También podría gustarte
- ZAMORA - 2da C Y DDocumento8 páginasZAMORA - 2da C Y DJoseGuayasaminAún no hay calificaciones
- Arroz y ManzanasDocumento7 páginasArroz y ManzanasJoseGuayasaminAún no hay calificaciones
- Parte 2 - RegresionDocumento36 páginasParte 2 - RegresionJoseGuayasaminAún no hay calificaciones
- Análisis de Datos para Lean Six Sigma - Data - Files - DA-LSSDocumento81 páginasAnálisis de Datos para Lean Six Sigma - Data - Files - DA-LSSJoseGuayasaminAún no hay calificaciones
- Análisis estadístico de variables BostonDocumento16 páginasAnálisis estadístico de variables BostonJoseGuayasaminAún no hay calificaciones
- Universidad Técnica Estatal de Quevedo GDPDocumento5 páginasUniversidad Técnica Estatal de Quevedo GDPJoseGuayasaminAún no hay calificaciones
- Parte 2 - RegresionDocumento36 páginasParte 2 - RegresionJoseGuayasaminAún no hay calificaciones
- Tarea - REGRESION LINEAL MULTIPLE - PARTE 2Documento26 páginasTarea - REGRESION LINEAL MULTIPLE - PARTE 2JoseGuayasaminAún no hay calificaciones
- Regulaciones y NormasDocumento17 páginasRegulaciones y NormasJoseGuayasaminAún no hay calificaciones
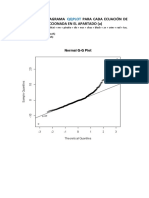
- Elaborar El Diagrama Qqplot para Cada Ecuación de Regresión Seleccionada en El ApartadoDocumento8 páginasElaborar El Diagrama Qqplot para Cada Ecuación de Regresión Seleccionada en El ApartadoJoseGuayasaminAún no hay calificaciones
- Energia Fotovoltaica - InvestigacionDocumento7 páginasEnergia Fotovoltaica - InvestigacionJoseGuayasaminAún no hay calificaciones
- MezcladoraDocumento3 páginasMezcladoraJoseGuayasaminAún no hay calificaciones
- Preguntas - Energias AlternativasDocumento5 páginasPreguntas - Energias AlternativasJoseGuayasaminAún no hay calificaciones
- Unidad 5 - EjerciciosDocumento2 páginasUnidad 5 - EjerciciosJoseGuayasaminAún no hay calificaciones
- Conclusiones Sobre Videos - Productividad y EficienciaDocumento8 páginasConclusiones Sobre Videos - Productividad y EficienciaJoseGuayasaminAún no hay calificaciones
- Preguntas para EfDocumento4 páginasPreguntas para EfJoseGuayasaminAún no hay calificaciones
- Regulaciones y NormasDocumento17 páginasRegulaciones y NormasJoseGuayasaminAún no hay calificaciones
- Orly - Tarea Semana 10Documento4 páginasOrly - Tarea Semana 10JoseGuayasaminAún no hay calificaciones
- DIBUJO P Conjunto - MOREIRADocumento15 páginasDIBUJO P Conjunto - MOREIRAJoseGuayasaminAún no hay calificaciones
- Símbolos de tubería, bombas e instrumentosDocumento1 páginaSímbolos de tubería, bombas e instrumentosJoseGuayasaminAún no hay calificaciones
- Conversion EsDocumento3 páginasConversion EsjoseloAún no hay calificaciones
- Consulta de Frutas y HortalizasDocumento14 páginasConsulta de Frutas y HortalizasJoseGuayasaminAún no hay calificaciones
- Tarea - Semana 9Documento7 páginasTarea - Semana 9JoseGuayasaminAún no hay calificaciones
- Examen FinalDocumento15 páginasExamen FinalJoseGuayasaminAún no hay calificaciones
- Balance de Materia y Energia - WordDocumento7 páginasBalance de Materia y Energia - WordJoseGuayasaminAún no hay calificaciones
- Materia y Su ClasificacionDocumento3 páginasMateria y Su ClasificacionJoseGuayasaminAún no hay calificaciones
- TermometríaDocumento7 páginasTermometríajoseloAún no hay calificaciones
- Peroxidasa PpoDocumento11 páginasPeroxidasa PpoKatherine Cartes EspricauteAún no hay calificaciones
- Enzimas: catalizadores biológicos que aceleran reacciones bioquímicasDocumento8 páginasEnzimas: catalizadores biológicos que aceleran reacciones bioquímicasJoseGuayasaminAún no hay calificaciones
- Paquete Estadístico SASDocumento51 páginasPaquete Estadístico SASRicardo Flores MartinezAún no hay calificaciones
- Estadsitica ProblemaDocumento3 páginasEstadsitica ProblemaJENNIFER PAOLA LLIVIPUMA PAÑIAún no hay calificaciones
- Ejercicios de EstadisticaDocumento11 páginasEjercicios de EstadisticaJulio Os Martinez100% (2)
- Gráfica de Mapa Conceptual Simple Rosa y AzulDocumento1 páginaGráfica de Mapa Conceptual Simple Rosa y AzulMery lariosAún no hay calificaciones
- 4.1.2.4 PR Ctica de Laboratorio Regresi N Lineal Simple en Python 1 PDFDocumento6 páginas4.1.2.4 PR Ctica de Laboratorio Regresi N Lineal Simple en Python 1 PDFCarlos Alberto CelyAún no hay calificaciones
- Tarea Semana 14 - Grupo 3 - Analisis de Regresión IiDocumento25 páginasTarea Semana 14 - Grupo 3 - Analisis de Regresión IiVerónica Garcia RosasAún no hay calificaciones
- Trabajo No. 12 Regresión y CorrelaciónDocumento70 páginasTrabajo No. 12 Regresión y CorrelaciónFlorinda UzAún no hay calificaciones
- Sumillas 2016 1 EstadisticaDocumento4 páginasSumillas 2016 1 EstadisticadiegoAún no hay calificaciones
- Resolución Aind1204 s5 TallerDocumento9 páginasResolución Aind1204 s5 TallerjuanAún no hay calificaciones
- Modelo PolinomicoDocumento9 páginasModelo PolinomicoHarby Noguera Herrera50% (2)
- Mediación y Moderación EstadísticaDocumento51 páginasMediación y Moderación EstadísticaFernando67% (3)
- 2da CLASE 2da PARTEDocumento88 páginas2da CLASE 2da PARTESilvia VegaAún no hay calificaciones
- Estimación de Los Volúmenes y Caudales Máximos Que Produjeron Los Aludes TorrencialesDocumento16 páginasEstimación de Los Volúmenes y Caudales Máximos Que Produjeron Los Aludes TorrencialesPercy RosalesAún no hay calificaciones
- 2.10 Uso Del Coeficiente de Determinacion MultipleDocumento3 páginas2.10 Uso Del Coeficiente de Determinacion MultipleCarlos99991100% (1)
- 1 E2 CálculosProyectoDocumento34 páginas1 E2 CálculosProyectoIrving Rafael Conde MarinAún no hay calificaciones
- Inversiones de Marketing GoodbellyDocumento7 páginasInversiones de Marketing Goodbelly2ramosmanuelAún no hay calificaciones
- Explicando Las Trayectorias de La Embriaguez AdolescenteDocumento23 páginasExplicando Las Trayectorias de La Embriaguez AdolescenteAlejandra Hernandez villotaAún no hay calificaciones
- Proyecto AdoDocumento30 páginasProyecto AdoANGEL ESPINOZA NIETOAún no hay calificaciones
- Tarea 5Documento5 páginasTarea 5yaniAún no hay calificaciones
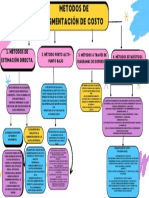
- Métodos para Segmentar Los Costos SemivariablesDocumento27 páginasMétodos para Segmentar Los Costos SemivariablesKarla Zepeda100% (1)
- Pronósticos en Los NegociosDocumento74 páginasPronósticos en Los NegociosJeanGarciaAún no hay calificaciones
- DocxDocumento22 páginasDocxroxjsAún no hay calificaciones
- EXAMEN IoT fUNDAMENTALSDocumento30 páginasEXAMEN IoT fUNDAMENTALSOsmar Barrios100% (3)
- ESTADISTICA CON R Y PYTHON - Ciencia-De-DatosDocumento422 páginasESTADISTICA CON R Y PYTHON - Ciencia-De-DatosEdgar Quintana78% (9)
- Pauta Solemne I Econometrà - A 2018Documento7 páginasPauta Solemne I Econometrà - A 2018Christian LopezAún no hay calificaciones
- Análisis RegresiónDocumento18 páginasAnálisis RegresiónALVARADO JIMENEZ VERONICA VANESSAAún no hay calificaciones
- Parcial 1 Gerencia de ProduccionDocumento16 páginasParcial 1 Gerencia de ProduccionLady GarciaAún no hay calificaciones
- Estructura de Los Metodos Cuantitativos, Variables Y La Influencia de Las ProbabilidadesDocumento13 páginasEstructura de Los Metodos Cuantitativos, Variables Y La Influencia de Las ProbabilidadesJayo Servan MendozaAún no hay calificaciones
- Actividad 2Documento12 páginasActividad 2ELKIN YOHANNY MANRIQUEAún no hay calificaciones
- Tarea 3Documento21 páginasTarea 3Carlos ZetAún no hay calificaciones