciones
- Pia Soroxis Equipo10Documento7 páginasPia Soroxis Equipo10Roxssana GuardiolaAún no hay calificaciones
- Actividad Fundamental 1 - A. Com. de Los Met. de Val. de Puestos de Trabajo y Sus Funciones. - Equipo 10Documento8 páginasActividad Fundamental 1 - A. Com. de Los Met. de Val. de Puestos de Trabajo y Sus Funciones. - Equipo 10Roxssana GuardiolaAún no hay calificaciones
- Tarea 3 Estadistica InfDocumento15 páginasTarea 3 Estadistica InfRoxssana GuardiolaAún no hay calificaciones
- Actividad 5 DibujolabDocumento8 páginasActividad 5 DibujolabRoxssana GuardiolaAún no hay calificaciones
- Practica 10Documento5 páginasPractica 10Roxssana GuardiolaAún no hay calificaciones
- Practica 7 LabtgyvDocumento12 páginasPractica 7 LabtgyvRoxssana GuardiolaAún no hay calificaciones
- Características de Las Pruebas de HipótesisDocumento3 páginasCaracterísticas de Las Pruebas de HipótesisRoxssana GuardiolaAún no hay calificaciones
- Actividad 5 DibujolabDocumento8 páginasActividad 5 DibujolabRoxssana GuardiolaAún no hay calificaciones
- Actividad 3 Medicion de Flujo y Presion en El Sistema Hidraulico Segunda ParteDocumento6 páginasActividad 3 Medicion de Flujo y Presion en El Sistema Hidraulico Segunda ParteRoxssana GuardiolaAún no hay calificaciones
- Medición de PresiónDocumento1 páginaMedición de PresiónRoxssana GuardiolaAún no hay calificaciones
- MIV MM Separata PDFDocumento14 páginasMIV MM Separata PDFElizabeth Rengifo FloresAún no hay calificaciones
- EJERCICIOS CAPITULO 10 Pag 347Documento2 páginasEJERCICIOS CAPITULO 10 Pag 347Ana CoronelAún no hay calificaciones
- EA 418 Prueba No Paramétrica de Kruskal-WallisDocumento10 páginasEA 418 Prueba No Paramétrica de Kruskal-WallisJuan CarlosAún no hay calificaciones
- Análisis VarianzaDocumento20 páginasAnálisis VarianzakukiAún no hay calificaciones
- Tecnicas de MuestreoDocumento12 páginasTecnicas de MuestreoDennis Roman Coronado0% (1)
- SXSG EJ23 Proyecto FinalDocumento3 páginasSXSG EJ23 Proyecto FinalorlandoAún no hay calificaciones
- Universidad Nacional "Hermilio Valdizan": Facultad de Ingeniería Industrial Y Sistemas E.P Ingenieria IndustrialDocumento14 páginasUniversidad Nacional "Hermilio Valdizan": Facultad de Ingeniería Industrial Y Sistemas E.P Ingenieria IndustrialAnonymous fYRzAkdpLsAún no hay calificaciones
- TP2 - Minicaso Financial Advisor Inc - Luis BolivarDocumento4 páginasTP2 - Minicaso Financial Advisor Inc - Luis BolivarLuis BolivarAún no hay calificaciones
- MCODocumento34 páginasMCOglpiAún no hay calificaciones
- Proyecto FinalizadoDocumento89 páginasProyecto FinalizadoRicardo VillarrealAún no hay calificaciones
- ProblemasDocumento9 páginasProblemasJose Cabrera RuizAún no hay calificaciones
- (M2-E1) Evaluación (Prueba) - Estadística AplicadaDocumento8 páginas(M2-E1) Evaluación (Prueba) - Estadística AplicadaJENNIFER CORDINIAún no hay calificaciones
- Consulta ANOVADocumento7 páginasConsulta ANOVAViviana Ortiz ArbeláezAún no hay calificaciones
- Disenio ExperimentosDocumento119 páginasDisenio ExperimentosJay Pi100% (2)
- Inf Taller3 Jaime Figueredo PDFDocumento19 páginasInf Taller3 Jaime Figueredo PDFANGIE LORENA GUIO FERNANDEZAún no hay calificaciones
- Programa de Métodos Estadísticos - Universidad Autónoma de Santo DomingoDocumento9 páginasPrograma de Métodos Estadísticos - Universidad Autónoma de Santo DomingoAnnette Viola67% (3)
- Práctica 7Documento2 páginasPráctica 7oscar nevarezAún no hay calificaciones
- Syllabus Del Curso Inferencia Estadística +UNAD 2019 + 212064Documento14 páginasSyllabus Del Curso Inferencia Estadística +UNAD 2019 + 212064Fernando SuarezAún no hay calificaciones
- Pruebas de Hipotesis Con SpssDocumento31 páginasPruebas de Hipotesis Con SpssjoseAún no hay calificaciones
- Docima o Prueba de HipotesisDocumento9 páginasDocima o Prueba de HipotesisCamilo Bustamante SantanderAún no hay calificaciones
- INVESTIGACIONDocumento10 páginasINVESTIGACIONCielito HerreraAún no hay calificaciones
- Datos Enumerativos - Estad. IndustrialDocumento12 páginasDatos Enumerativos - Estad. IndustrialCristian Soto ParionaAún no hay calificaciones
- Pruebas de HipotesisDocumento16 páginasPruebas de HipotesisPaola OrdoñezAún no hay calificaciones
- Analisis de Varianza PDFDocumento79 páginasAnalisis de Varianza PDFMichaelAragonLuqueAún no hay calificaciones
- Negocios y EconomíaDocumento4 páginasNegocios y Economíaisrael lopez ramirezAún no hay calificaciones
- Qué Es La Distribución Chi CuadradaDocumento5 páginasQué Es La Distribución Chi CuadradaBLANCA ESTELA SANTIAGO HERNANDEZAún no hay calificaciones








































También podría gustarte
- Actividad 7 Estadistica InferencialDocumento10 páginasActividad 7 Estadistica InferencialVictor Martinez100% (3)
- Entregable 1Documento5 páginasEntregable 1Victor Hugo SdAún no hay calificaciones
- Prueba de HipótesisDocumento8 páginasPrueba de HipótesisdavidAún no hay calificaciones
- Prueba de Hipotesis 1Documento30 páginasPrueba de Hipotesis 1Paul SánchezAún no hay calificaciones
- Actividad Complementaria 2 Caso Practico Equipo 10Documento6 páginasActividad Complementaria 2 Caso Practico Equipo 10Roxssana GuardiolaAún no hay calificaciones
- CAPITULO10RHDocumento24 páginasCAPITULO10RHRoxssana GuardiolaAún no hay calificaciones
- Pia Soroxis Equipo10Documento7 páginasPia Soroxis Equipo10Roxssana GuardiolaAún no hay calificaciones
- Actividad Fundamental 1 - A. Com. de Los Met. de Val. de Puestos de Trabajo y Sus Funciones. - Equipo 10Documento8 páginasActividad Fundamental 1 - A. Com. de Los Met. de Val. de Puestos de Trabajo y Sus Funciones. - Equipo 10Roxssana GuardiolaAún no hay calificaciones
- Tarea 3 Estadistica InfDocumento15 páginasTarea 3 Estadistica InfRoxssana GuardiolaAún no hay calificaciones
- Actividad 5 DibujolabDocumento8 páginasActividad 5 DibujolabRoxssana GuardiolaAún no hay calificaciones
- Practica 10Documento5 páginasPractica 10Roxssana GuardiolaAún no hay calificaciones
- Practica 7 LabtgyvDocumento12 páginasPractica 7 LabtgyvRoxssana GuardiolaAún no hay calificaciones
- Características de Las Pruebas de HipótesisDocumento3 páginasCaracterísticas de Las Pruebas de HipótesisRoxssana GuardiolaAún no hay calificaciones
- Actividad 5 DibujolabDocumento8 páginasActividad 5 DibujolabRoxssana GuardiolaAún no hay calificaciones
- Actividad 3 Medicion de Flujo y Presion en El Sistema Hidraulico Segunda ParteDocumento6 páginasActividad 3 Medicion de Flujo y Presion en El Sistema Hidraulico Segunda ParteRoxssana GuardiolaAún no hay calificaciones
- Medición de PresiónDocumento1 páginaMedición de PresiónRoxssana GuardiolaAún no hay calificaciones
- MIV MM Separata PDFDocumento14 páginasMIV MM Separata PDFElizabeth Rengifo FloresAún no hay calificaciones
- EJERCICIOS CAPITULO 10 Pag 347Documento2 páginasEJERCICIOS CAPITULO 10 Pag 347Ana CoronelAún no hay calificaciones
- EA 418 Prueba No Paramétrica de Kruskal-WallisDocumento10 páginasEA 418 Prueba No Paramétrica de Kruskal-WallisJuan CarlosAún no hay calificaciones
- Análisis VarianzaDocumento20 páginasAnálisis VarianzakukiAún no hay calificaciones
- Tecnicas de MuestreoDocumento12 páginasTecnicas de MuestreoDennis Roman Coronado0% (1)
- SXSG EJ23 Proyecto FinalDocumento3 páginasSXSG EJ23 Proyecto FinalorlandoAún no hay calificaciones
- Universidad Nacional "Hermilio Valdizan": Facultad de Ingeniería Industrial Y Sistemas E.P Ingenieria IndustrialDocumento14 páginasUniversidad Nacional "Hermilio Valdizan": Facultad de Ingeniería Industrial Y Sistemas E.P Ingenieria IndustrialAnonymous fYRzAkdpLsAún no hay calificaciones
- TP2 - Minicaso Financial Advisor Inc - Luis BolivarDocumento4 páginasTP2 - Minicaso Financial Advisor Inc - Luis BolivarLuis BolivarAún no hay calificaciones
- MCODocumento34 páginasMCOglpiAún no hay calificaciones
- Proyecto FinalizadoDocumento89 páginasProyecto FinalizadoRicardo VillarrealAún no hay calificaciones
- ProblemasDocumento9 páginasProblemasJose Cabrera RuizAún no hay calificaciones
- (M2-E1) Evaluación (Prueba) - Estadística AplicadaDocumento8 páginas(M2-E1) Evaluación (Prueba) - Estadística AplicadaJENNIFER CORDINIAún no hay calificaciones
- Consulta ANOVADocumento7 páginasConsulta ANOVAViviana Ortiz ArbeláezAún no hay calificaciones
- Disenio ExperimentosDocumento119 páginasDisenio ExperimentosJay Pi100% (2)
- Inf Taller3 Jaime Figueredo PDFDocumento19 páginasInf Taller3 Jaime Figueredo PDFANGIE LORENA GUIO FERNANDEZAún no hay calificaciones
- Programa de Métodos Estadísticos - Universidad Autónoma de Santo DomingoDocumento9 páginasPrograma de Métodos Estadísticos - Universidad Autónoma de Santo DomingoAnnette Viola67% (3)
- Práctica 7Documento2 páginasPráctica 7oscar nevarezAún no hay calificaciones
- Syllabus Del Curso Inferencia Estadística +UNAD 2019 + 212064Documento14 páginasSyllabus Del Curso Inferencia Estadística +UNAD 2019 + 212064Fernando SuarezAún no hay calificaciones
- Pruebas de Hipotesis Con SpssDocumento31 páginasPruebas de Hipotesis Con SpssjoseAún no hay calificaciones
- Docima o Prueba de HipotesisDocumento9 páginasDocima o Prueba de HipotesisCamilo Bustamante SantanderAún no hay calificaciones
- INVESTIGACIONDocumento10 páginasINVESTIGACIONCielito HerreraAún no hay calificaciones
- Datos Enumerativos - Estad. IndustrialDocumento12 páginasDatos Enumerativos - Estad. IndustrialCristian Soto ParionaAún no hay calificaciones
- Pruebas de HipotesisDocumento16 páginasPruebas de HipotesisPaola OrdoñezAún no hay calificaciones
- Analisis de Varianza PDFDocumento79 páginasAnalisis de Varianza PDFMichaelAragonLuqueAún no hay calificaciones
- Negocios y EconomíaDocumento4 páginasNegocios y Economíaisrael lopez ramirezAún no hay calificaciones
- Qué Es La Distribución Chi CuadradaDocumento5 páginasQué Es La Distribución Chi CuadradaBLANCA ESTELA SANTIAGO HERNANDEZAún no hay calificaciones