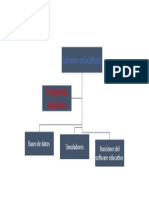
También podría gustarte
- Localizador de Recursos Uniforme URLDocumento5 páginasLocalizador de Recursos Uniforme URLMG EdgarAún no hay calificaciones
- Localizador Uniforme de RecursosDocumento4 páginasLocalizador Uniforme de RecursosLuis Pollo FernandoAún no hay calificaciones
- Localizador de Recursos UniformeDocumento4 páginasLocalizador de Recursos UniformerstandveAún no hay calificaciones
- UrlDocumento3 páginasUrlGala ZavalaAún no hay calificaciones
- Informe URLDocumento3 páginasInforme URLCirJos CedeAún no hay calificaciones
- Localizador de Recursos UniformeDocumento4 páginasLocalizador de Recursos UniformeFranklin GB SayayAún no hay calificaciones
- Url y Urn 4Documento14 páginasUrl y Urn 4Maria del Pilar Peralta AlvarezAún no hay calificaciones
- URLsDocumento6 páginasURLsEfrain SaraviaAún no hay calificaciones
- Tema4 HTTPDocumento15 páginasTema4 HTTPJuan Timoner DomínguezAún no hay calificaciones
- HTTP GuiaDocumento9 páginasHTTP GuiaSnei TorberAún no hay calificaciones
- HTTPDocumento56 páginasHTTPAnaAún no hay calificaciones
- Curso Tallerdeprogramación WebDocumento198 páginasCurso Tallerdeprogramación WebArnoldoCon100% (1)
- Protocolo de Transferencia de HipertextoDocumento7 páginasProtocolo de Transferencia de HipertextoClaudio Xavier BorjaAún no hay calificaciones
- La Arquitectura de Aplicaciones SaasDocumento32 páginasLa Arquitectura de Aplicaciones SaasElvis AndresAún no hay calificaciones
- Servidores HTTPDocumento13 páginasServidores HTTPalanAún no hay calificaciones
- InterconexionDocumento2 páginasInterconexionMarlon AriasAún no hay calificaciones
- 14 03 LECTURA Seguridad en URLDocumento3 páginas14 03 LECTURA Seguridad en URLCRISTIAN DAVID VIASUS VEGAAún no hay calificaciones
- 2.6 WWW HTTP y HttpsDocumento4 páginas2.6 WWW HTTP y HttpsERIKA ASTRID BECERRA MERAZAún no hay calificaciones
- Práctica 1 HTMLDocumento2 páginasPráctica 1 HTMLMario1130 PascualAún no hay calificaciones
- Partes de Una UrlDocumento2 páginasPartes de Una Urlimadot18Aún no hay calificaciones
- 01 - HTML - Guía ProgDocumento44 páginas01 - HTML - Guía ProgMarcos ZiadiAún no hay calificaciones
- Uri HTTP HTMLDocumento9 páginasUri HTTP HTMLMaria del Pilar Peralta AlvarezAún no hay calificaciones
- Evaluación REST PDFDocumento3 páginasEvaluación REST PDFJuanAún no hay calificaciones
- EnsayoDocumento10 páginasEnsayoTom Maverick100% (1)
- Modulo Solicitudes WebDocumento13 páginasModulo Solicitudes WebJakers 4247Aún no hay calificaciones
- Unidad 3 Internet 240811Documento35 páginasUnidad 3 Internet 240811triniaroAún no hay calificaciones
- Tema 05 - API RestDocumento29 páginasTema 05 - API RestMiguel VelizAún no hay calificaciones
- HTTP y Https PDFDocumento15 páginasHTTP y Https PDFJose Leodan Lopez SantosAún no hay calificaciones
- Colegio San Agustín InfoDocumento7 páginasColegio San Agustín InfoAnelisse CentenoAún no hay calificaciones
- S11.s1.-Material ComplementarioDocumento15 páginasS11.s1.-Material ComplementariochristianAún no hay calificaciones
- Lineamientos de Diseño para APIS RESTDocumento9 páginasLineamientos de Diseño para APIS RESTChrisAún no hay calificaciones
- S11 - s1 - Material Complementario - URDYRMDocumento11 páginasS11 - s1 - Material Complementario - URDYRMrenzo anicama masgoAún no hay calificaciones
- Python Modulo 3-211123-103403Documento31 páginasPython Modulo 3-211123-103403andresgia6153Aún no hay calificaciones
- Actividad 1 - ¡Protocolos!Documento19 páginasActividad 1 - ¡Protocolos!Ivan HuertaAún no hay calificaciones
- Parcial de Sistemas DistribuidosDocumento15 páginasParcial de Sistemas DistribuidosYOVER MAYCOL LANAZCA DE LA CRUZAún no hay calificaciones
- Separata HTMLDocumento61 páginasSeparata HTMLArmando Braulio Custodio ChicomaAún no hay calificaciones
- HTTPDocumento14 páginasHTTPMarcelino Barreiro TaboadaAún no hay calificaciones
- Las URL-7° GradoDocumento6 páginasLas URL-7° GradoVictoria GiraltAún no hay calificaciones
- Dominios y URLDocumento3 páginasDominios y URLJesus SánchezAún no hay calificaciones
- Fundamentos Técnicos de InternetDocumento8 páginasFundamentos Técnicos de InternetLuis BelloAún no hay calificaciones
- 01-Introducción A Las Aplicaciones WebDocumento29 páginas01-Introducción A Las Aplicaciones WebJorge VichiAún no hay calificaciones
- st0263 2261 Lab1Documento2 páginasst0263 2261 Lab1Juan martin UribeAún no hay calificaciones
- Que Es Una Red de ComputadoraDocumento7 páginasQue Es Una Red de Computadoralilianabeatriz100% (1)
- Clase 5 - Aplicaciones de RedDocumento19 páginasClase 5 - Aplicaciones de RedSergio CapilleraAún no hay calificaciones
- Los Tres PilaresDocumento2 páginasLos Tres PilaresdiegoAún no hay calificaciones
- Servicios WebDocumento56 páginasServicios WebWes MenaAún no hay calificaciones
- Fundamentos de La Web - URJCDocumento19 páginasFundamentos de La Web - URJCGabriel RubioAún no hay calificaciones
- CuestionarioDocumento12 páginasCuestionarioObrayan K. Huanca MarquezAún no hay calificaciones
- AAAAAAAAAAAAPRACTICA NoDocumento14 páginasAAAAAAAAAAAAPRACTICA NoJhordan Arnold choque palapeAún no hay calificaciones
- Fundamentos de InternetDocumento12 páginasFundamentos de InternetSara SantiagoAún no hay calificaciones
- Partes de Una URLDocumento3 páginasPartes de Una URLvegapujinAún no hay calificaciones
- Actividad de Aprendizaje 2 PDFDocumento12 páginasActividad de Aprendizaje 2 PDFImage ColombiaAún no hay calificaciones
- Conceptos BasicosDocumento7 páginasConceptos BasicosBernardo LopezAún no hay calificaciones
- Fundamentos Básicos Del InternetDocumento11 páginasFundamentos Básicos Del InternetMisy100% (2)
- Qué Es Una URLDocumento7 páginasQué Es Una URLMariela CoradoAún no hay calificaciones
- Laura Loaiza 703Documento3 páginasLaura Loaiza 703jvega_598239Aún no hay calificaciones
- RestDocumento13 páginasRestjrodrimo100% (1)
- Diseño Gráfico ComputarizadoDocumento1 páginaDiseño Gráfico ComputarizadoJosé MéndezAún no hay calificaciones
- 3 ActividadesDocumento3 páginas3 ActividadesAlex EstradaAún no hay calificaciones
- Colegio de Bachilleres de ChipasDocumento21 páginasColegio de Bachilleres de ChipasAlex EstradaAún no hay calificaciones
- Gere AguilarDocumento1 páginaGere AguilarAlex EstradaAún no hay calificaciones
- Ycomomoco 1 JVCGT 90Documento2 páginasYcomomoco 1 JVCGT 90Alex EstradaAún no hay calificaciones
- Dia Mundial de La Alimentacion 2021Documento8 páginasDia Mundial de La Alimentacion 2021Alex EstradaAún no hay calificaciones
- DIAGNOSTICO AMBIENTAL Y FORESTAL DEL ESTADO DE CHIAPASffffffDocumento140 páginasDIAGNOSTICO AMBIENTAL Y FORESTAL DEL ESTADO DE CHIAPASffffffAlex EstradaAún no hay calificaciones
- Libro de ExselDocumento3 páginasLibro de ExselAlex EstradaAún no hay calificaciones
- Sopa de Letras InformáticatzelDocumento1 páginaSopa de Letras InformáticatzelAlex EstradaAún no hay calificaciones
- PresentacióntecoptzeltalDocumento1 páginaPresentacióntecoptzeltalAlex EstradaAún no hay calificaciones
- Definición de Carta PoderDocumento3 páginasDefinición de Carta PoderAlex EstradaAún no hay calificaciones
- NombreDocumento1 páginaNombreAlex EstradaAún no hay calificaciones
- Actividad 3 CotasDocumento1 páginaActividad 3 CotasAlex EstradaAún no hay calificaciones
- Aprender A Programar en C - A. M. Vozmediano PDFDocumento1469 páginasAprender A Programar en C - A. M. Vozmediano PDFjesus100% (3)
- Temas de Introducción A La Programación de Video Juego 123Documento25 páginasTemas de Introducción A La Programación de Video Juego 123Nörmita TadeöAún no hay calificaciones
- Guia Comercio ElectonicoDocumento1 páginaGuia Comercio ElectonicoFabiola Alvarez San JuanAún no hay calificaciones
- Aprovechamiento de La Jerarquía de Memoria: Tema 3Documento31 páginasAprovechamiento de La Jerarquía de Memoria: Tema 3carlos robayoAún no hay calificaciones
- EJERCICIOS DE EXCEL Condicional SIDocumento3 páginasEJERCICIOS DE EXCEL Condicional SIMaite CondarcoAún no hay calificaciones
- Pasos A Seguir DSCDocumento13 páginasPasos A Seguir DSCPeter AguilarAún no hay calificaciones
- B5a 2148 02Documento68 páginasB5a 2148 02Alex ParionaAún no hay calificaciones
- Ataques de HardwareDocumento6 páginasAtaques de HardwareNicollet FriolesAún no hay calificaciones
- Apuntes S1-Lenguaje de Programacion CDocumento20 páginasApuntes S1-Lenguaje de Programacion CLux VitaeAún no hay calificaciones
- Programa de Pico y Placa en C++Documento4 páginasPrograma de Pico y Placa en C++Terry MenaAún no hay calificaciones
- EDR Guia ESDocumento906 páginasEDR Guia ESChemaPitolAún no hay calificaciones
- SOFI 3005 - Mecanografía BásicaDocumento6 páginasSOFI 3005 - Mecanografía BásicaAlfredoAún no hay calificaciones
- Proyecto Final SEMDocumento14 páginasProyecto Final SEMLaura VelandiaAún no hay calificaciones
- Visual C# Programa Arrays For ConsolaDocumento12 páginasVisual C# Programa Arrays For ConsolaDiana Adriana Lovecraft HawthorneAún no hay calificaciones
- Informe Tipos de ComputadorasDocumento9 páginasInforme Tipos de ComputadorasJean Carlos Ramirez Ramirez0% (1)
- Tarea de ModelamientoDocumento5 páginasTarea de ModelamientoMaría Mires cadenillasAún no hay calificaciones
- Práctica X SemáforoDocumento6 páginasPráctica X SemáforoYahir Israel Carrillo HernándezAún no hay calificaciones
- Lenguaje de Programacion Cucho Chambi JohnDocumento14 páginasLenguaje de Programacion Cucho Chambi JohnJohn AntonyAún no hay calificaciones
- Computacion Grado SextoDocumento67 páginasComputacion Grado SextoAdelmo Jose Herazo VergaraAún no hay calificaciones
- TM Krem U3 A3 07Documento4 páginasTM Krem U3 A3 07Méndez PatAún no hay calificaciones
- Laboratorio 15 - Uso de Librerías en Arduino para Salida de DatosDocumento8 páginasLaboratorio 15 - Uso de Librerías en Arduino para Salida de DatosLevi ackermanAún no hay calificaciones
- Guía de Visio 2007 para PrincipiantesDocumento17 páginasGuía de Visio 2007 para Principiantescesamontr2009Aún no hay calificaciones
- Formulario 2 - Modificación de Usuario AdministradorDocumento1 páginaFormulario 2 - Modificación de Usuario Administradorfelix choquehuancaAún no hay calificaciones
- Ventas de Oferta CRM V0.1Documento22 páginasVentas de Oferta CRM V0.1edgardo_salazar_1Aún no hay calificaciones
- ChatbotsDocumento5 páginasChatbotsAndrés M. PosadaAún no hay calificaciones
- Techexpert - Tips-Pfsense - Configuración Del Modelador de TráficoDocumento6 páginasTechexpert - Tips-Pfsense - Configuración Del Modelador de TráficoFederico BarberisAún no hay calificaciones
- Cloud Computing en AnalisisDocumento2 páginasCloud Computing en Analisis11-MH-HU-TREYSI RICSE MAYTAAún no hay calificaciones
- Icsi-Algoyprog - Algoritmos-VbDocumento12 páginasIcsi-Algoyprog - Algoritmos-VbLex Luiggi Angelo Rubio LeccaAún no hay calificaciones
- Respuestas 01Documento5 páginasRespuestas 01miguel espinozaAún no hay calificaciones
- Taller de Derecho Penal EspecialDocumento18 páginasTaller de Derecho Penal EspecialMelissa RuizAún no hay calificaciones