También podría gustarte
- Plantilla Del Plan Mantenimiento SoftwareDocumento8 páginasPlantilla Del Plan Mantenimiento Softwareallison caleisho100% (1)
- Herencia Polimorfismo Tarea 3Documento6 páginasHerencia Polimorfismo Tarea 3Steven Paredes CastilloAún no hay calificaciones
- Diseño BD, Monitoreo, ConsultaDocumento6 páginasDiseño BD, Monitoreo, ConsultaPAUL ‐ECAún no hay calificaciones
- Practica 11 AlexisDocumento10 páginasPractica 11 AlexisPAUL ‐ECAún no hay calificaciones
- Practica 9Documento9 páginasPractica 9PAUL ‐ECAún no hay calificaciones
- Practica 6Documento6 páginasPractica 6PAUL ‐ECAún no hay calificaciones
- Practica 2Documento8 páginasPractica 2PAUL ‐ECAún no hay calificaciones
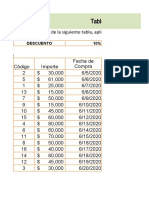
- Ejercicios Porcentajes ExcelDocumento6 páginasEjercicios Porcentajes ExcelDiana Esperanza Botina JojoaAún no hay calificaciones
- AP04 OA ConMerModRel PDFDocumento33 páginasAP04 OA ConMerModRel PDFOscar AcevedoAún no hay calificaciones
- Infórmate Sobre Nuestro Xiaomi Redmi Note 11S 128 GBDocumento1 páginaInfórmate Sobre Nuestro Xiaomi Redmi Note 11S 128 GBderlinAún no hay calificaciones
- Linea Del Tiempo de Los Lenguajes de ProgramaciónDocumento2 páginasLinea Del Tiempo de Los Lenguajes de ProgramaciónMel G.Aún no hay calificaciones
- Presentación ArquitecturaDocumento11 páginasPresentación ArquitecturaWilliam MYAún no hay calificaciones
- Actividad - Modulo 6 MoDocumento4 páginasActividad - Modulo 6 MoMaria CespedezAún no hay calificaciones
- Aguilar - Luis - Fase 2Documento5 páginasAguilar - Luis - Fase 2eduardo aguilarAún no hay calificaciones
- Identificación de La GuíaDocumento9 páginasIdentificación de La Guíajohn garciaAún no hay calificaciones
- VIMEH Formato Resumen ExtendidoDocumento2 páginasVIMEH Formato Resumen ExtendidoDuvan ArteagaAún no hay calificaciones
- Quinto - Actividad 07Documento8 páginasQuinto - Actividad 07KaRl MAún no hay calificaciones
- Capítulo2 - IntroCiberseguridadDocumento10 páginasCapítulo2 - IntroCiberseguridadreneAún no hay calificaciones
- Manual de Tecnicas de Muay Thai PDFDocumento3 páginasManual de Tecnicas de Muay Thai PDFMariano Jalon100% (1)
- Práctica 6 - Combinación de Keil Uvision y Proteus para La Simulación de Sistemas EmpotradosDocumento7 páginasPráctica 6 - Combinación de Keil Uvision y Proteus para La Simulación de Sistemas EmpotradosAdx ForeverAún no hay calificaciones
- 1 - Tema - Introducción, Conceptos BásicosDocumento43 páginas1 - Tema - Introducción, Conceptos BásicosCristian Gomez GalvisAún no hay calificaciones
- Tarea 1 - Alexander - BlanquicettDocumento33 páginasTarea 1 - Alexander - BlanquicettAlexander BlanquicettAún no hay calificaciones
- 1 SecundariaDocumento10 páginas1 SecundariaScarlett OrtegaAún no hay calificaciones
- MFC L6900DWDocumento7 páginasMFC L6900DWMaximiliano QuinciAún no hay calificaciones
- Human Computer InteractionDocumento10 páginasHuman Computer Interactionaxeltapuy2006Aún no hay calificaciones
- Grupo #5 Capítulo 8 Effy Oz Sistemas de Información de Negocios NRC 6503Documento51 páginasGrupo #5 Capítulo 8 Effy Oz Sistemas de Información de Negocios NRC 6503VICTOR HUGO MORALES PULGARINAún no hay calificaciones
- 02 - PPT - Taller - SIAF - AuditoresDocumento44 páginas02 - PPT - Taller - SIAF - AuditoresMiguel DelgadoAún no hay calificaciones
- Marco Teorico Dispensador de Comida AutomatizadoDocumento4 páginasMarco Teorico Dispensador de Comida Automatizadohuchinc72Aún no hay calificaciones
- Diagrama de Gantt CARRO PEDALDocumento3 páginasDiagrama de Gantt CARRO PEDALOsox.BDeathAún no hay calificaciones
- Diapositivas Programacion 28-10-2021Documento17 páginasDiapositivas Programacion 28-10-2021Cesar Muñoz BonettAún no hay calificaciones
- Apuntes InformáticaDocumento15 páginasApuntes InformáticaRaul Moya SanzAún no hay calificaciones
- Programación I - Guía de Práctica S26Documento4 páginasProgramación I - Guía de Práctica S26Jesús G Romero MendozaAún no hay calificaciones
- Evolución Histórica de Los Sistemas OperativosDocumento2 páginasEvolución Histórica de Los Sistemas OperativosJassira Del PilarAún no hay calificaciones
- 9614 555 Diseño Didáctico y Desarrollo de Cursos en LíneaDocumento37 páginas9614 555 Diseño Didáctico y Desarrollo de Cursos en LíneaERWIN ANIBAL CHUB CHUBAún no hay calificaciones
- P-NAR - 0001 Procedimiento de Control de Documentos y RegistrosDocumento13 páginasP-NAR - 0001 Procedimiento de Control de Documentos y RegistrosCRISTIAN MINAUROAún no hay calificaciones