También podría gustarte
- Machine Learning Resumen 1 2 3 4 5Documento7 páginasMachine Learning Resumen 1 2 3 4 5Raul TicllacuriAún no hay calificaciones
- Investigación de Machine LearningDocumento3 páginasInvestigación de Machine LearningBrandon AntonioAún no hay calificaciones
- ForoDocumento3 páginasForoCarina MuñozAún no hay calificaciones
- Machine LearningDocumento9 páginasMachine LearningFranklin CoronadoAún no hay calificaciones
- Machine LearningDocumento10 páginasMachine LearningJhon Alexander Ruiz BautistaAún no hay calificaciones
- Que Es Machine LearningDocumento3 páginasQue Es Machine LearningAngie BlancoAún no hay calificaciones
- Big Data Unidad 2Documento34 páginasBig Data Unidad 2urielAún no hay calificaciones
- Tarea 4 Hernan HurtadoDocumento8 páginasTarea 4 Hernan HurtadoHernan HurtadoAún no hay calificaciones
- Montaño Samanta - MACHINE LEARNINGDocumento9 páginasMontaño Samanta - MACHINE LEARNINGSamanta MontañoAún no hay calificaciones
- UntitledDocumento9 páginasUntitledAlejandra RomeroAún no hay calificaciones
- Qué Es La Minería de DatosDocumento9 páginasQué Es La Minería de DatosJunior BarbozaAún no hay calificaciones
- Foro Inteligencia Artificial Innovacion Tecnologica, Ventaja O Amenaza Aprendizaje AutomáticoDocumento3 páginasForo Inteligencia Artificial Innovacion Tecnologica, Ventaja O Amenaza Aprendizaje AutomáticondcharryrAún no hay calificaciones
- Definición de Machine Learning en DetalleDocumento3 páginasDefinición de Machine Learning en DetalleXiomara GaloAún no hay calificaciones
- Técnicas de Aprendizaje AutomatizadoDocumento7 páginasTécnicas de Aprendizaje AutomatizadoCesar CifuentesAún no hay calificaciones
- 04 Aprendizaje AutomáticoDocumento13 páginas04 Aprendizaje AutomáticoCarlos Jose Garcia BecerraAún no hay calificaciones
- ¿Qué Es Machine Learning - CleverdataDocumento8 páginas¿Qué Es Machine Learning - CleverdataJhonGonzalezAún no hay calificaciones
- Tarea 1 (Ensayo Ciencia de Datos)Documento9 páginasTarea 1 (Ensayo Ciencia de Datos)Kevin Joel Zambrano LucasAún no hay calificaciones
- TALLERDocumento6 páginasTALLERKoner PaulAún no hay calificaciones
- Machine LearningDocumento10 páginasMachine Learningvictor CastilloAún no hay calificaciones
- Data ScienceDocumento8 páginasData ScienceJeremy HolguinAún no hay calificaciones
- PRONÓSTICOSDocumento11 páginasPRONÓSTICOSJOSE DAVID P007Aún no hay calificaciones
- Machine LearningDocumento2 páginasMachine LearningSANTIAGO ALBERTO CORTAZAR PALOMEQUEAún no hay calificaciones
- Mineria de DatosDocumento56 páginasMineria de DatosZerginho MuñozAún no hay calificaciones
- Exposicion Sistemas CorregidoDocumento10 páginasExposicion Sistemas CorregidoEvelyn AgilaAún no hay calificaciones
- El Futuro de La Estadística Beatriz GarcíaDocumento6 páginasEl Futuro de La Estadística Beatriz GarcíaBeatriz García Peña100% (1)
- Investigacion MLDocumento9 páginasInvestigacion MLJulia MariaAún no hay calificaciones
- Exp Comunicacion OrganizacionalDocumento3 páginasExp Comunicacion Organizacionalpaula zambranoAún no hay calificaciones
- Dgam 2023 - M4Documento34 páginasDgam 2023 - M4pepe copiapoAún no hay calificaciones
- Consulta P1 - Tareas en Minería de DatosDocumento13 páginasConsulta P1 - Tareas en Minería de DatosJANARA ASLEHY GARCIA FUENTESAún no hay calificaciones
- eGuDDnGboRY7jPb7 - odM-KkgbPBkUGnoc-Algoritmos de Aprendizaje Automático Supervisados y No SupervisadosDocumento5 páginaseGuDDnGboRY7jPb7 - odM-KkgbPBkUGnoc-Algoritmos de Aprendizaje Automático Supervisados y No SupervisadoshaganjazzAún no hay calificaciones
- Inteligencia ArtificialDocumento7 páginasInteligencia ArtificialChristopher MortumAún no hay calificaciones
- GUIA GRATUITA. Machine Learning. Por Donde EmpiezoDocumento19 páginasGUIA GRATUITA. Machine Learning. Por Donde EmpiezoJuan Nieves Saavedra100% (8)
- Taller 1Documento3 páginasTaller 1LUZ KARIME ARIAS TOROAún no hay calificaciones
- Aprendizaje AutomaticoDocumento4 páginasAprendizaje AutomaticoStephania LuciaAún no hay calificaciones
- Las IADocumento7 páginasLas IAAngel gabriel gonzalezAún no hay calificaciones
- Fundamentos y Aplicaciones de Mineria de DatosDocumento67 páginasFundamentos y Aplicaciones de Mineria de Datossteven perezAún no hay calificaciones
- Que Es La Ciencia de DatosDocumento9 páginasQue Es La Ciencia de DatoscesargmxAún no hay calificaciones
- Articulo de InvestigacionDocumento15 páginasArticulo de InvestigacionMAURICIO LAGUNA MARTINEZ0% (1)
- Desarrollo de Inteligencias ArtificialesDocumento19 páginasDesarrollo de Inteligencias Artificialesgilda malimbernoAún no hay calificaciones
- Machine Learning. (2017) Fuente en Línea-CleverDataDocumento35 páginasMachine Learning. (2017) Fuente en Línea-CleverDataanthony10988Aún no hay calificaciones
- Tecnicas de Machine LearningDocumento2 páginasTecnicas de Machine LearningPedro Cesar Solorzano ArayAún no hay calificaciones
- Sistemas ExpertosDocumento12 páginasSistemas ExpertosalbertoAún no hay calificaciones
- MCOM2 U2 A1 IIIIDocumento4 páginasMCOM2 U2 A1 IIIIIker BravoAún no hay calificaciones
- Informe Aprendizaje AutomaticoDocumento4 páginasInforme Aprendizaje AutomaticoLester OjedaAún no hay calificaciones
- Inteligencia Artificial en La Gestión de RiesgosDocumento9 páginasInteligencia Artificial en La Gestión de RiesgosKENDAL ARAMIS TUL GONZALEZAún no hay calificaciones
- La Inteligencia Artificial Test 2Documento2 páginasLa Inteligencia Artificial Test 2Juan RoncancioAún no hay calificaciones
- Examen de InfoDocumento13 páginasExamen de InfoDania LopezAún no hay calificaciones
- Google CloudDocumento12 páginasGoogle CloudAntonio MartinezAún no hay calificaciones
- Machine Learning para Gestión Del Talento HumanoDocumento6 páginasMachine Learning para Gestión Del Talento HumanoKenji MucchingAún no hay calificaciones
- HtasDocumento4 páginasHtasluzdiazochagaviaAún no hay calificaciones
- I7725 - 2022B UN 1 AC 1 Ejemplos de Analisis de InformacionDocumento7 páginasI7725 - 2022B UN 1 AC 1 Ejemplos de Analisis de InformacionJaasiel Alejandro Castellanos GomezAún no hay calificaciones
- Aprendizaje AutomaticoDocumento4 páginasAprendizaje AutomaticoLaura AguileraAún no hay calificaciones
- Qué Son Los Modelos PredictivosDocumento5 páginasQué Son Los Modelos PredictivosKENDAL ARAMIS TUL GONZALEZAún no hay calificaciones
- Algortca LaboralDocumento30 páginasAlgortca LaboralLeticia FragaAún no hay calificaciones
- Minería de DatosDocumento19 páginasMinería de DatosRolando_alone666Aún no hay calificaciones
- Machine LearningDocumento4 páginasMachine LearningSalmista Yudelka De leónAún no hay calificaciones
- Big DataDocumento12 páginasBig DataFranklin NavarreteAún no hay calificaciones
- Unidad 4Documento15 páginasUnidad 4Gabby GuerraAún no hay calificaciones
- Imprimible UNIDAD 2Documento29 páginasImprimible UNIDAD 2Damian CorapiAún no hay calificaciones
- Rapid MinerDocumento5 páginasRapid MinerGibran TurbiAún no hay calificaciones
- Tarea DatawareHouseDocumento2 páginasTarea DatawareHouseGibran TurbiAún no hay calificaciones
- Desarrolle Una Breve Descripción Sobre El Proceso ETL y Sus Principales CaracterísticasDocumento2 páginasDesarrolle Una Breve Descripción Sobre El Proceso ETL y Sus Principales CaracterísticasGibran TurbiAún no hay calificaciones
- Dilemas, Modulo 2 PDFDocumento3 páginasDilemas, Modulo 2 PDFGibran TurbiAún no hay calificaciones
- Proceso ETLDocumento5 páginasProceso ETLGibran TurbiAún no hay calificaciones
- Auditoria - Trabajo Grupal PDFDocumento10 páginasAuditoria - Trabajo Grupal PDFGibran TurbiAún no hay calificaciones
- Humanae Vitae, Una Encí - Clica ProféticaDocumento8 páginasHumanae Vitae, Una Encí - Clica ProféticaGibran TurbiAún no hay calificaciones
- Practica Final de Programacion III Ciclo 2-2020 PDFDocumento2 páginasPractica Final de Programacion III Ciclo 2-2020 PDFGibran TurbiAún no hay calificaciones
- Auditoria Informatica Tema 4 - PracticaDocumento3 páginasAuditoria Informatica Tema 4 - PracticaGibran TurbiAún no hay calificaciones
- Principales Pruebas y Herramientas para Efectuar Una Auditoria InformaticaDocumento7 páginasPrincipales Pruebas y Herramientas para Efectuar Una Auditoria InformaticaGibran TurbiAún no hay calificaciones
- Autenticidad e IdentidadDocumento1 páginaAutenticidad e IdentidadGibran TurbiAún no hay calificaciones
- El Matrimonio (Script)Documento1 páginaEl Matrimonio (Script)Gibran TurbiAún no hay calificaciones
- Portada - Tarea de Servicio Al ClienteDocumento5 páginasPortada - Tarea de Servicio Al ClienteMichel alejandra Pineda caballeroAún no hay calificaciones
- Copia de MandanteDocumento34 páginasCopia de MandanteRicardo MendozaAún no hay calificaciones
- 9 - Formato Autorización Tratamiento de DatosDocumento1 página9 - Formato Autorización Tratamiento de DatosLiz DiazAún no hay calificaciones
- Ficheros PythonDocumento21 páginasFicheros PythonDanny GibsonAún no hay calificaciones
- Evidencia 2 Servicio SocialDocumento3 páginasEvidencia 2 Servicio SocialdanielmercadoiqAún no hay calificaciones
- TP1 PLC 2020Documento3 páginasTP1 PLC 2020Sebastian AmadoAún no hay calificaciones
- El Archivo Tema 1Documento12 páginasEl Archivo Tema 1Evelyn colque mamaniAún no hay calificaciones
- Aporte A La Entrega Final de Sistemas de Información Entrega 3Documento5 páginasAporte A La Entrega Final de Sistemas de Información Entrega 3Visi NincoAún no hay calificaciones
- El PLLDocumento12 páginasEl PLLLeo PilaresAún no hay calificaciones
- Matisse CompletoDocumento9 páginasMatisse CompletoGamaliel VenturaAún no hay calificaciones
- Cce-Gdo-Idi-01 Modelo Requisitos Gestion Documentos Electronicos Moreq CceDocumento24 páginasCce-Gdo-Idi-01 Modelo Requisitos Gestion Documentos Electronicos Moreq CceVianey BustosAún no hay calificaciones
- Folletos de PCDocumento2 páginasFolletos de PCEliasFragozoRuizAún no hay calificaciones
- Hoja de Vida - Tirso RodríguezDocumento6 páginasHoja de Vida - Tirso RodríguezTirso W. RodríguezAún no hay calificaciones
- El Conjunto de Mecanismos Que Componen El Sistema de Dirección Tienen La Misión de Orientar Las Ruedas Delanteras para Que El Vehículo Tome La Trayectoria Deseada Por El ConductorDocumento12 páginasEl Conjunto de Mecanismos Que Componen El Sistema de Dirección Tienen La Misión de Orientar Las Ruedas Delanteras para Que El Vehículo Tome La Trayectoria Deseada Por El Conductoredwin0% (1)
- ProVision Loader Flyer Spanish A4 PDFDocumento2 páginasProVision Loader Flyer Spanish A4 PDFcristian casanova diazAún no hay calificaciones
- Planeación Capital PDFDocumento5 páginasPlaneación Capital PDFBryan OnofreAún no hay calificaciones
- Monografia RaeeDocumento19 páginasMonografia RaeeMariafé DanielaAún no hay calificaciones
- TDA LinkedListDocumento2 páginasTDA LinkedListJean TelloAún no hay calificaciones
- Informe de Avance PIDocumento13 páginasInforme de Avance PISamuel JiménezAún no hay calificaciones
- Diferencia Entre Un Archivo Raster y Un Archivo VectorialDocumento12 páginasDiferencia Entre Un Archivo Raster y Un Archivo VectorialCristhianMarianoChavezSotoAún no hay calificaciones
- Guia de Labo Digitales Nº3Documento2 páginasGuia de Labo Digitales Nº3Diego Ambar AvilaAún no hay calificaciones
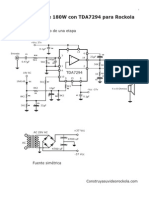
- Tda7294 RockolaDocumento12 páginasTda7294 RockolaFederico SesinAún no hay calificaciones
- Manual de LatexDocumento79 páginasManual de LatexMayra Paola MendezAún no hay calificaciones
- Concepto Diferencial Interpretación Geométrica de Las DiferencialesDocumento1 páginaConcepto Diferencial Interpretación Geométrica de Las DiferencialesBryan TqAún no hay calificaciones
- Pract N2 Elt 3712Documento2 páginasPract N2 Elt 3712Rolando Edgar Pairumani MedranoAún no hay calificaciones
- Desarrollo en Dynamics AX 2012 Jose Antonio Estevan Krasis Press Scribd PDFDocumento58 páginasDesarrollo en Dynamics AX 2012 Jose Antonio Estevan Krasis Press Scribd PDFcarlosvicunav0% (1)
- Digitalizacion Con Microstation de Planos Y MapasDocumento2 páginasDigitalizacion Con Microstation de Planos Y MapasLlsst LlsstAún no hay calificaciones
- ENSAYO LECTO-ESCRITURA TIC'sDocumento2 páginasENSAYO LECTO-ESCRITURA TIC'sYanet Padilla SuàrezAún no hay calificaciones
- Pascal 08Documento8 páginasPascal 08anon-485985100% (1)
- Ejemplo de Tesis CorrelacionalDocumento19 páginasEjemplo de Tesis Correlacionalverner salcedoAún no hay calificaciones